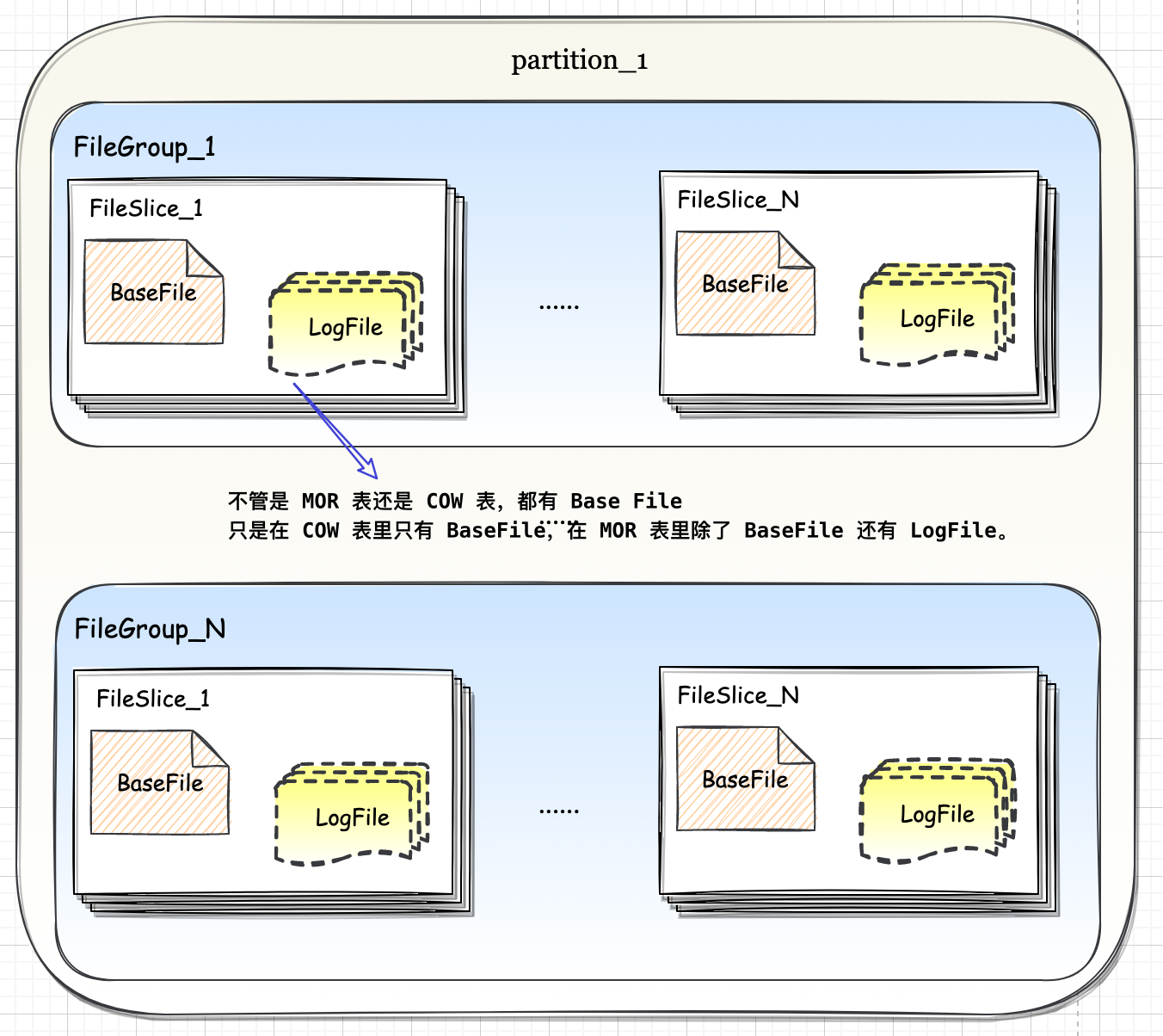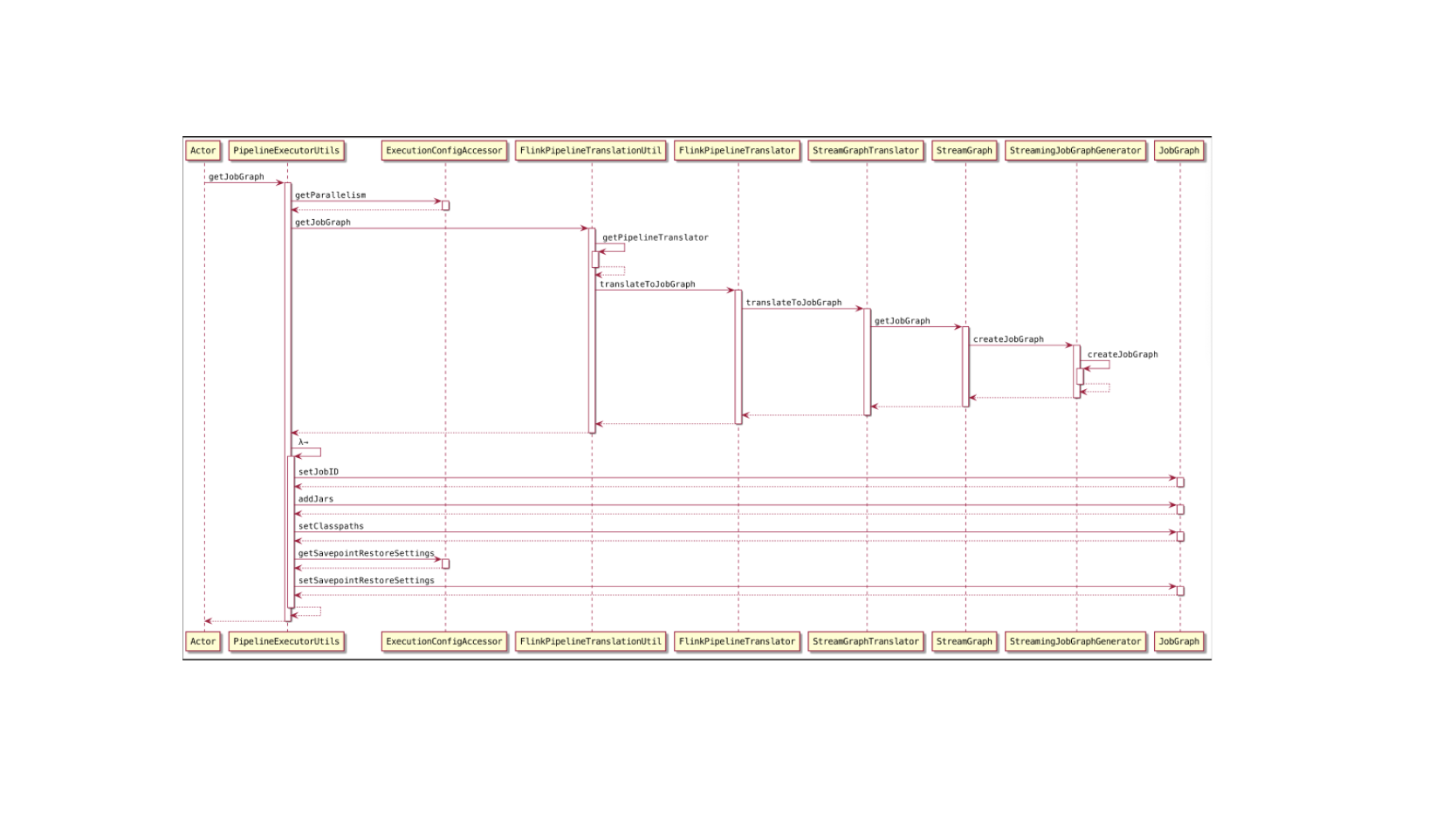
Flink-源码学习-Job 提交-Graph 演变-JobGraph 构建
JobGraph 数据结构在本质上是将节点和中间结果集相连得到有向无环图。JobGraph 是客户端和运行时之间进行作业提交使用的统一数据结构,不管是流式 (StreamGraph) 还是批量 (OptimizerPlan),最终都会转换成集群接受的 JobGraph 数据结构。
一、概述StreamGraph 经过优化后生成了 JobGraph,提交给 JobManager 的数据结构它包含的主要抽象概念有:
Jobvertex
经过优化后符合条件的多个 StreamNode 可能会 chain 在一起生成一个 Jobvertex, 即一个 JobVertex 包含一个或多个 operator, JobVertex 的输入是 JobEdge,输出是 IntermediateDataSet。
IntermediateDataSet
表示 JobVertex 的输出,即经过 operator 处理产生的数据集。producer 是 Jobvertex, consumer 是 JobEdge
JobEdge
代表了job graph中的一条数据传输通道。sour ...

