数据湖-Iceberg-源码学习-Query Engines-Spark-读数据
一、概述
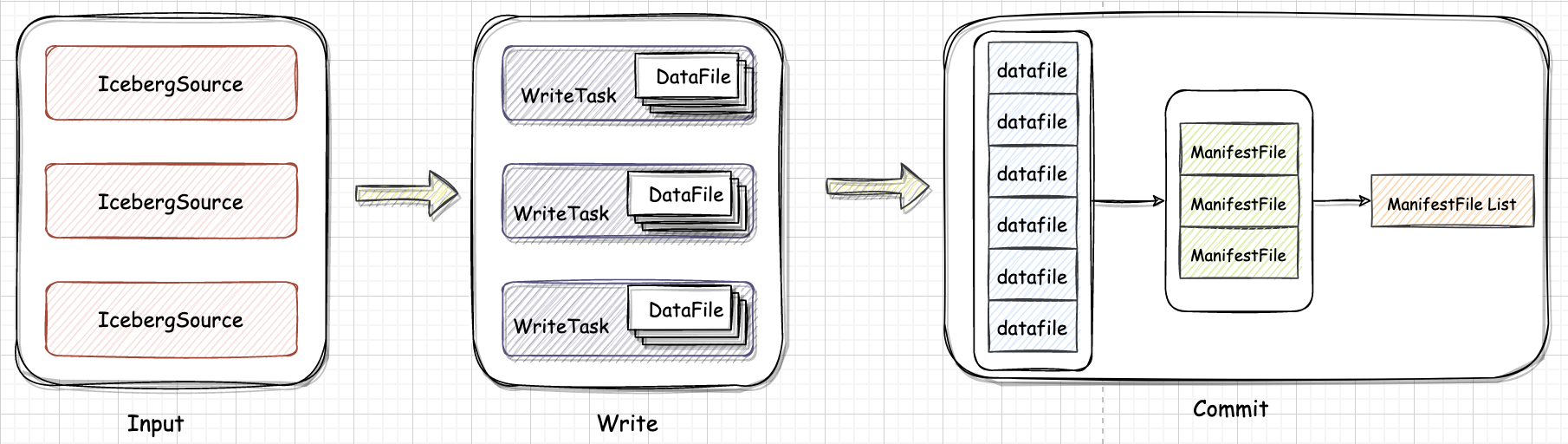
Spark 在读 Iceberg 表时通过读取 Metadata 文件可以实现高效的文件过滤:
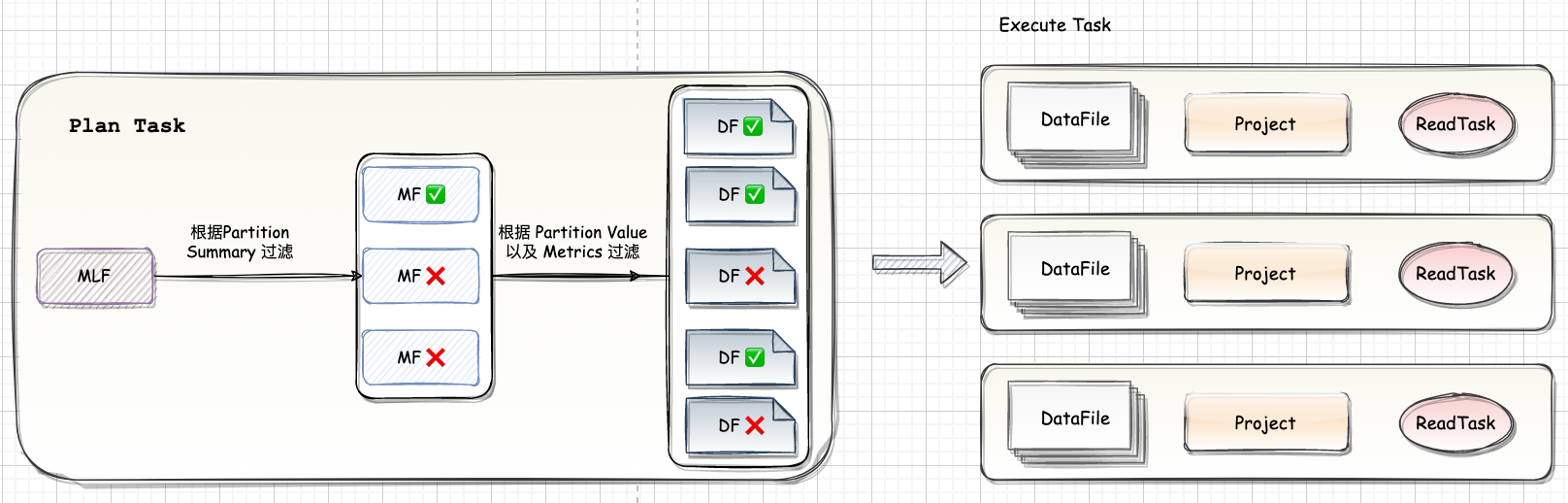
首先根据 Partition Summary 进行文件过滤。如图,读取 Snapshot 对应的 ManifestFile List 可以读到三个
ManifestFile然后根据 where 条件加上 Partition Summary 的 min-max 信息可以过滤掉两个 ManifestFile。
根据每个 DataFile 的 Partition Value 和 metrics 信息做进一步的过滤,最后只有三个文件需要进行真正的读取。
执行时 Spark 会将大的文件拆分成多个 task,小的文件合并成一个 task,每个 task 对应一到多个 DataFile。因为 Iceberg 支持 Schema Evolution,要读取的 DataFile 的 schema 和当前表的 schema 可能不匹配,因此需要做一个 Projection 来保证返回的数据的 Schema 和当前表的 Schema 相匹配。

