











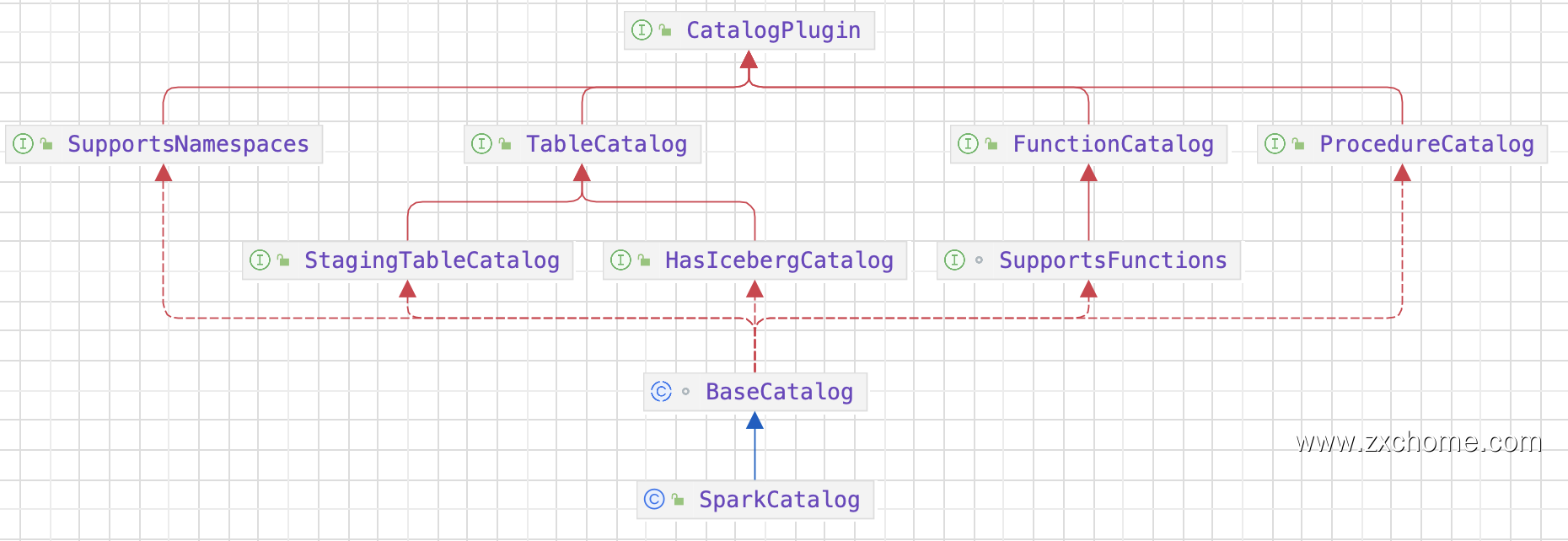
数据湖-Iceberg-源码学习-Query Engines-Spark-读数据-集成-Catalog 设计
一、概述Iceberg 为了和 Spark 对接,实现了 Spark 关于 Catalog 规范。Catalog API 是 Iceberg 进行表管理 (create/drop/rename 等)的一个组件。目前 Iceberg 主要支持 HiveCatalog 和 HadoopCatalog 两种 Catalog。Iceberg 同时提供 Catalog 用良好的抽象来对接数挑存储和元数据管理。第三方存储可以实现 Iceberg 的 Catalog API 接口,跟 Iceberg 对接,组织管理元数据。
二、设计2.1. 属性
2.2. 主要方法
2.2.1. loadTable()
2.2.2. createTable()建表语句如下
1234CREATE TABLE local.iceberg_db.table_demo( id bigint, data string) USING parquet
SparkSql 从建表SQL语句中解析出表名,表的 Schema (用StructType来表示),表的属性等信息信息,调用 Catalog 进行建表 ...
