Spark-源码学习-SparkCore-存储服务-架构设计
一、概述
Spark 的存储体系在整个 Spark 架构中与大地在生态圈中的作用非常类似。Spark 的存储体系贯穿了集群中的每个实例。从单个节点来看,Spark 的存储体系隶属于 SparkEnv。Spark 存储系统用于存储 3 个方面的数据,分别是 RDD 缓存、Shuffle 中间文件、广播变量。
RDD 缓存
RDD 缓存指的是将 RDD 以缓存的形式物化到内存或磁盘的过程。对于一些计算成本和访问频率都比较高的 RDD 来说,缓存有两个好处:
- 降低失败重试的计算开销
- 通过对缓存内容的访问,可以有效减少从头计算的次数,从整体上提升作业端到端的执行性能。
Shuffle 中间文件
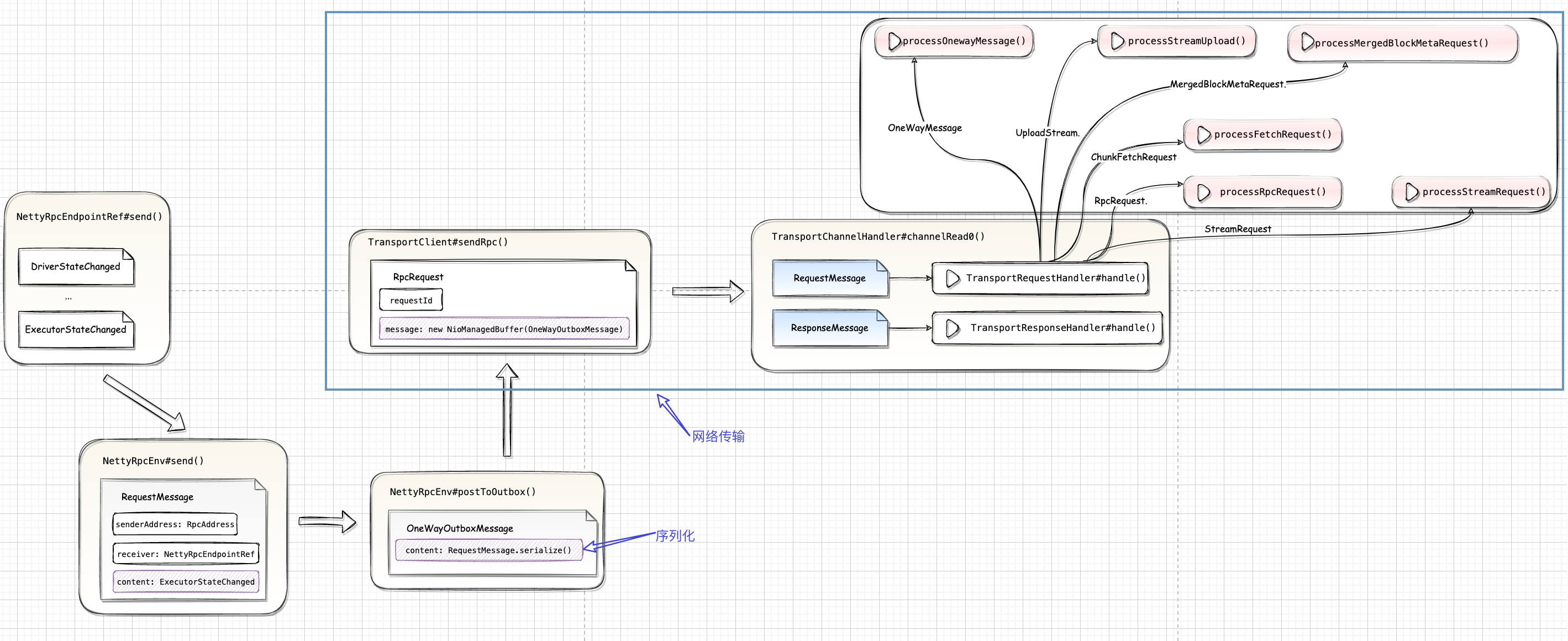
Shuffle 中间文件指的是 Shuffle Map 阶段的输出结果,这些结果以文件的形式暂存于本地磁盘。在Shuffle Reduce 阶段通过网络拉取中间文件用于聚合计算,如求和、计数等。在集群范围内,Reducer 想要拉取属于自己的那部分中间数据,就必须要知道这些数据都存储在哪些节点,以及什么位置。而这些关键的元信息,也是由 Spark 存储系统保存并维护的。
广播变量
广播变量往往用于在集群范围内分发访问频率较高的小数据。利用存储系统,广播变量可以在 Executors 进程范畴内保存全量数据。这样一来,对于同一Executors 内的所有计算任务,应用就能够以 Process local 的本地性级别,来共享广播变量中携带的全量数据了。
二、Block
在 Spark 的存储体系中,数据的读写是以块为单位, Block 是 Spark 存储的基本单位。