二、Spark 引擎层和 Iceberg 对接
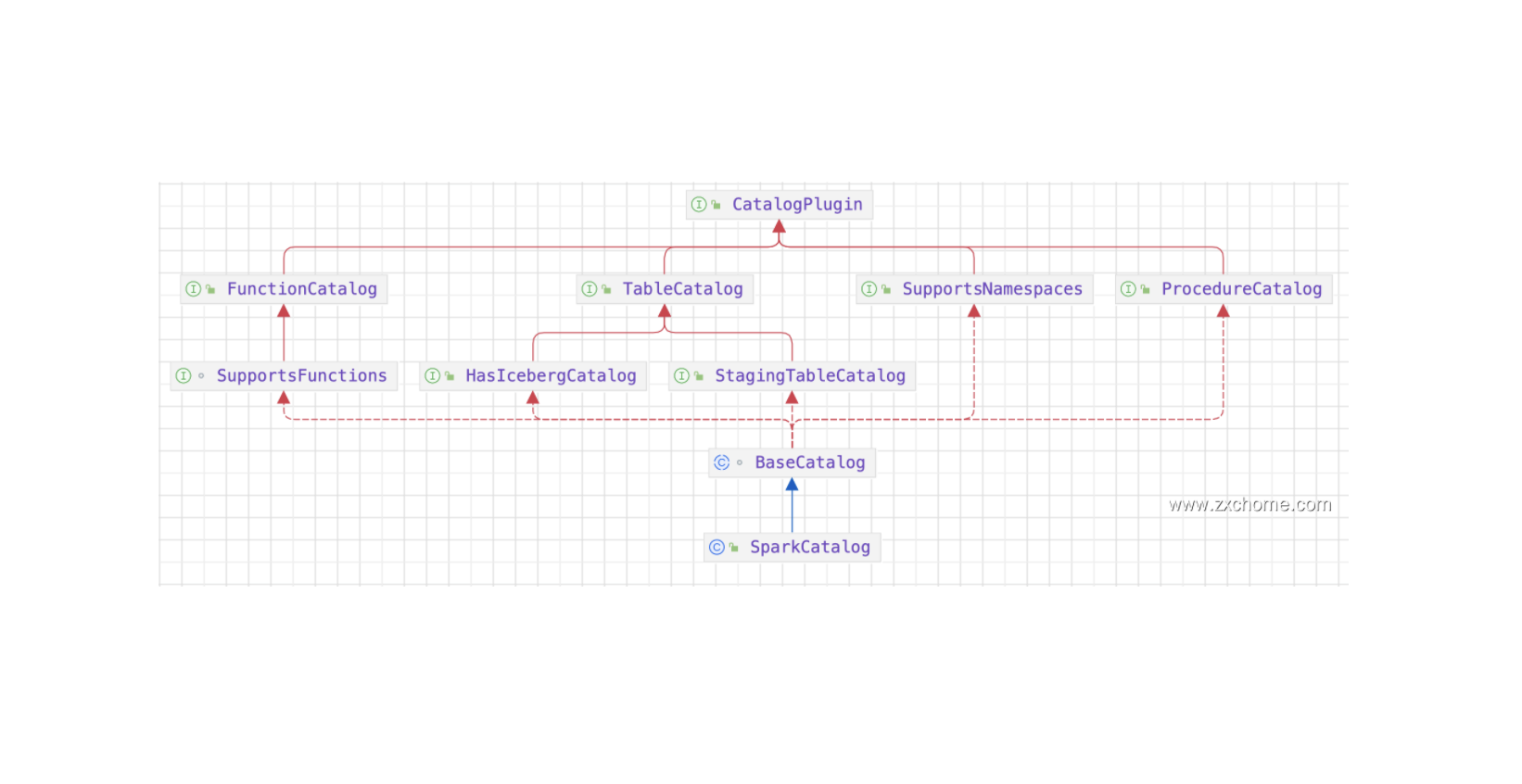
2.1. Catalog
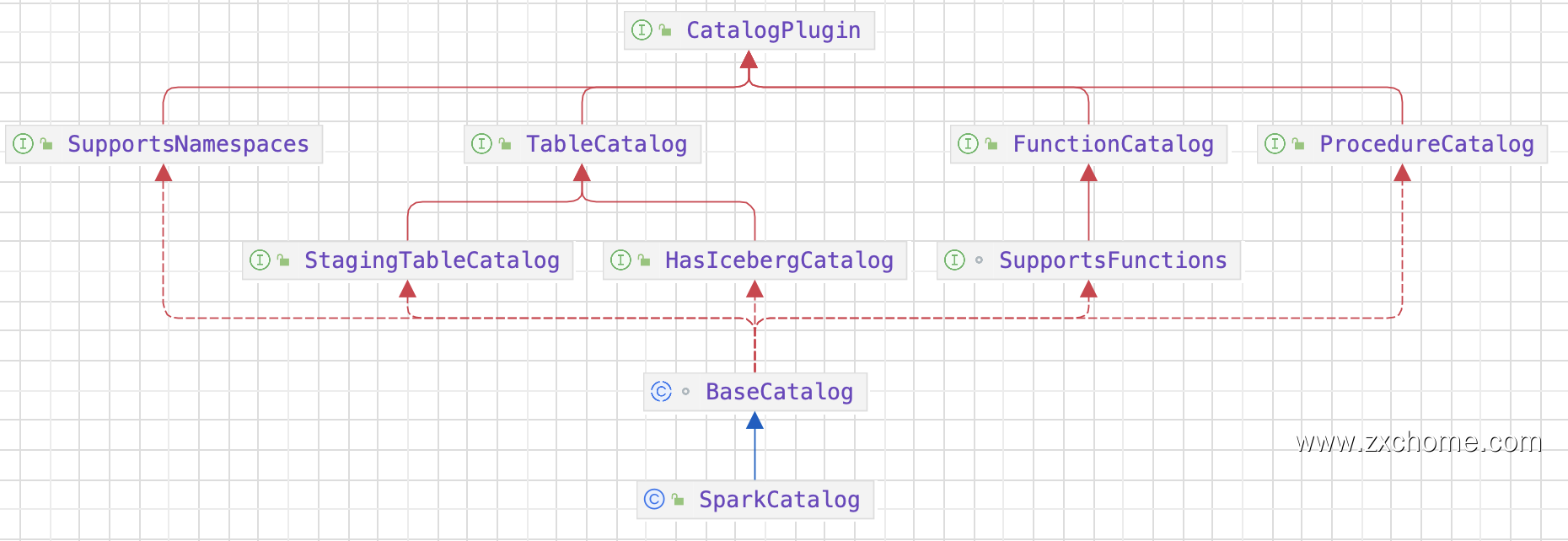
2.1.1. Spark Catalog API
2.1.2. Iceberg Catalog API
2.1.3. 集成
Iceberg 提供了 SparkCatalog,用于与 Flink 集成并管理 lceberg 表。FlinkCatalog 通过 Spark SQL 接口暴露 Iceberg表,使得用户可以使用 Spark SQL 查询和操作 Iceberg 表。

2.2. Spark DataSource V2
Data Source V2 API 是 Spark3 引入的一个重要特性,最早在 Spark 2.3 提出,在 Spark 3.0 被重新设计,具有非常良好的扩展性,使得 API 可以一直进化,每个版本都新增了大量的 API。

三、Table
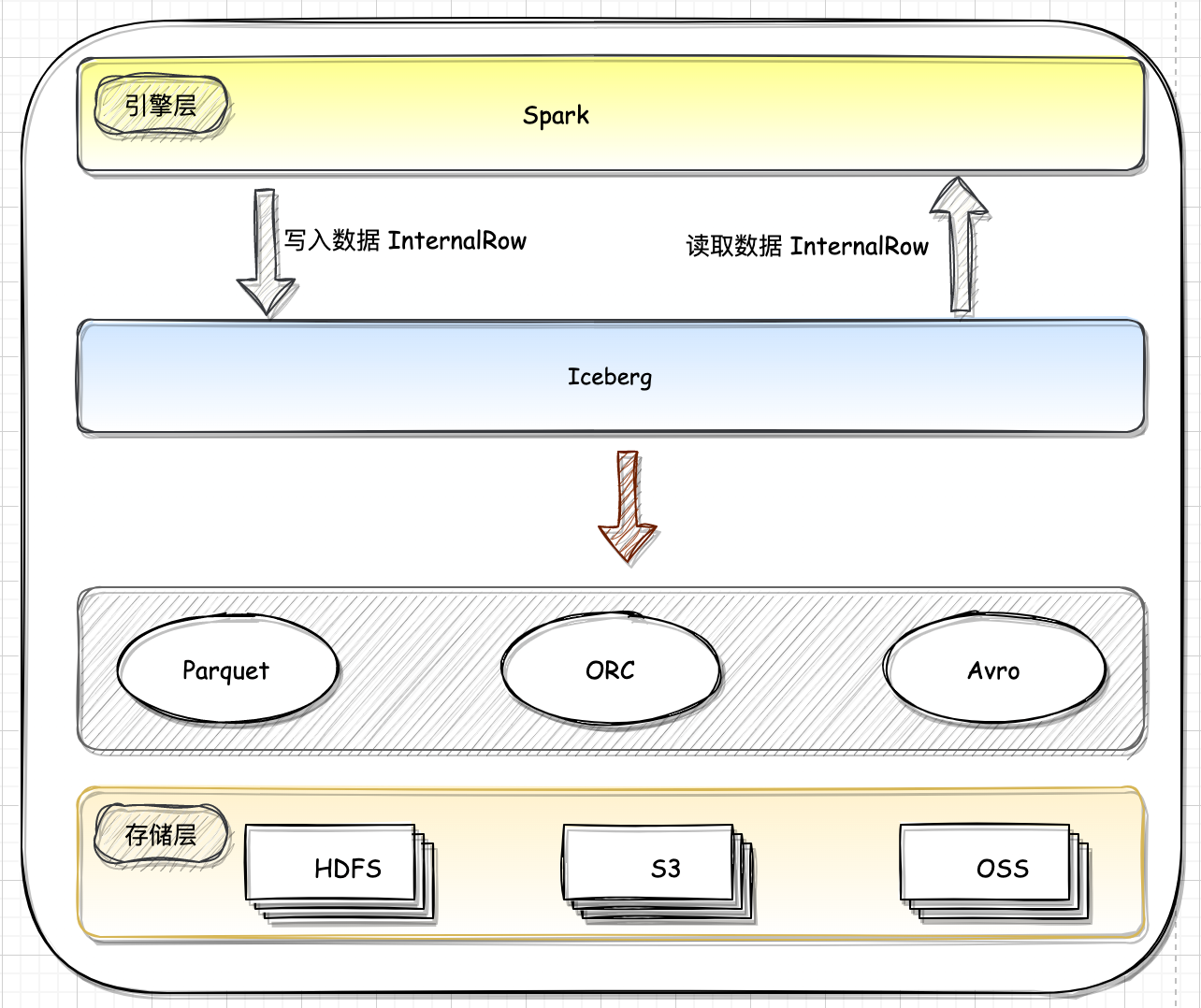
在 Iceberg 中,Table 接口代表 Iceberg 表格,提供了对 Iceberg Table 的元数据信息和数据文件的操作功能,使得用户可以更加方便地创建、更新、查询和读取表格中的数据。SparkTable 实现 Table 接口提供了一种通过 Spark 高效的处理数据湖 Iceberg 中的数据,包括读取和写入数据,以及执行 SQ L查询。