Flink-系列
一、概述Apache Flink 是一个针对无界和有界数据流进行有状态计算的框架。Flink 自底向上在不同的抽象级别提供了多种 API,并且针对常见的使用场景开发了专用的扩展库,能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
二、学习笔记
引用本站文章
Flink-理论笔记系列
Joker
三、源码学习
引用本站文章
Flink-源码学习系列
Joker
四、大厂分享
引用本站文章
...
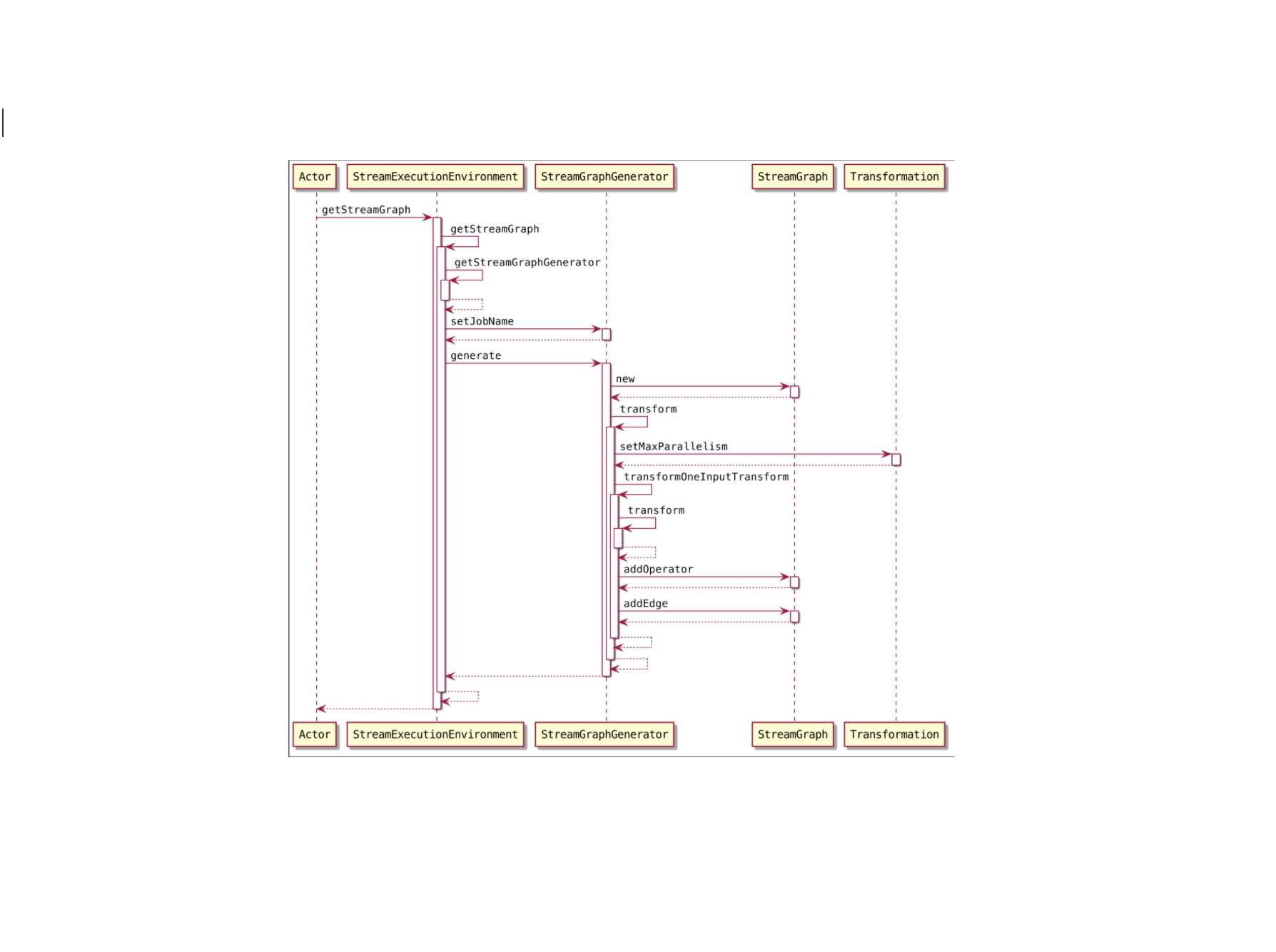
Flink-源码学习-Job 提交-Graph 演变-StreamGraph 构建
根据用户通过 Stream API 编写的代码,从 Source 节点开始,每一次 transform 生成一个 StreamNode,两个 StreamNode 通过 StreamEdge 连接在一起,形成 DAG
StreamNode 用来代表 operator 的类,并具有所有相关的属性,如并发度、入边和出边等。
