Flink-源码学习-架构设计-部署模式-Application-Flink On Yarn
正在总结中,等我😭~~~
Flink-源码学习-架构设计-部署模式-PerJob-Flink On Yarn
正在总结中,等我😭~~~
Flink-源码学习-架构设计-部署模式-Application-Flink On Yarn
正在总结中,等我😭~~~
Flink-源码学习-架构设计-部署模式-PerJob-Flink On Yarn
正在总结中,等我😭~~~
Spark-源码学习-SparkSQL-一条聚合 SQL 语句的执行过程~
一、概述在典型的 Spark SQL 应用场景中,数据的读取、数据表的创建和分析都是必不可少的过程。通常来讲,SparkSQL 查询所面对的数据模型以关系表为主。
如图所示的案例显示了使用 SparkSQL 进行数据分析的一般步骤。
二、聚合体系先了解下 Spark SQL 的聚合体系设计~
引用本站文章
Spark-源码学习-SparkSQL-聚合体系-架构设计
Joker
三、流程可以先看看这个~
引用本站文章
Spark-源码学习-SparkSQL-一条 SQL 语句的执行过程概述~
Joker
...
Flink-源码学习-存储服务-架构设计-磁盘管理
正在总结中,等我😭~~~
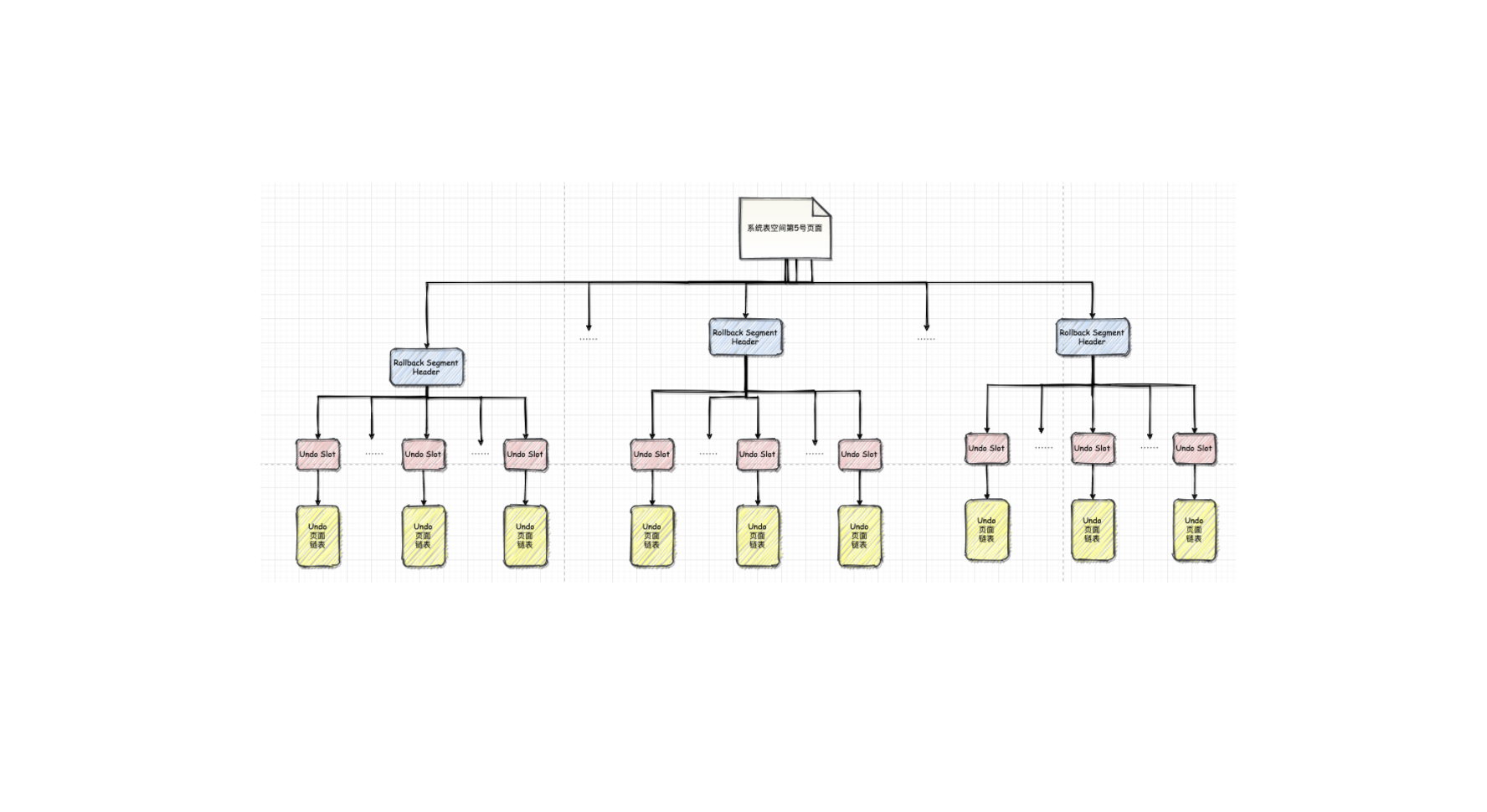
Undo(3):存储结构-回滚段
一个事务在执行过程中最多可以分配4个Undo页面链表,在同一时刻不同事务拥有的Undo页面链表是不一样的,所以在同一时刻系统里其实可以有许许多多 个Undo页面链表存在,为了更好的管理这些链表,InnoDB 设计了 Rollback Segment Header 页面,在这个页面中存放了各个Undo页面链表的first undo page的页号,这些页号称之为undo slot
