Flink-源码学习-Job 提交-架构设计
当编写好 Flink 的应用程序,正常的提交方式为:打成jar包,通过 flink 命令来进行提交。flink 命令脚本的底层,是通过 java 命令启动:CliFrontend 类 来启动 JVM 进程执行任务的构造和提交。
一、概述
当用户构建好 Flink 应用程序后,会在客户端运行 StreamExecutionEnvironment.execute() 方 法生 成 StreamGraph 对象,并将
StreamGraph 通过 PipelineExecutor 提交到远程集群中执行。在这个过程中,首先会通过 DataStream API 生成 Transformation转换集合;然后基于 Transformation 转换集合构建 Pipeline 的实现类,也就是 StreamGraph 数据结构;最后再通过
PipelineExecutor 将 StreamGraph 转换为 JobGraph 数据结构,并将 JobGraph 提交到集群中运行。
二、提交脚本解析
三、源码
当编写好 Flink 的应用程序,正常的提交方式为:打成jar包,通过 flink 命令来进行提交。flink 命令脚本的底层,是通过 java 命令启动:CliFrontend 类 来启动 JVM 进程执行任务的构造和提交。
1 | flink run xxx.jar class arg1 arg2 |
Flink 脚本
1 | exec $JAVA_RUN "$JVM_ARGS" "$FLINK_ENV_JAVA_OPTS" "${log_setting[@]}" -classpath "$(manglePathList "$CC_CLASSPATH:$INTERNAL_HADOOP_CLASSPATHS")" org.apache.flink.client.cli.CliFrontend "$@" |
这个脚本执行完了之后,最终就会跳转到 CliFrontend 类的 main() 方法
3.1. 打印输出环境信息
1 | EnvironmentInformation.logEnvironmentInfo(LOG, "Command Line Client", args); |