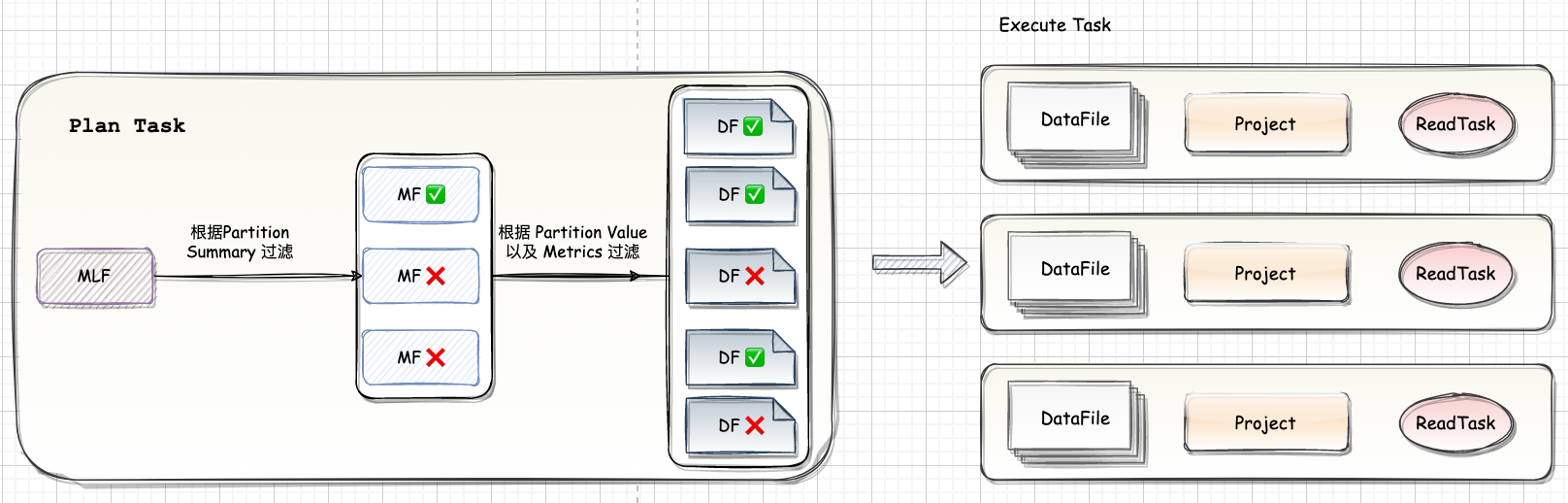
数据湖-Iceberg-源码学习-Query Engines-Spark-读数据
一、概述Spark 在读 Iceberg 表时通过读取 Metadata 文件可以实现高效的文件过滤:
首先根据 Partition Summary 进行文件过滤。如图,读取 Snapshot 对应的 ManifestFile List 可以读到三个ManifestFile
然后根据 where 条件加上 Partition Summary 的 min-max 信息可以过滤掉两个 ManifestFile。
根据每个 DataFile 的 Partition Value 和 metrics 信息做进一步的过滤,最后只有三个文件需要进行真正的读取。
执行时 Spark 会将大的文件拆分成多个 task,小的文件合并成一个 task,每个 task 对应一到多个 DataFile。因为 Iceberg 支持 Schema Evolution,要读取的 DataFile 的 schema 和当前表的 schema 可能不匹配,因此需要做一个 Projection 来保证返回的数据的 Schema 和当前表的 Schema 相匹配。
二、Spark 引擎层和 Iceberg 对 ...