每一个 Rollback Segment Header 页面都对应着一个回滚段(Rollback Segment),与其他段不同的是,Rollback Segment里其实只有一个页面
TRX_ RSEG_ MAXSIZE: Rollback Segment中管理的所有Undo页面链表中的Undo页面数量之和的最大值
TRX_RSEG_HISTORY_SIZE: History链表占用的页面数量。
TRX_RSEG_HISTORY: History链表的基节点。
TRX_RSEG_FSEG_HEADER: Rollback Segment对应的10字节大小的Segment Header结构,通过 ...
Flink-源码学习-存储服务-架构设计
一、概述Flink 提供的存储服务包括内存管理服务和文件管理服务,TaskManager 启动时也会初始化 I/O 管理组件 IOManager,负责将数据输出到磁盘并将其读取回来以及内存管理组件 MemoryManager 负责协调内存使用。
二、内存管理Flink 为了让用户更好的调整内存分配,达到资源的合理分配,在 Flink1.10 引入了 TaskManager 的内存管理,后续在 Flink1.11 版本引入了 JobManager 的内存管理,用户可以通过配置的方式合理的分配资源。不管是 TaskManager 还是 JobManager 都是单独的 JVM 进程,共用一套内存模型抽象(TaskManager 的内存模型更加复杂), Flink 从一开始就选择了使用自主的内存管理,避开了 JVM 内存管理在大数据场景下的问题,提升了计算效率。
2.1. 架构设计Flink 的 JVM 的进程总内存(Total Process Memory) 包含了 Flink 总内存(Total Flink Memory) 和运行 Flink 的 JVM 特定内存(JVM Spec ...