这里的 Block 和 Hdfs 的 Block 是不一样的,HDFS 中是对大文件进行分 Block 进行存储,Block大小是由 dfs.blocksize 决定的;而 Spark 中的 Block 是用户的操作单位,一个 Block 对应一块有组织的内存,一个完整的文件或文件的区间端,并没有固定每个 Block 大小的做法。
2.1. 块数据 BlockData
BlockData 接口定义了数据转化的规范。
$toInputStream()$: 将块数据转化为java.io.InputStream。
$toNetty()$: 将块数据转化为适合 Netty 传输的对象格式。
$toChunkedByteBuffer()$: 将块数据转化为 ChunkedByteBuffer。
ChunkedByteBuffer 是对多个
java.nio.ByteBuffer的封装,表示多个不连续的内存缓冲区中的数据。$toByteBuffer()$: 将块数据转化为单个
java.nio.ByteBuffer。$size()$: 返回 BlockData 的长度。
$dispose()$: 销毁 BlockData。
BlockData 目前有 3 个实现类: 基于内存和 ChunkedByteBuffer 的 ByteBufferBlockData、基于磁盘和 File 的 DiskBlockData,以及加密的 EncryptedBlockData。

2.2.元数据
2.2.1. BlockId
Spark 对 Block 的查询、存储管理,是通过唯一的 BlockId 来进行区分的。BlockId 本质上是一个字符串,在 Spark 中将它保证为 case 类

2.2.2. BlockInfo