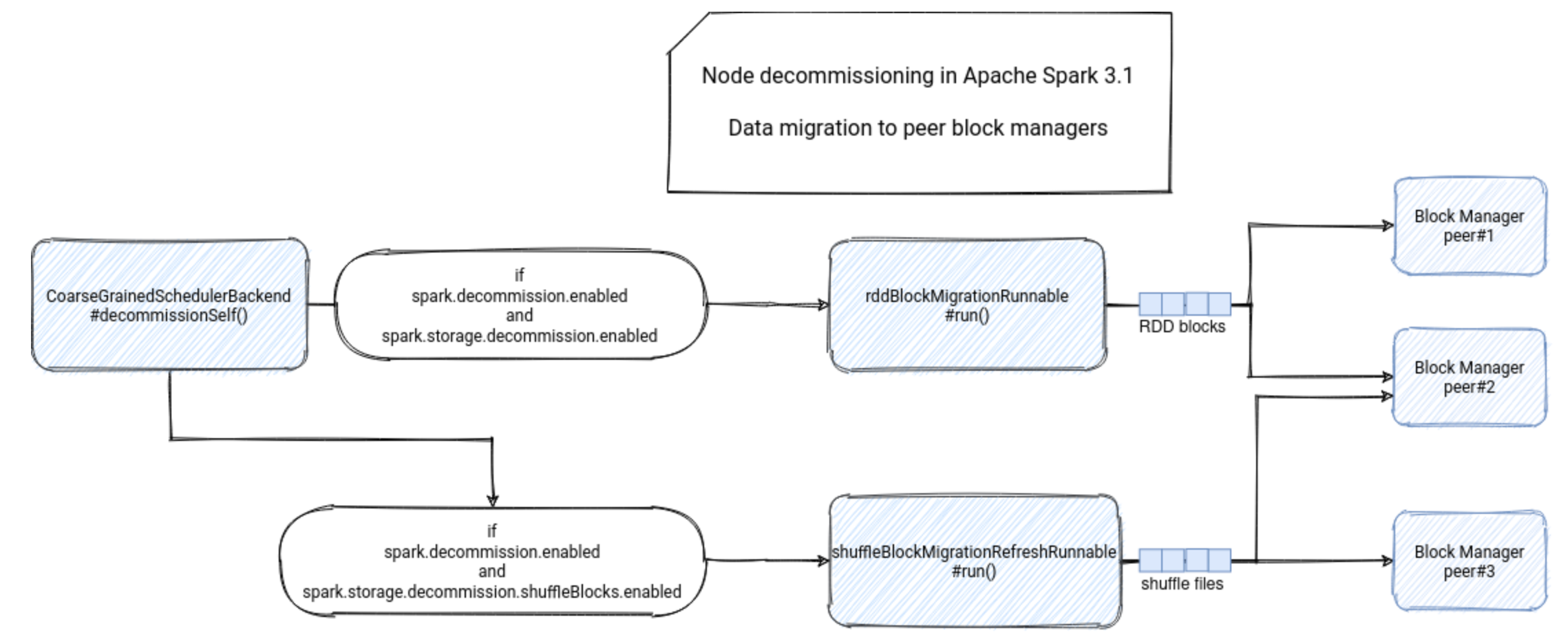
Spark-源码学习-SparkCore-节点退役
一、概述Spark 节点退役特性包括元数据操作(如将 Worker 从可调度资源列表中排除)以及数据迁移(Shuffle 文件和 RDD 块迁移)https://www.waitingforcode.com/apache-spark/what-new-apache-spark-3.1-nodes-decommissioning/read
二、元数据操作三、数据迁移数据迁移入口: $CoarseGrainedExecutorBackend.decommissionSelf()$ 方法中。
首先,该方法会验证节点退役功能是否已启用,即 spask.decommission.enabled 的值是否为 true。此时,执行器还会检查它是否尚未运行退役进程。如果是,则在此阶段不会继续执行退役进程,而是让已启动的进程终止。
12345if (!env.conf.get(DECOMMISSION_ENABLED)) { return} else if (decommissioned) { return}
经过这两次检查后,执行器会将自己标记为退役 ...

数据湖-Iceberg-源码学习-Query Engines-Flink-写数据
一、概述
https://juejin.cn/user/4117007604398775/posts
https://blog.csdn.net/naisongwen/article/details/122725934
https://cloud.tencent.com/developer/article/2049105
https://juejin.cn/post/6992227979526930468 (delete)
https://blog.csdn.net/yiweiyi329/article/details/121842572
https://blog.csdn.net/yiweiyi329/article/details/122012474
https://baijiahao.baidu.com/s?id=1730162628824294760&wfr=spider&for=pc
https://www.cnblogs.com/yunqishequ/p/14450603.html
二、集成2.1. CatalogIceberg 提供了 FlinkCa ...