StreamEdge表示连接两个StreamNode的边。
当客户端调用 StreamExecution Environment.execute() 方法执行应用程序代码时,就会通过 StreamExecutionEnvironment 中提供的方法生成StreamGraph 对象。StreamGraph 结构描述了作业的逻辑拓扑结构,并以有向无环图的形式描述作业中算子之间的上下游连接关系。下面来看StreamGraph的底层实现及构建过程~~~
一、概述StreamGraph 结构是由 StreamGraphGenerator 通过 Transformation 集合转换而来的,StreamGraph 实现了Pipeline的接口,且通过有向无环图的结 ...
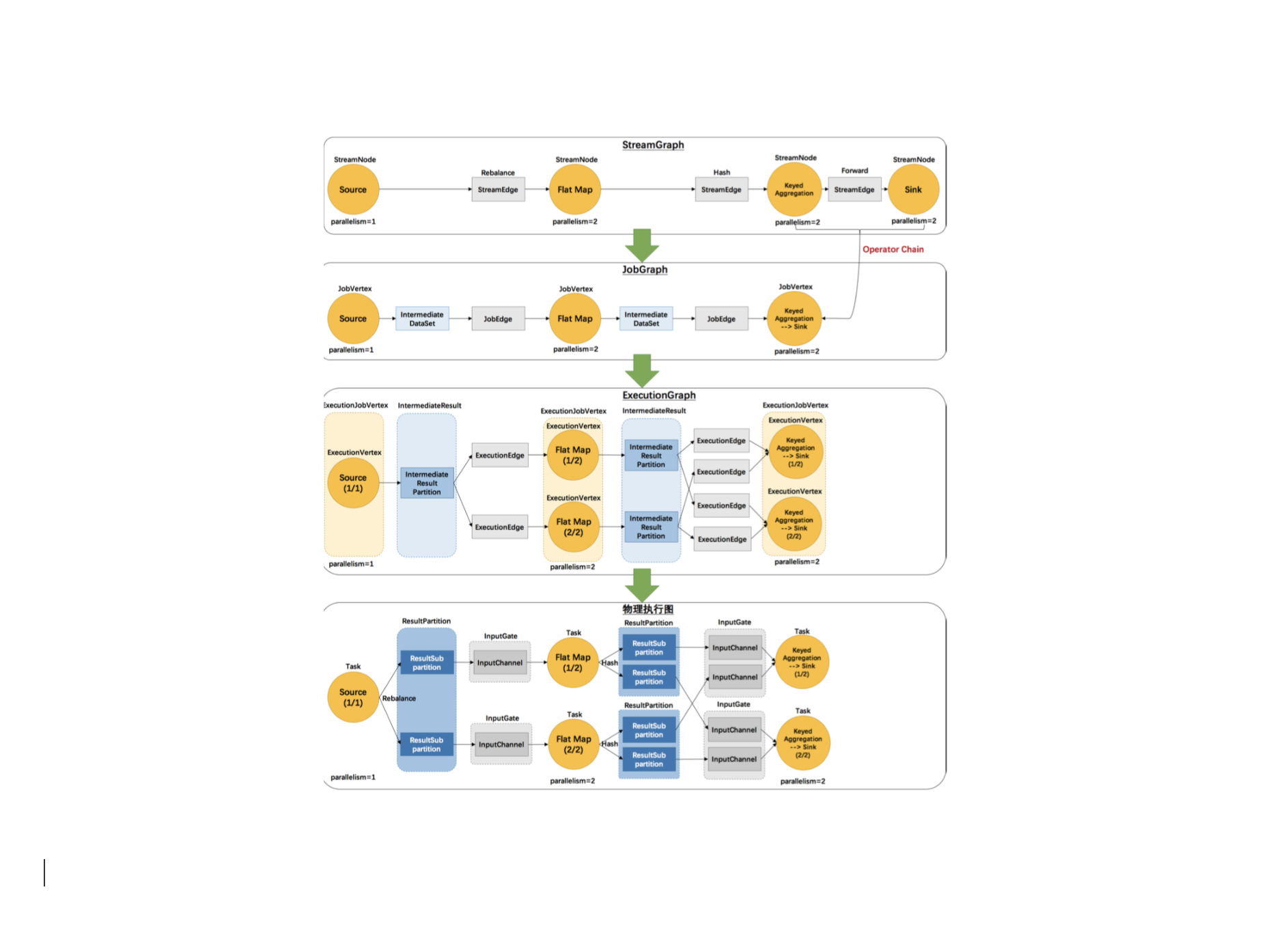
Flink-源码学习-Job 提交-Graph 演变
一个 Flink 流式作业,从 Client 提交到 Flink 集群,到最后执行,总共会经历四种不同的状态。总的来说:
Client 首先根据用户编写的代码生成 StreamGraph,然后把 StreamGraph 构建成 JobGraph 提 交给 Flink 集群主节点
然后启动的 JobMaster 在接收到 JobGraph 后,会对其进行并行化生成 ExecutionGraph 后调度 启动 StreamTask 执行。
StreamTask 并行化的运行在 Flink 集群,就是最终的物理执行图状态结构。
一、概述Flink 中的执行图可以分成四层:StreamGraph ==> JobGraph ==> ExecutionGraph ==> 物理执行图。
StreamGraph
根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
JobGraph
StreamGraph 经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起 ...