根据 Spark 规范,如果要让 Spark 读取数据,需要实现以下几个接口:
| Spark 接口 | Iceberg 实现类 | 描述 |
|---|---|---|
| org.apache.spark.sql.connector.catalog.SupportsRead | org.apache.iceberg.spark.source.SparkTable | 生成读取操作的ScanBuilder |
| org.apache.spark.sql.connector.read.ScanBuilder | org.apache.iceberg.spark.source.SparkScanBuilder | 创建表示读表的操作 Scan |
| org.apache.spark.sql.connector.read.Scan | org.apache.iceberg.spark.source.SparkBatchQueryScan | 生成 streaming/batch 对应的读操作 |
| org.apache.spark.sql.connector.read.Batch | org.apache.iceberg.spark.source.SparkBatchQueryScan | 读数据文件进行划分,然后生成数据文件的 reade |
| org.apache.spark.sql.connector.read.PartitionReaderFactory | org.apache.iceberg.spark.source.ReaderFactory | 创建出 Reader |
| org.apache.spark.sql.connector.read.PartitionReader | org.apache.spark.sql.connector.read.RowReader | 数据读取迭代器,返回的类型是 InternalRow |
Spark 在读取数据之前,需要为每个 Executor 分配数据文件,然后通过 Reader 读取数据文件。这两个接口都是在 org.apache.spark.sql.connector.read.Batch 实现的,创建 Batch 的步骤如下:
- Iceberg 的 SparkTable 实现了
SupportsRead的 $newScanBuilder$ 方法,创建出SparkScanBuilder SparkScanBuilder会创建出SparkBatchQueryScanSparkBatchQueryScan的 $toBatch$ 方法创建出表示 批操作的 Batch 对象- 通过
SparkBatchQueryScan的 $planInputPartitions$ 获取要读取的数据分片 - 通过
SparkBatchQueryScan, 生成 Reader 读取数据
四、生成数据分片
Spark 在读取数据之前,需要为每个 Executor 分配数据文件,然后通过 Reader 读取数据文件。这两个接口都是在 org.apache.spark.sql.connector.read.Batch 实现的,创建 Batch 的步骤如下:
Spark 引擎会调用 SparkBatchQueryScan 的 $planInputPartitions$ 方法,获取输入分片。
- SparkBatchQueryScan 表示普通的查询
- SparkMergeScan 用在需要数据合并的场景下
$planInputPartitions$ 方法 先调用的 $tasks$ 方法获取 CombinedScanTask,然后再封装成 ReadTask 返回给引擎。
ReadTask 实现了 InputPartition接口, 但 InputPartition 接口没有定义有用的方法,具体封装什么数据由ReadTask 决定。ReadTask 实际上封装的是每个数据文件的元信息,最终作为 Spark Reader 的输入。
五、数据读取
 微信
微信 支付宝
支付宝