数据湖-Iceberg-源码学习-Query Engines-Flink-读数据-集成-Connector-DataSet-FlinkInputFormat
一、概述二、设计FlinkInputFormat 有两个重要的成员变量:TableLoader tableLoader 和 FileIO io。通过它们,可以对元数据和数据进行操作。流任务启动时候执行InputFormatSourceFunction 的 $open$ 方法完成初始化,然后就通过 FlinkInputFormat 循环读取数据记录,需要经过两大步骤:
获取 FlinkInputFormat 迭代器前者对应代码中getinputSplits方法,其通过RPC方法调用获取读取文件FlinkInputSplit的迭代器,实际最终仍然是调用FlinklnputFormat的createlnputSplits,在createlnputSplits方法中,通过Flink SplitPlanner返回Flinklnputsplit迭代器
获取 FileScanTask 迭代器,并从中读取记录。
通过 $format.nextRecord$ 读取记录,内部使用了 DataIterator,在 $format.open$ 初始化 DataIterator,在 DataItera ...
数据湖-Iceberg-源码学习-Query Engines-Flink-读数据
一、概述任何存储系统都是由数据和元数据组成,Iceberg 也不例外,外部系统访问存储系统需要两步:先从元数据系统中获取要访问数据的元数据,如所在的位置等信息,然后再通过元数据访问存储系统,访问实际的数据。
https://juejin.cn/user/4117007604398775/posts
https://blog.csdn.net/naisongwen/article/details/127594611
https://blog.csdn.net/yiweiyi329/article/details/126691684
https://zhuanlan.zhihu.com/p/580268765
https://cloud.tencent.com/developer/article/2049105
https://blog.csdn.net/weixin_47482194/article/details/116099540
https://www.jianshu.com/u/f5f514c417e6
https://juejin.cn/post/697505801105 ...
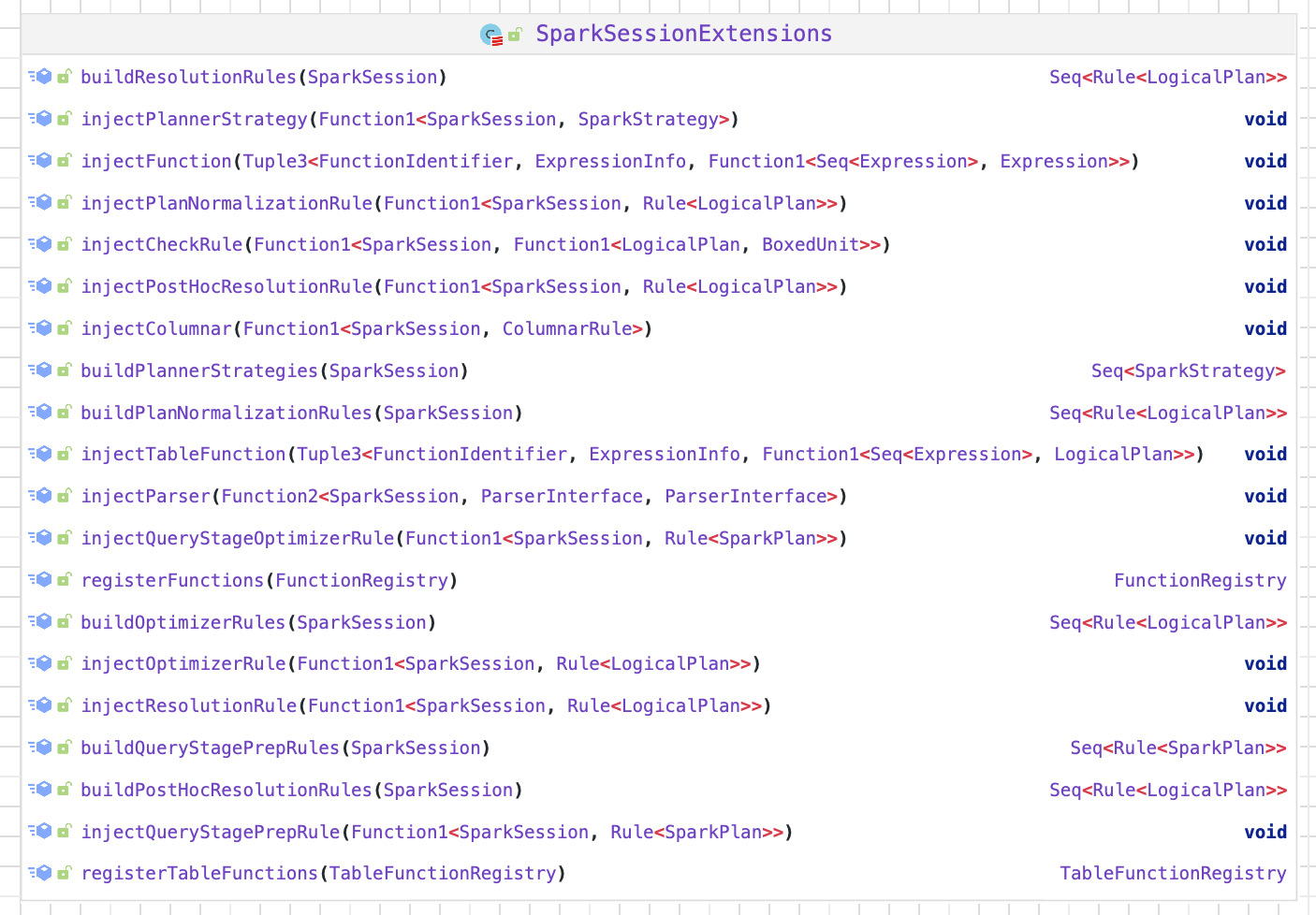
Spark-源码学习-SparkSession-Extensions
一、概述Spark SQL Extensions 提供了一种灵活的机制,使得 Spark 用户可以在 SQL 解析的 Parser、Analyzer、Optimizer 以及 Planner 等阶段进行自定义扩展,包括自定义 SQL 语法解析、新增数据源等等。
二、设计SparkSessionExtensions 保存了用户自定义的扩展规则,包含以下方法:
• $buildResolutionRules$ 构建扩展规则添加到 Analyzer 的 resolution 阶段
