Spark-源码学习-SparkSession-ShareState-CacheManager
一、概述
在Spark中,SQL缓存是重复使用某些计算的常用技术。它有可能加快使用相同数据的其他查询的速度,但如果我们想获得良好的性能,有一些注意事项需要牢记。
CacheManager 是 Spark SQL 中内存缓存的管理者,在 Spark SQL 中提供对缓存查询结果的支持,并在执行后续查询时自动使用这些缓存结果。数据使用 InMemoryRelation 中存储的字节缓冲区进行缓存。CacheManager 通过 SharedState 在 SparkSessions 之间共享。
二、设计
CacheManager 负责跟踪查询计划中已经缓存的计算。当 $cache()$ 被调用时,CacheManager 会在引擎盖下被直接调用,它会调出缓存函数被调用的DataFrame的分析逻辑计划,并将该计划存储在名为 cachedData 的索引序列中。
缓存管理器阶段是逻辑规划的一部分,它发生在分析器之后,优化器之前:
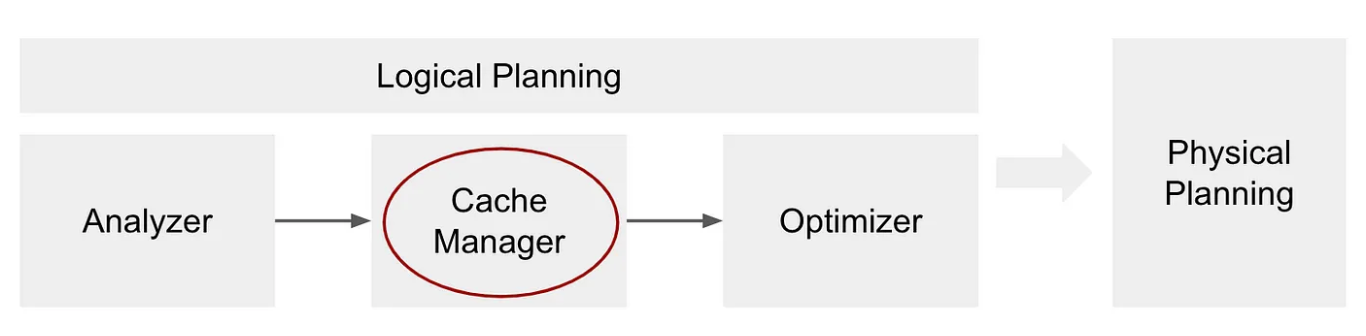
https://towardsdatascience.com/best-practices-for-caching-in-spark-sql-b22fb0f02d34
1 | When you run a query with an action, the query plan will be processed and transformed. In the step of the Cache Manager (just before the optimizer) Spark will check for each subtree of the analyzed plan if it is stored in the cachedData sequence. If it finds a match it means that the same plan (the same computation) has already been cached (perhaps in some previous query) and so Spark can use that and thus it adds that information to the query plan using the InMemoryRelation operator which will carry information about this cached plan. This InMemoryRelation is then used in the phase of physical planning to create a physical operator— InMemoryTableScan. |
三、实现
3.1. 属性
3.1.1. cachedData
CacheManager 将 CachedData 类型中的缓存计划列表作为不可变序列 IndexedSeq 进行维护。一个 CachedData 实例持有一个缓存的逻辑计划和一个为这个逻辑计划创建的 InMemoryRelatoin 实例。

InMemoryRelation 实例引用为构建 CachedBatch 的 RDD 而创建的 CacheRDDBuilder 实例,RDD[CachedBatch] 是一批缓存行的数据结构。CachedRDDBuilder 的$buildBuffers()$ 方法定义了执行逻辑计划的逻辑,将结果行分批进行缓存并返回RDD[CachedBatch]。此刻,RDD[CachedBatch]的 $persist()$ 方法被调用。然而,由于持久化操作是延迟执行的,因此缓存 RDD 的构建过程只是被定义,还没有实际执行。

缓存本质上是一个 IndexedSeq 表示保证不可变的索引序列。索引序列支持恒定时间或接近恒定时间的元素访问和长度计算。它们是根据用于索引和长度的抽象方法定义的。
索引序列不会给Seq添加任何新方法,但可以有效实现随机访问模式。IndexedSeq 的默认实现是一个 scala.Vector
1 | private var cachedData = IndexedSeq[CachedData]() |
InMemoryRelation 还缓存了哪些配置?