为了方便跟踪块的一些基本数据,需要用一个专门的数据结构 BlockInfo 来维护块的元数据信息,该类主要由三个变量:
level: 块的期望存储等级, 不代表实际的存储情况
如: 设定为
StorageLevel.MEMORY_AND_DISK,那么这个块有可能只在内存而不在磁盘中,反之同理。Spark 的存储体系包括磁盘存储与内存存储。Spark将内存又分为堆外内存和堆内存。有些数据块本身支持序列化及反序列化,有些数据块还支持备份与复制。Spark存储体系将以上这些数据块的不同特性抽象为存储级别(StorageLevel)。
1
2
3
4
5
6
7class StorageLevel private(
private var _useDisk: Boolean, //磁盘
private var _useMemory: Boolean, //这里其实是指堆内内存
private var _useOffHeap: Boolean, //堆外内存
private var _deserialized: Boolean, //是否为非序列化
private var _replication: Int = 1 //副本个数
)存储级别 含义 MEMORY_ONLY 以非序列化的 Java 对象的方式持久化在 JVM 内存中。如果内存无法完全存储 RDD 所有的 partition,那么那些没有持久化的 partition 就会在下一次需要使用它们的时候,重新被计算 MEMORY_AND_DISK 同上,但是当 RDD 某些 partition 无法存储在内存中时,会持久化到磁盘中。下次需要使用这些 partition 时,需要从磁盘上读取 MEMORY_ONLY_SER 同 MEMORY_ONLY,但是会使用 Java 序列化方式,将 Java 对象序列化后进行持久化。