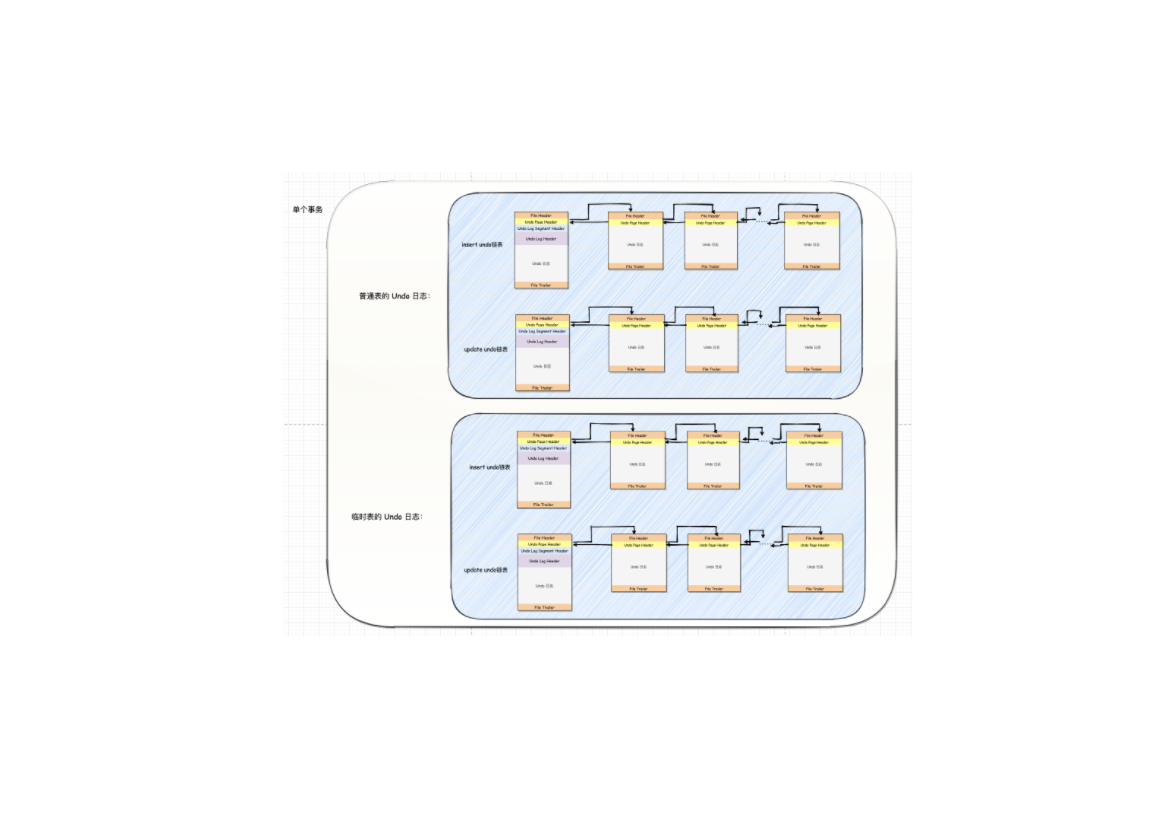
Undo(2):存储结构-页面链表
因为一个事务可能包含多个语句,而且一个语句可能对若干条记录进行改动,而对每条记录进行改动前,都需要记录1条或2条的undo日志,所以在一个事务执行过程中可能产生很多undo日志,这些日志可能一个页面放不下,需要放到多个页面中
一、通用链表结构1.1. List Node在写入undo日志的过程中会使用到多个链表,很多链表都有同样的节点结构,在某个表空间内,可以通过一个页的页号和在页内的偏移量来唯一定位一个节点的位置,这两个信息也就相当于指向这个节点的一个指针
Pre Node Page Number 和 Pre Node Offset 的组合就是指向前一个节点的指针
Next Node Page Number 和 Next Node Offset的组合就是指向后一个节点的指针。
1.2. List Base Node整个List Node占用12个字节的存储空间。为了更好的管理链表,InnoDB 引入了基节点的结构(List Base Node),存储链表头节点、尾节点以及链表长度信息
List Length 表明该链表节点数量。
First Node Page Nu ...