3.2. 解析 flink-conf.yaml
3.2.1. 找到 conf 目录
通过 FLINK_CONF_DIR 变量找到 conf 目录
1 | final String configurationDirectory = getConfigurationDirectoryFromEnv(); |
3.2.2. 解析 conf 目录下的 flink-conf.yaml 配置文件
配置有两个来源。
- main() 方法的参数。
flink-conf.yaml配置文件当中的一些配置信息。
main 方法的参数是 args ,一般来说在提交应用程序的时候,flink-conf.yaml 文件当中的一些配置对 job 会有影响,同时在提交应用程序的时候,也会指定各种参数。那么最终我们都会把它解析到一起来
1 | final Configuration configuration = GlobalConfiguration.loadConfiguration(configurationDirectory); |
3.3. 加载自定义命令参数
1 | final List<CustomCommandLine> customCommandLines = loadCustomCommandLines(configuration, configurationDirectory); |
3.4. 初始化 CliFrontend
1 | final CliFrontend cli = new CliFrontend(configuration, customCommandLines); |
3.5. 运行
解析命令行并并开始请求操作
1 | int retCode = SecurityUtils.getInstalledContext().runSecured(() -> cli.parseParameters(args)); |
3.5.1. 参数处理
检查参数的长度
获取 action 参数,如:flink run 命令中的 run 命令
1
String action = args[0];
我们可以通过
flink这个命令来执行 run 、stop 、list 等等,在提交一个 job 时的 action 是 run,如果通过 flink run 提交一个 job,最终通过 run() 的方法来提交。从所有参数中,移除 action 参数
