Spark-源码学习-SparkCore-节点退役
一、概述
Spark 节点退役特性包括元数据操作(如将 Worker 从可调度资源列表中排除)以及数据迁移(Shuffle 文件和 RDD 块迁移)
https://www.waitingforcode.com/apache-spark/what-new-apache-spark-3.1-nodes-decommissioning/read
二、元数据操作
三、数据迁移
数据迁移入口: $CoarseGrainedExecutorBackend.decommissionSelf()$ 方法中。

首先,该方法会验证节点退役功能是否已启用,即 spask.decommission.enabled 的值是否为 true。此时,执行器还会检查它是否尚未运行退役进程。如果是,则在此阶段不会继续执行退役进程,而是让已启动的进程终止。
1 | if (!env.conf.get(DECOMMISSION_ENABLED)) { |
经过这两次检查后,执行器会将自己标记为退役状态,井启动数据迁移任务。同样,前提是使用 spark.storage.decommission.enabled 属性启用了该功能。如果是,执行器会向 BlockManager 发送 DecommissionBlockManager 消息。
BlockManagerDecommissioner 负责将退役的块管理器上的数据迁移到其他健康的节点上,以保证数据的可靠性和高可用性。确保集群在节点退役时能够正常运行。
- 扫描集群中的所有块管理器,检查它们的状态和健康状况,确定哪些块管理器需要退役。
- 对于需要退役的块管理器,从其上获取所有的数据块,以及与其他块管理器进行数据传输的相关信息
- 根据数据传输的相关信息,将数据块迁移到其他健康的块管理器上。迁移的过程可以采用多种方式,比如直接传输数据块,或者通过复制副本的方式。
- 在迁移完成后,更新块管理器的分大态,并通知其他相关组件(如任务调度器)
https://blog.csdn.net/LINBE_blazers/article/details/89893697
BlockManager 会对该消息做出反应,初始化 BlockManagerDecommissioner 并启动另一个自退役进程。
1 | decommissioned = true |
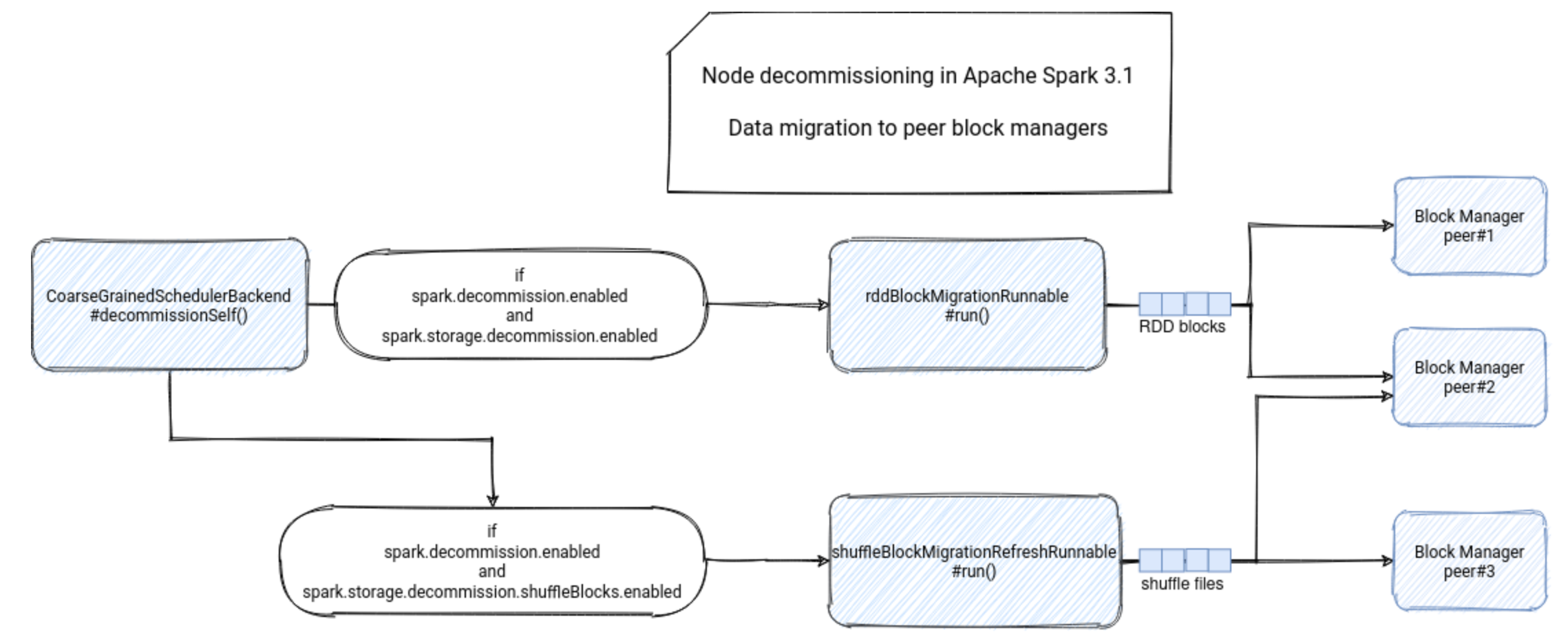
DecommissionBlockManager 调用 $start()$ 方法,将数据物理迁移到可用的对等块管理器。如果没有现有的对等块管理器,退役程序可以使用在 spark.storage.decommission.fallbackStorage.path 中启用的后备存储

3.1. Shuffle 文件迁移
3.2. RDD 块迁移
 微信
微信 支付宝
支付宝