Spark-源码学习-SparkSession-ShareState-CacheManager
一、概述在Spark中,SQL缓存是重复使用某些计算的常用技术。它有可能加快使用相同数据的其他查询的速度,但如果我们想获得良好的性能,有一些注意事项需要牢记。
CacheManager 是 Spark SQL 中内存缓存的管理者,在 Spark SQL 中提供对缓存查询结果的支持,并在执行后续查询时自动使用这些缓存结果。数据使用 InMemoryRelation 中存储的字节缓冲区进行缓存。CacheManager 通过 SharedState 在 SparkSessions 之间共享。
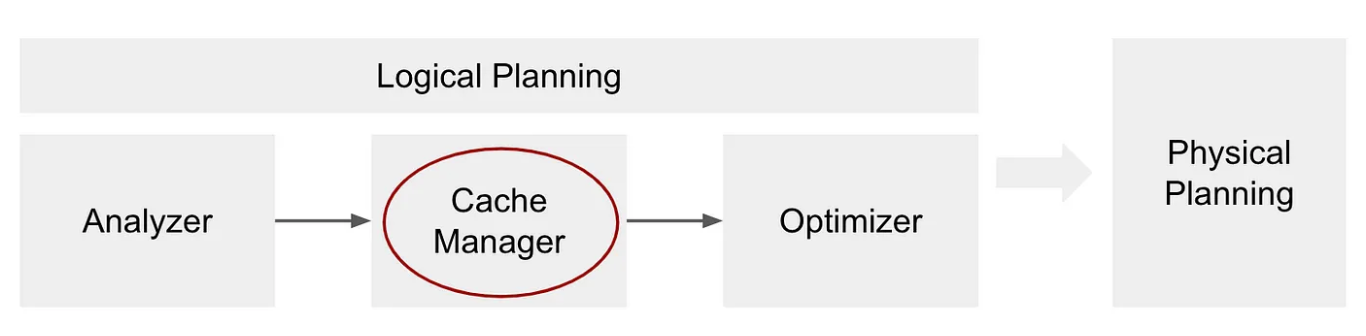
二、设计CacheManager 负责跟踪查询计划中已经缓存的计算。当 $cache()$ 被调用时,CacheManager 会在引擎盖下被直接调用,它会调出缓存函数被调用的DataFrame的分析逻辑计划,并将该计划存储在名为 cachedData 的索引序列中。
缓存管理器阶段是逻辑规划的一部分,它发生在分析器之后,优化器之前:
https://towardsdatascience.com/best-practices-for-caching-in-spark-sql-b22fb0f02d ...
Flink-源码学习-Job 提交-Slot 申请
正在总结中,等我😭~~~
Flink-源码学习-Job 提交-Slot 释放
正在总结中,等我😭~~~
Flink-源码学习-Job 提交-提交脚本解析
Flink Job 提交脚本解析当编写好 Flink 的应用程序,正常的提交方式为:打成jar包,通过 flink 命令来进行提交。
flink 命令脚本的底层,是通过 java 命令启动:CliFrontend 类 来启动 JVM 进程执行任务的构造和提 交。
1flink run xxx.jar class arg1 arg2