1
final String[] params = Arrays.copyOfRange(args, 1, args.length);
3.5.2. run()
解析参数
把命令行的参数,方法的参数,还有之前的 configuration 等的那个参数合并
1
final CommandLine commandLine = getCommandLine(commandOptions, args, true);
构建 PackagedProgram
PackagedProgram 结构包含应用程序能够运行的全部信息,如.jar文件、任务参数、mainClass等。基于 PackagedProgram 可以打包用户提交的作业,构建作业执行的本地环境,主要是将该作业的依赖包加载至 UserClassLoader中。通过
PackagedProgram 在客户端进程内运行作业代码逻辑,并从作业中将JobGraph信息抽取出来,最后将JobGraph提交到集群中运行。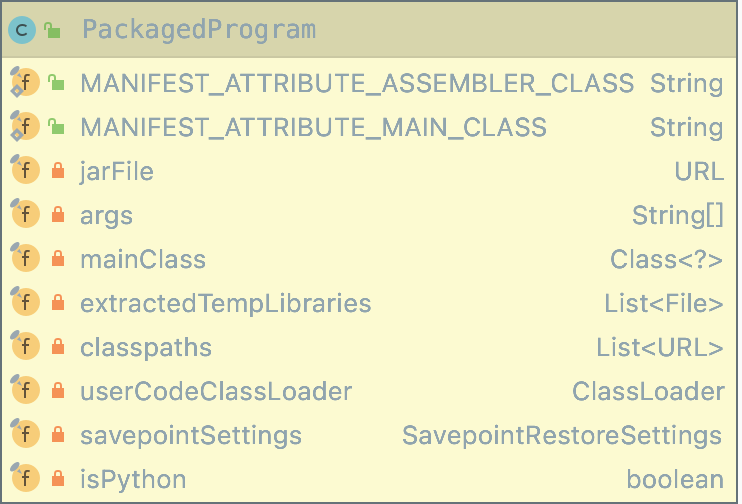
1
2final ProgramOptions programOptions = ProgramOptions.create(commandLine);
final PackagedProgram program = getPackagedProgram(programOptions);依赖 jar 处理
1
final List<URL> jobJars = program.getJobJarAndDependencies();
执行
调用 executeProgram() 方法执行PackagedProgram中的作业程序。
1
executeProgram(effectiveConfiguration, program);
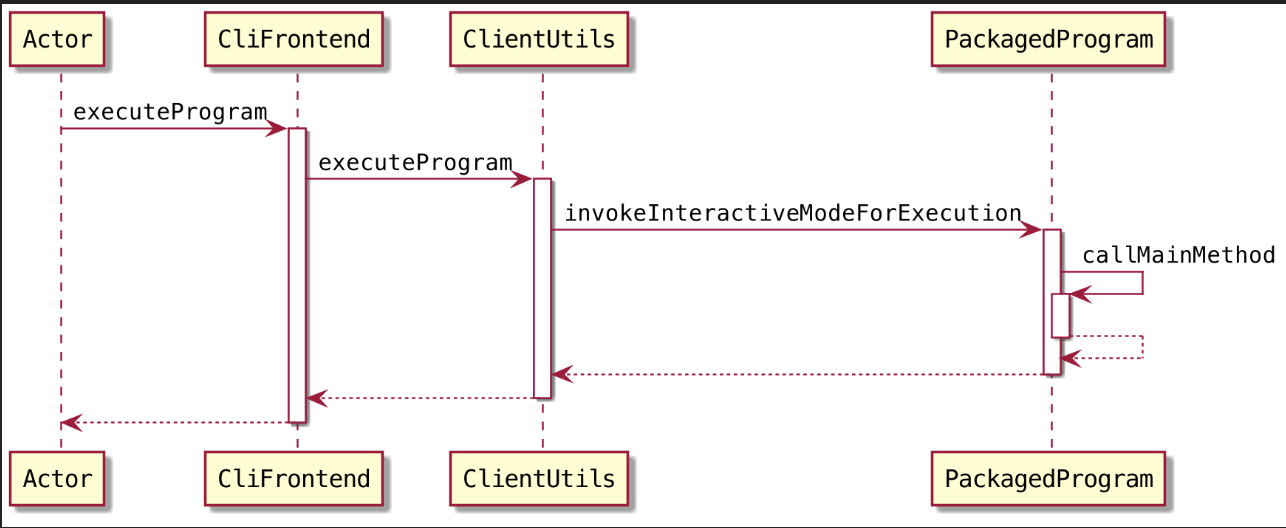
点点点~,最后来到 PackagedProgram#callMainMethod() 里,在这个方法里通过反射得到运行主类的 main() 方法实例
1