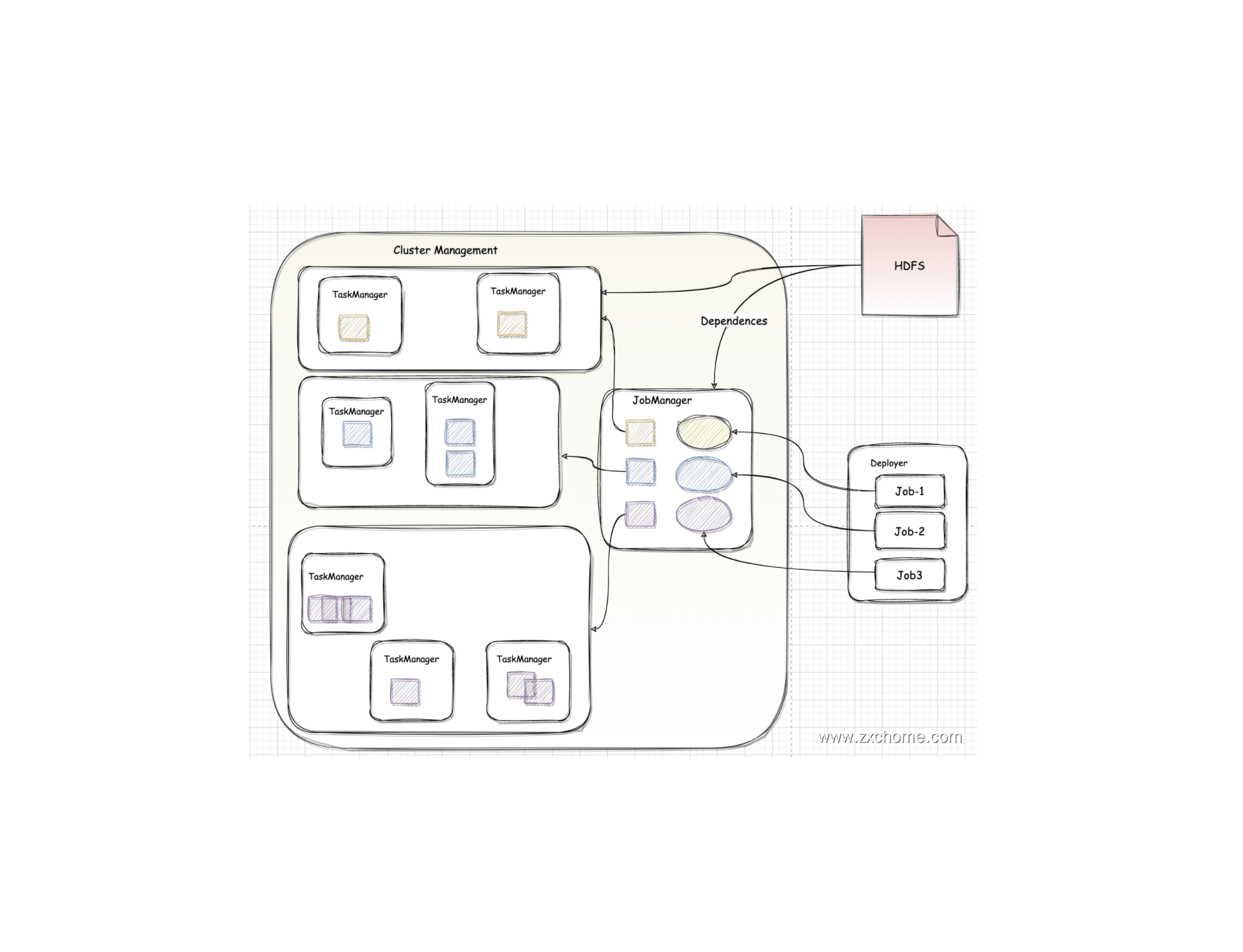
Flink-源码学习-架构设计-部署模式-Application
一、概述无论是 Session 模式 还是 Per_Job 模式,其 main 方法都是在容户端执行来获取 Flink 运行时所需的依赖项,并生成JobGraph,提交到集群的操作都会在实时平台所在的机器上执行,会给服务器造成很大的压力。尤其在大量用户共享客户端时,问题更加突出。其次,两种模式提交任务的时候会把本地 Flink 的所有 jar 包先上传到 hdfs 上相应的临时目录,这个会带来大量的网络的开销,如果任务特别多的情況下,平台的吞吐量将会直线下降。Flink-1.11 中引入了一种新的部署模式,即 Application 模式。Application 模式下,用户程序的 main 方法将在集群中而不是客户端运行。用户将程序選辑和依赖打包进一个可执行的 jar 包里,集群的入口程序 (ApplicationClusterEntryPoint) 负责调用其中的 main 方法生成 JobGraph
Applicaton 模式为每个提交的应用程序创建一个集群,该集群可以看作是在特定应用程序的作业之间共享的会话集群,并在应用程序完成时终止。
二、架构设计目前,Flink- ...
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.