• $injectResolutionRule$ 向 Analyzer 的 resolution 阶段注册扩展规则生成器
• buildPostHocResolutionRules:构建扩展规则添加到 Analyzer 的 post-hoc resolution 阶段
• injectPostHocResolutionRule:向 Analyzer 的 post-hoc resolution 阶段注册扩展规则生成器
• buildCheckRules:构建扩展检查规则,该规则将会在 analysis 阶段之后运 ...

Flink-源码学习-API-Catalog 体系
一、概述数据处理最关键的方面之一是管理元数据。元数据可以是临时的,如临时表、或者通过 TableEnvironment 注册的 UDF。元数据也可以是持久化的,例如 HiveMetastore 中的元数据。Catalog 提供了一个统一的 API,用于管理元数据,如数据库、表、分区、视图以及数据库或其他外部系统中存储的函数和信息,并使其可以从 Table API 和 SQL 查询语句中来访问。
二、元数据 Catalog API 设计Catalog 在 Flink 中提供了一个统一的 API,用于管理元数据,Catalog 提供了元数据信息,例如数据库、表、分区、视图以及数据库或其他外部系统中存储的函数和信息。
2.1. 元数据模型Flink 的元数据模型定义了任务的元数据结构,如数据库、表、视图、函数等,Flink 定义了 4 类接口分别对应于 4 种元数据类型,元数据类型之间的层次关系如图,最顶层的 Catalog 是元数据的容器。
2.1.1. 数据库数据库等同于数据库中的库实例,接口定义为 CatalogDatabase,定义数据库实例的元数据,一个数据库实例中包含表、 ...
Flink-源码学习-FlinkSQL&Table-Module 体系
一、概述https://ost.51cto.com/posts/17088
Module 允许 Flink 扩展函数能力。它是可插拔的,Flink 官方本身已经提供了一些 Module,用户也可以编写自己的 Module。
例如,用户可以定义自己的函数,并将其作为加载进入 Flink,以在 Flink SQL 和 Table API 中使用。
再举一个例子,用户可以加载官方已经提供的的 Hive Module,将 Hive 已有的内置函数作为 Flink 的内置函数。
目前 Flink 包含了以下三种 Module:
⭐ CoreModule:CoreModule 是 Flink 内置的 Module,其包含了目前 Flink 内置的所有 UDF,Flink 默认开启的 Module 就是 CoreModule,我们可以直接使用其中的 UDF
⭐ HiveModule:HiveModule 可以将 Hive 内置函数作为 Flink 的系统函数提供给 SQL\Table API 用户进行使用,比如 get_json_object 这类 Hive 内置函数(Flink 默认的 Co ...
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.