mainMethod = entryClass.getMethod("main", String[].class);
entryClass其实就是我们自己写的程序的实例,也就是说接下来要去执行用户自己编写的程序的 main() 方法啦~
3.5.3. entryClass.main()
经过 CliFrontend 类的转交。那么最终到了用户自己编写程序类的 main() 方法,接下来就是我们的自己编写的应用程序的一个执行了~
构建 StreamExecutionEnvironment
Flink 应用程序的执行,首先就是创建运行环境 StreamExecutionEnvironment
一般在企业环境中, 都是通过 getExecutionEnvironment() 来获取 ExecutionEnvironment,如果是本地运行的话,则会获 取到:LocalStreamEnvironment,如果是提交到 Flink 集群运行,则获取到: StreamExecutionEnvironment。
1
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
**SparkContext & ExecutionEnvironment **🤔️
Spark 当中的 spark context 这个类非常的重量级,它里面包含了各种在执行应用程序过程当中所需要的各种组件 ExecutionEnvironment 这个类呢相对来说要轻量级一点。
StreamExecutionEnvironment 是 Flink 应用程序的执行入口,提供了一些重要的操作机制:
提供了
readTextFile(),socketTextStream(),createInput(),addSource()等方法去对接数据源我们要去加载数据源,得到一个数据抽象,最终调用的都是 StreamExecutionEnvironment 里面的这四大类的方法。
1
DataStream<String> text = env.socketTextStream(hostname, port, "\n");
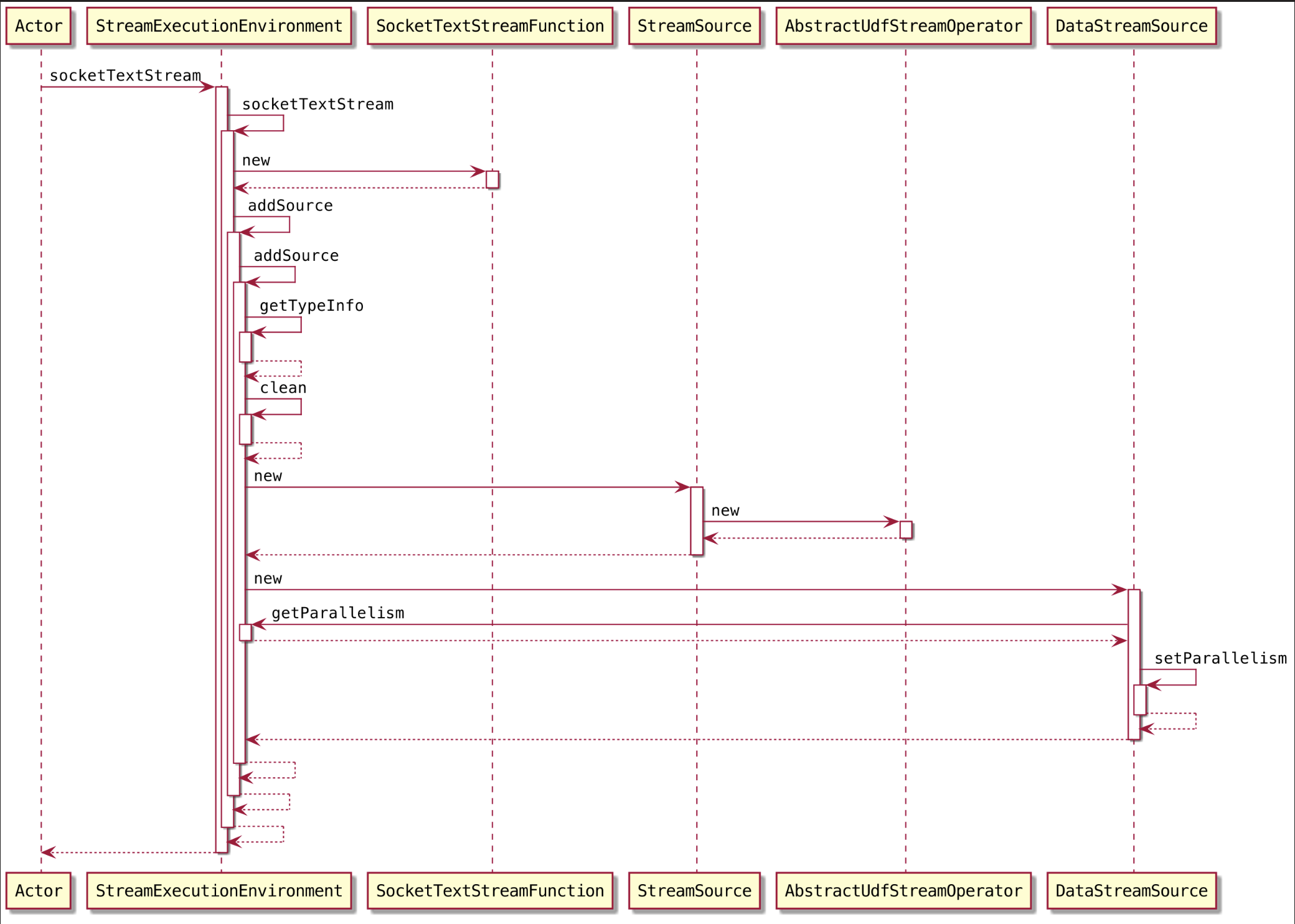
提供了 setParallelism() 设置程序的并行度