可以减少内存开销,但是需要进行反序列化,因此会加大 CPU 开销 MEMORY_AND_DISK_SER 同 MEMORY_AND_DISK,但是使用序列化方式持久化 Java 对象 DISK_ONLY 使用非序列化 Java 对象的方式持久化,完全存储到磁盘上 MEMORY_ONLY_2 MEMORY_AND_DISK_2 如果是尾部加了 2 的持久化级别,表示将持久化数据复用一份,保存到其他节点,从而在数据丢失时,不需要再次计算,只需要使用备份数据即可 classTag: 块的类标签
tellMaster: 是否要将该块的元信息告知 Master
BlockId、BlockData 与 BlockInfo,它们三者合起来就可以基本完整地描述 Spark 中的一个块了~
2.2.3. BlockInfoWrapper
Spark 使用 BlockInfoManager 来管理当前节点所管理的数据块的元数据,维护了 BlockId 到 BlockInfo 的映射关系。
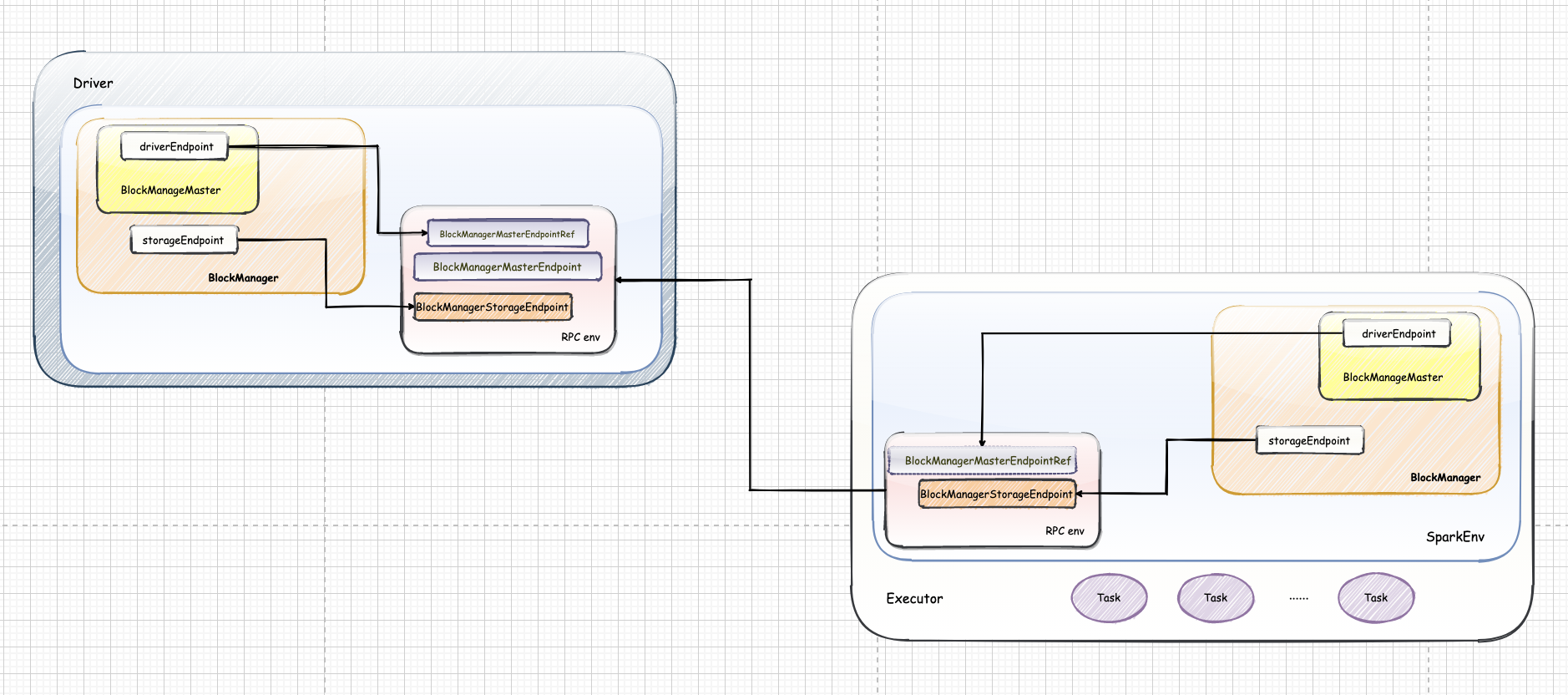
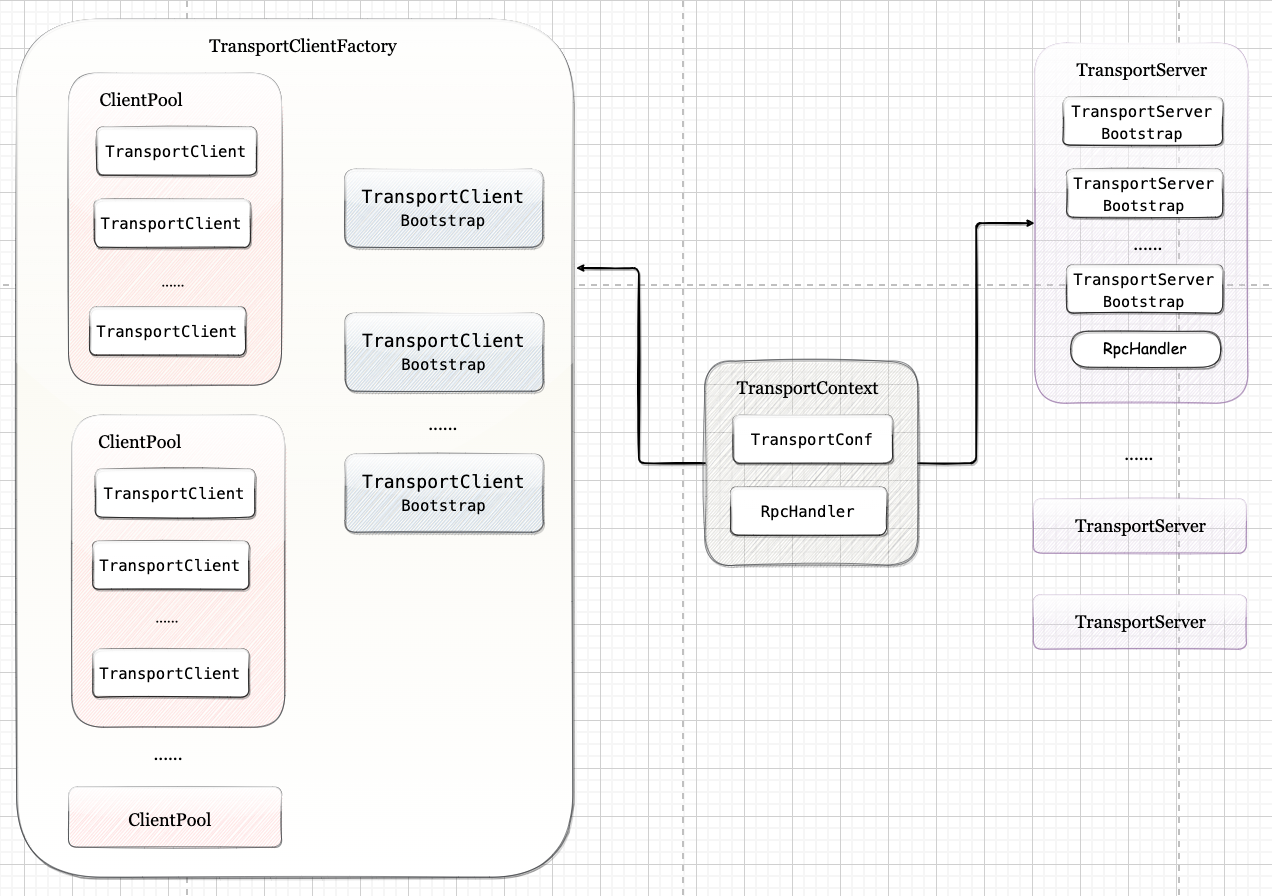
三、BlockManager
BlockManager 是 Spark 存储体系中的核心组件,运行在每个节点(Driver和 Executors)上,提供接口用于读写本地和远程各种存储设备(内存、磁盘和off-heap)。
BlockManager 实现了 BlockDataManager 和 BlockEvictionHandler 两个特征,分别表示BlockManager可以管理块数据,以及从内存中淘汰块。截止目前,BlockManager是这两个特征的唯一的实现类。

 微信
微信 支付宝
支付宝