- spark.sql.inMemoryColumnarStorage.compressed (默认 enabled)
- spark.sql.inMemoryColumnarStorage.batchSize (默认 10000)
- 输入数据的存储级别 (默认 MEMORY_AND_DISK)。
- 优化过的物理查询计划 (在请求 SessionState 执行 analyzed logical plan 之后)。
- 输入的表名。
- analyzed 查询计划的统计信息。
3.1.2. forceDisableConfigs
1 | private val forceDisableConfigs: Seq[ConfigEntry[Boolean]] = Seq( |
3.2. 方法
当一个RDD不再被使用,并且没有它的强引用存在时,GC过程将释放为这个RDD分配的资源。当RDD(数据集的定义,不包括实际数据)被删除时,它的缓存数据也不再有用,但它仍然占据着存储资源,无论是内存还是磁盘。Spark提供了ContextCleaner,它管理着未使用的缓存资源的释放。ContextCleaner包含一个referenceBuffer队列,它由SetFromMap的CleanupTaskWeakRference类型对象支持。当GC收集一个未使用的RDD时,这个RDD的弱引用被添加到 referenceBuffer队列中。
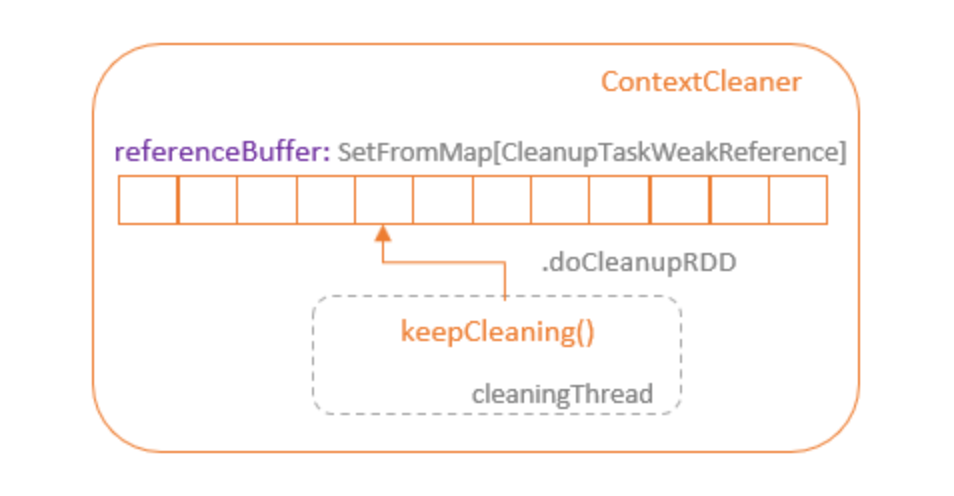
ContextCleaner 在一个单独的线程中运行 $keepCleaning()$ 方法,该方法在 referenceBuffer 中循环,获取 RDD 的弱引用。ContextCleaner 的 $doCleanupRDD()$ 方法以 RDD 的 id 被调用,它执行 $unpresistRDD()$ 方法来移除 RDD 缓存的强引用,以便 GC 可以释放 RDD 缓存。
2.2.1. 清除缓存
- $clearCache$
2.2.2. 设置缓存
- $cacheQuery$
3.2.3. 获取缓存
$lookupCachedData$
1
2
3def lookupCachedData(plan: LogicalPlan): Option[CachedData] = {
cachedData.find(cd => plan.sameResult(cd.plan))
}$useCachedData$
四、使用场景
持久化操作 $Dataset#persist$
1
2
3
4def persist(newLevel: StorageLevel): this.type = {
sparkSession.sharedState.cacheManager.cacheQuery(this, None, newLevel)
this
}输入数据的存储级别 (默认 MEMORY_AND_DISK)。
优化过的物理查询计划 (在请求 SessionState 执行 analyzed logical plan 之后)。
输入的表名。
analyzed 查询计划的统计信息。
spark.sql.inMemoryColumnarStorage.compressed (默认 enabled)
spark.sql.inMemoryColumnarStorage.batchSize (默认 10000)
https://mp.weixin.qq.com/s/1bJxqdSqWTvGlcMbFKXAIA
五、总结
 微信
微信 支付宝
支付宝