StreamExecutionEnvironment 对象内部有两个配置管理对象
ExecutionConfig
管理是当前这个job 在执行过程当中的信息。
Configuration
管理集群的配置信息
List<Transformation<?>> transformations
StreamExecutionEnvironment 管理了一个 List<Transformation<?>> transformations 成员变量,保存 Job 的各种算子转化得到的 transformation
在写 Flink 应用程序的时候,针对某一个 data stream 会调用各种算子来执行一些操作,最终所有的算子都会被转化成 transformation,然后添加到 transformations 集合里面。在提交 Job 的时候,从 transformation 集合里面拿出所有的 transformation,把它构建成 StreamGraph
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15DataStream<WordWithCount> windowCounts = text
.flatMap((FlatMapFunction<String, WordWithCount>) (value, out) -> {
for (String word : value.split("\\s")) {
out.collect(new WordWithCount(word, 1L));
}
})
.keyBy(value -> value.word)
.timeWindow(Time.seconds(5))
.reduce(new ReduceFunction<WordWithCount>() {
public WordWithCount reduce(WordWithCount a, WordWithCount b) {
return new WordWithCount(a.word, a.count + b.count);
}
});以
flatMap为例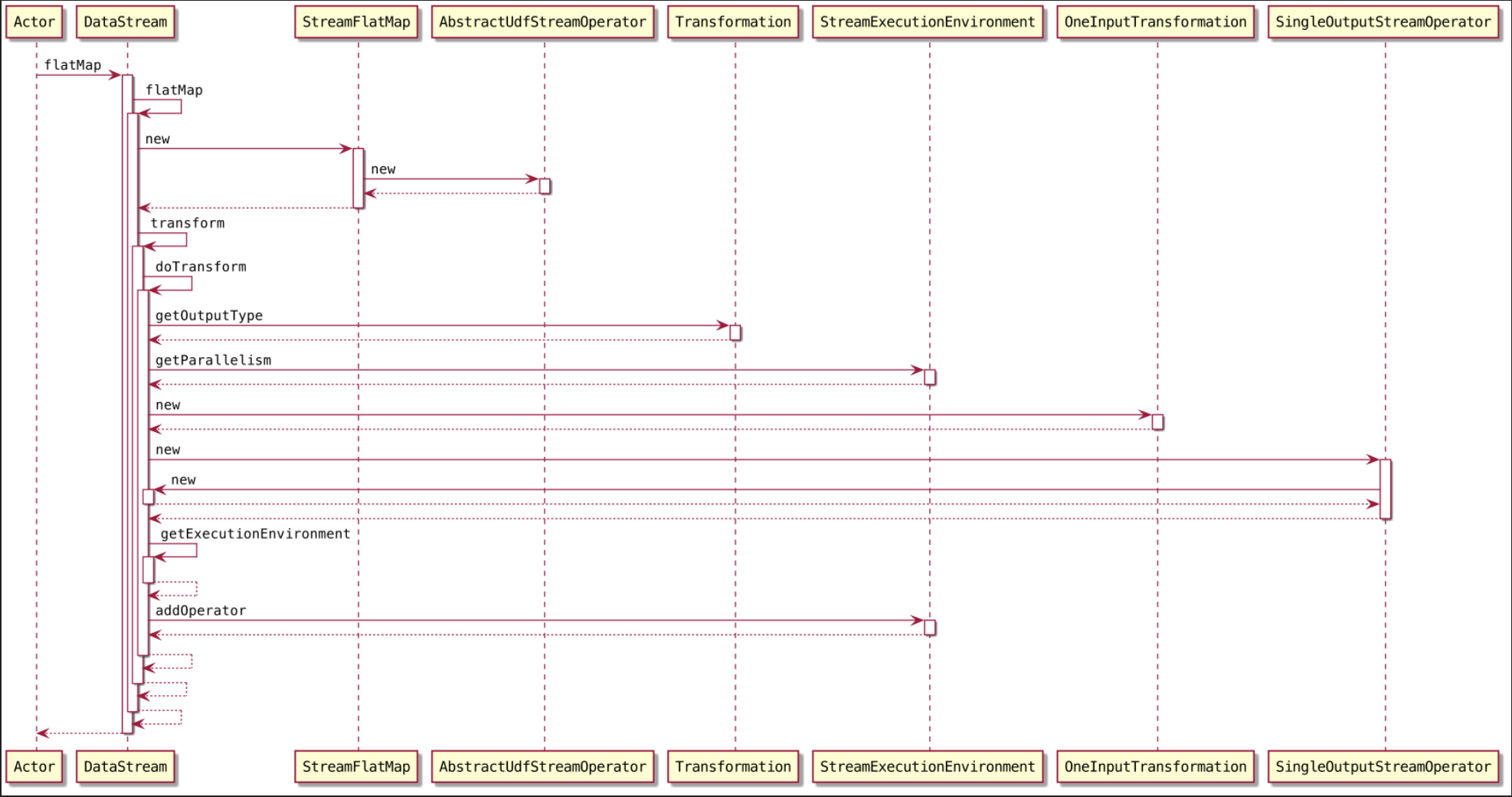
如图,程序会调用一个