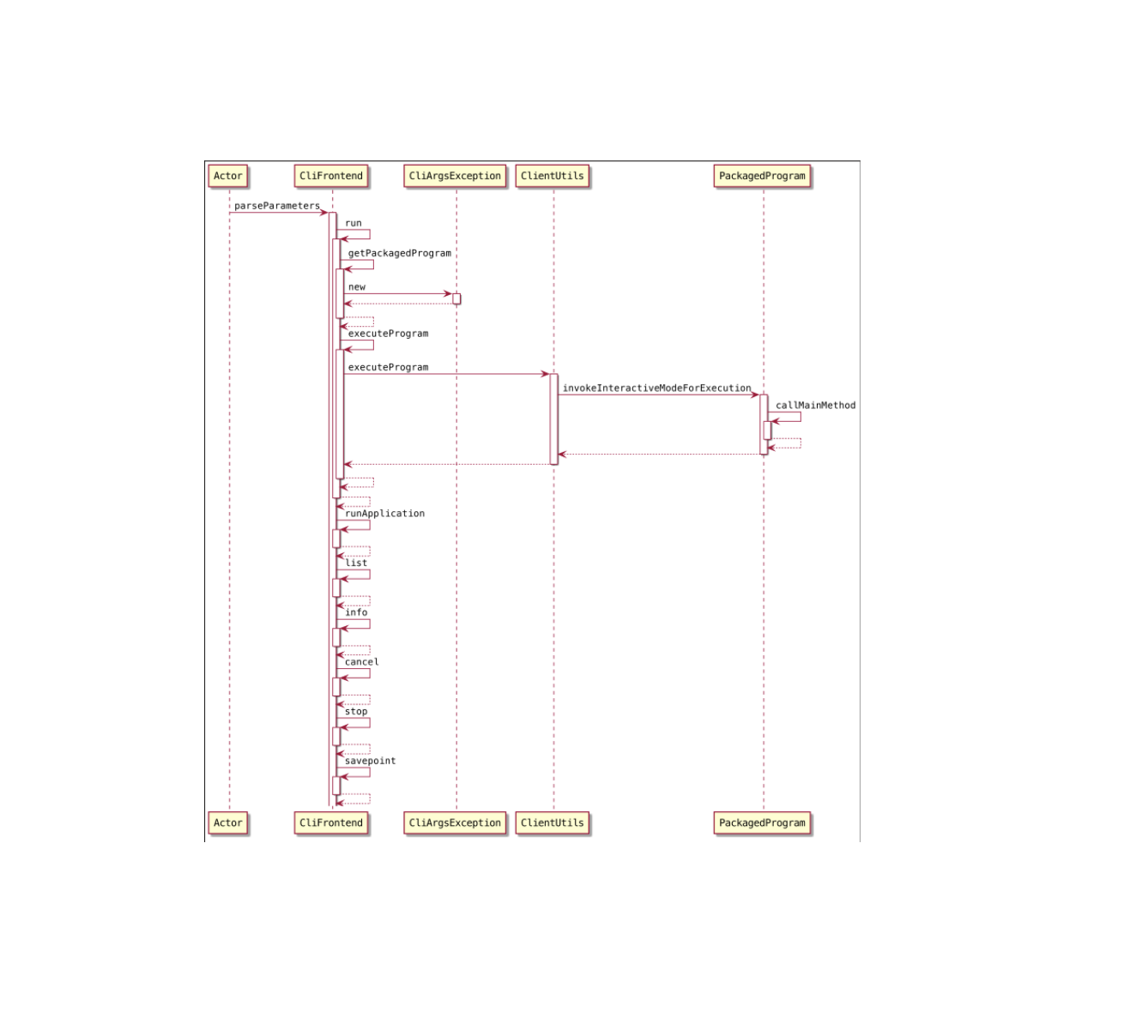
CliFrontend 提交分析当用户把 Flink 应用程序打成 jar 使用 flink run … 的 shell 命令提交的时候,底层是通过 CliFrontend 来处理。底层的逻辑,**就是通过反射来调用用户程序的 main() 方法执行。**
在刚组建内部,主要有以下几件事要做:
根据 flink 后面的执行命令来确定执行方法(run ==> run(params))
解析 main 参数,构建 PackagedProgram,然后执行 PackagedProgram
通过反射获取应用程序的 main 方法的实例,通过反射调用执行起来
总的来说,就是准备执行 Program 所需要的配置,jar包,运行主类等的必要的信 ...
Flink-源码学习-Job 提交-架构设计
当编写好 Flink 的应用程序,正常的提交方式为:打成jar包,通过 flink 命令来进行提交。flink 命令脚本的底层,是通过 java 命令启动:CliFrontend 类 来启动 JVM 进程执行任务的构造和提交。
一、概述当用户构建好 Flink 应用程序后,会在客户端运行 StreamExecutionEnvironment.execute() 方 法生 成 StreamGraph 对象,并将StreamGraph 通过 PipelineExecutor 提交到远程集群中执行。在这个过程中,首先会通过 DataStream API 生成 Transformation转换集合;然后基于 Transformation 转换集合构建 Pipeline 的实现类,也就是 StreamGraph 数据结构;最后再通过PipelineExecutor 将 StreamGraph 转换为 JobGraph 数据结构,并将 JobGraph 提交到集群中运行。
二、提交脚本解析三、源码当编写好 Flink 的应用程序,正常的提交方式为:打成jar包,通过 flink 命令来进行提交 ...