DataStream#addOperator()的方法,将 flatMap 算子成的 transformation,添加到 transformations 集合里面1
2
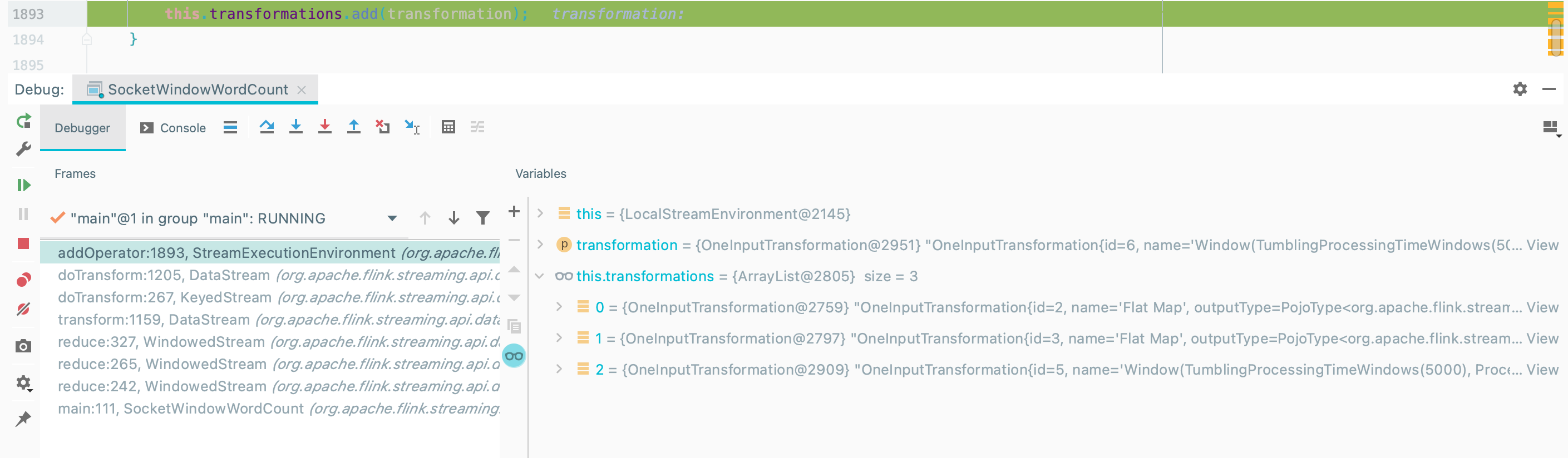
3public void addOperator(Transformation<?> transformation) {
this.transformations.add(transformation);
}
StreamExecutionEnvironment 提供了 execute() 方法主要用于提交 Job 执行。该方法接收的 参数就是:StreamGraph
通过 execute 方法来提交 job 的时候,那我们先把所有的 transformation,构建成一个stream graph。然后再提交
1
env.execute("Socket Window WordCount");
返回一个可用的执行环境。执行环境是整个 Flink 程序执行的上下文,记录了相关配置 (如并行度),并提供了一系列方法,如读 取输入流,以及真正开始运行整个代码的 execute() 方法等
execute()
当客户端调用
StreamExecutionEnvironment.execute()方法执行应用程序代码时,就会通过StreamExecutionEnvironment中 提供的方法生成 StreamGraph 对象。StreamGraph 结构描述了作业的逻辑拓扑结构,并以有向无环图的形式描述作业中算子之间的上下游连接关系。1
2
3public JobExecutionResult execute(String jobName) throws Exception {
return execute(getStreamGraph(jobName));
}来看 StreamGraph 的底层实现及构建过程👀~
我们去提交这一个job 执行。那么到底提交的时候会做哪些事情呢?那么记住当你点进来 execute() 的时候,你会发现这个代码是这个样子的。
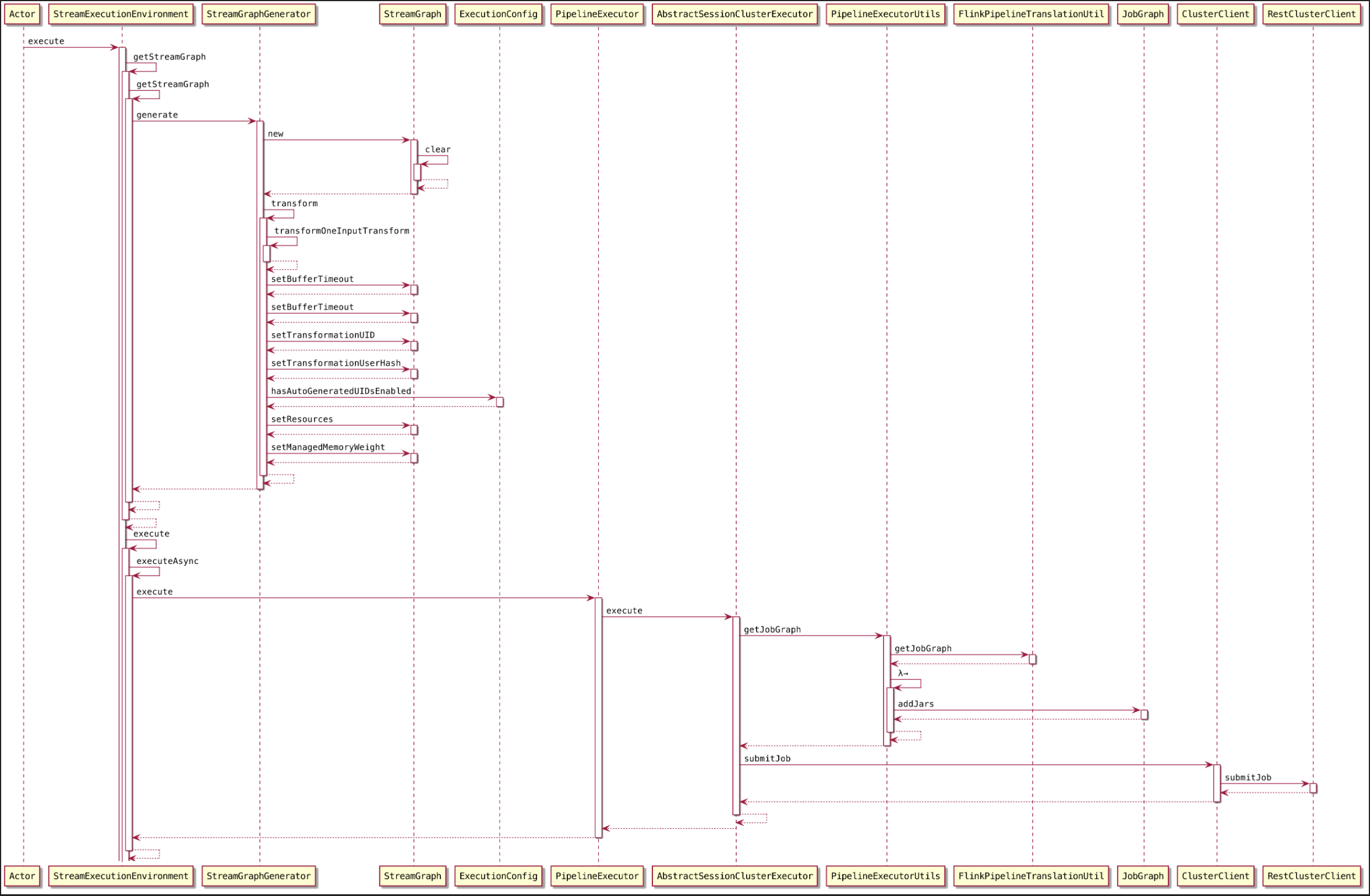
getStreamGraph()
- generate()
 微信
微信 支付宝
支付宝