Spark-源码学习-SparkSession-ShareState
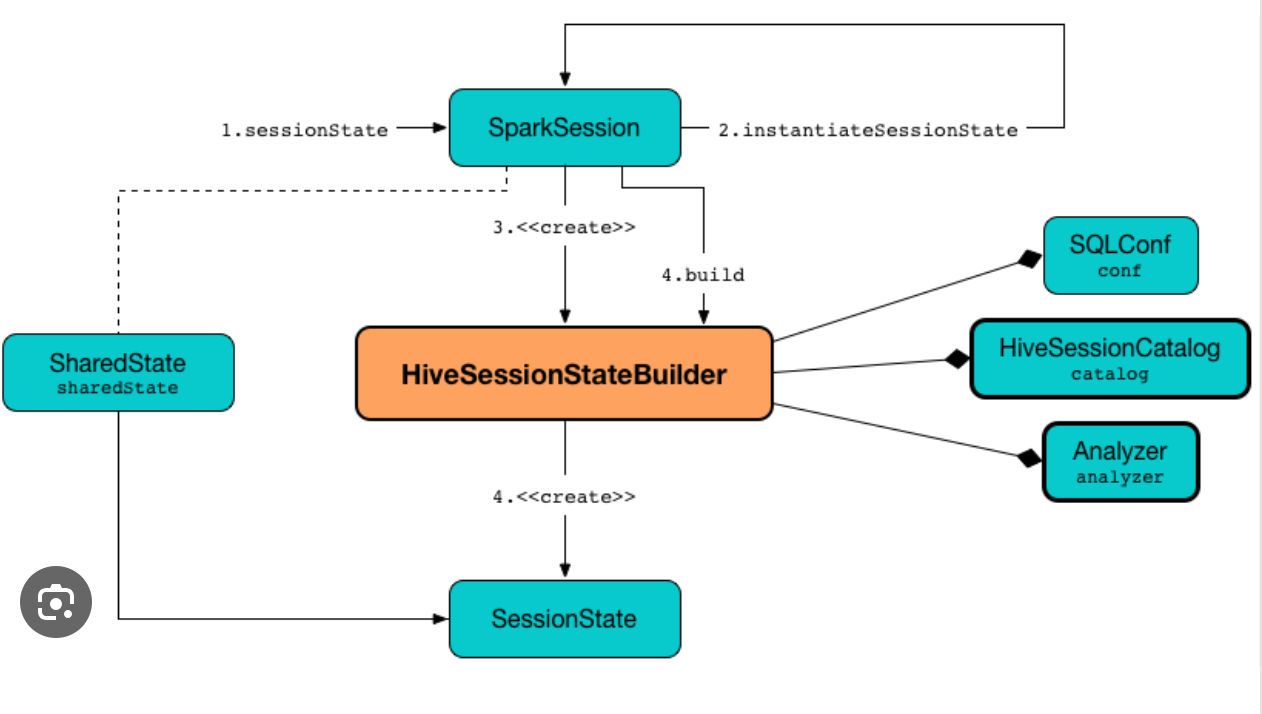
一、概述ShareState 负责保存多个有效 session 之间的共享状态。SharedState 中包含变量: warehousePath、cacheManager、statusStore、externalCatalog、globalTempViewManager、jarClassLoader。这些变量对于所有的 SparkSession 都是公用的。
二、初始化123lazy val sharedState: SharedState = { existingSharedState.getOrElse(new SharedState(sparkContext, initialSessionOptions))}
综上可以看出,SparkSession 重用 sharedState,但是会新 $clone$ 或者创建新的 sessionState,但是如果在创建多个 SparkSession 时,传入的 existingSharedState 都为空,则多个 SparkSession 也会创建多个 sharedState。
2.1. 解析和处理 S ...
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.