数据湖-Iceberg-源码学习-Query Engines-Spark-读数据-集成-Catalog 设计
一、概述
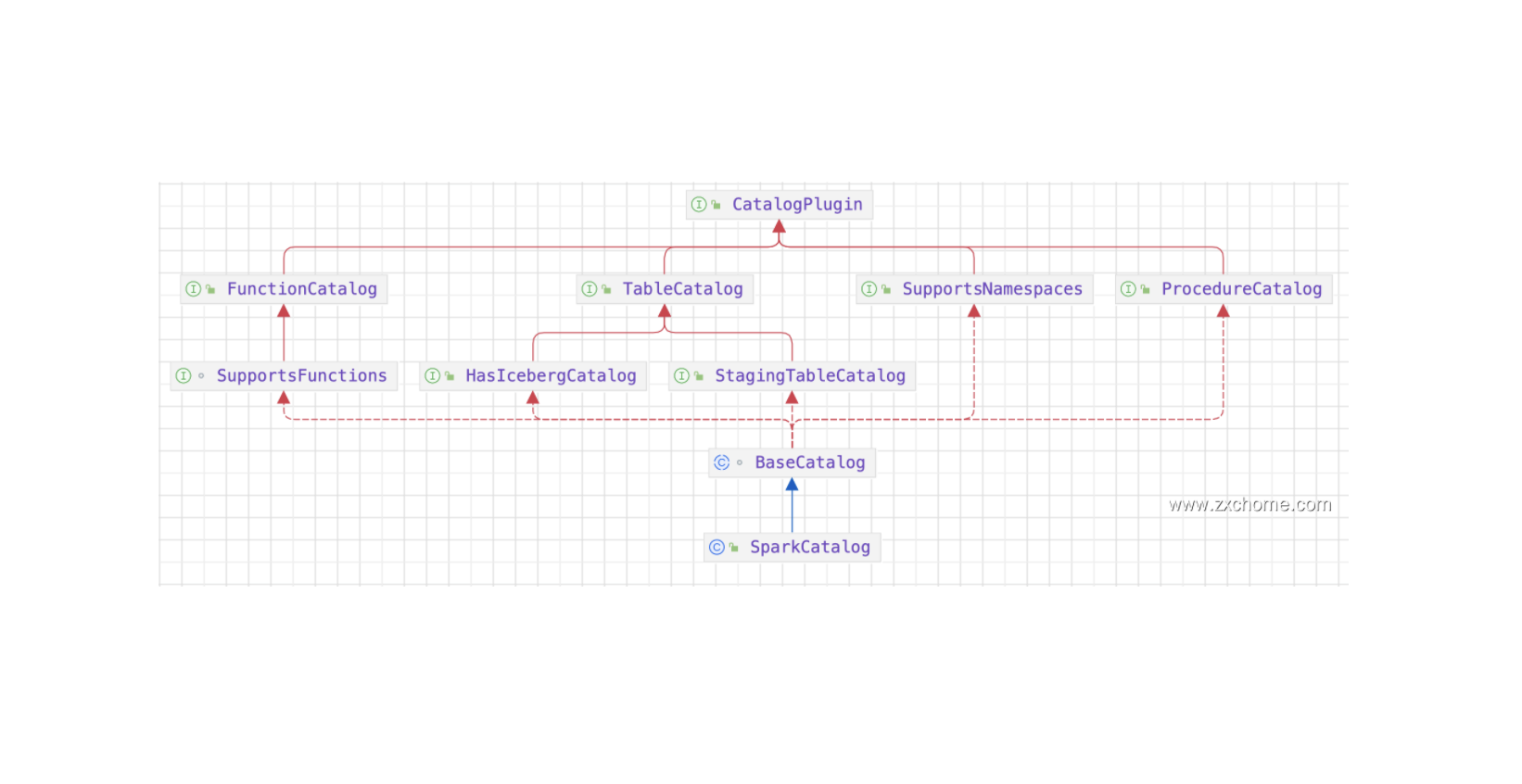
Iceberg 为了和 Spark 对接,实现了 Spark 关于 Catalog 规范。Catalog API 是 Iceberg 进行表管理 (create/drop/rename 等)的一个组件。目前 Iceberg 主要支持 HiveCatalog 和 HadoopCatalog 两种 Catalog。Iceberg 同时提供 Catalog 用良好的抽象来对接数挑存储和元数据管理。第三方存储可以实现 Iceberg 的 Catalog API 接口,跟 Iceberg 对接,组织管理元数据。
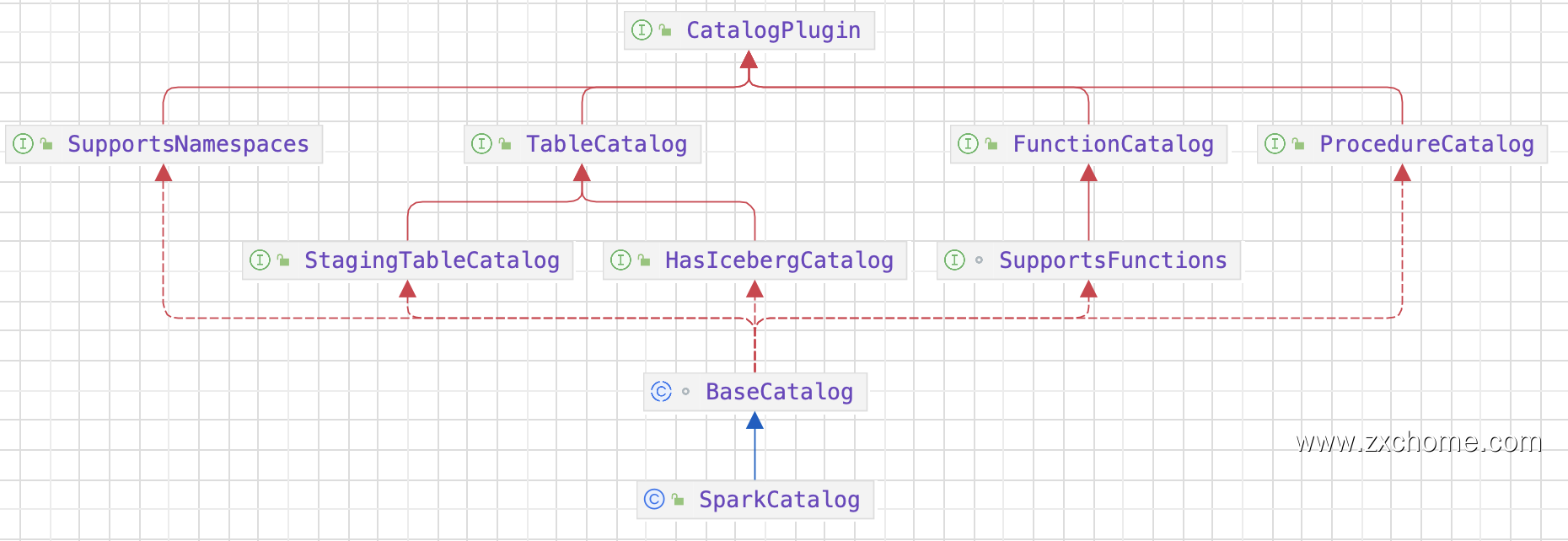
二、设计
2.1. 属性

2.2. 主要方法

2.2.1. loadTable()

2.2.2. createTable()
建表语句如下
1 | CREATE TABLE local.iceberg_db.table_demo( |
SparkSql 从建表SQL语句中解析出表名,表的 Schema (用StructType来表示),表的属性等信息信息,调用 Catalog 进行建表。在 Iceberg 的 SparkCatalog 中,会用 visitor 模式将 Spark 的 Schema 转换成 Iceberg 的Schema,然后通过 TableBuilder 去创建表。

BaseMetastoreCatalogTableBuider 首先会构建出 TableMetadata 然后交给 TableOperations 向底层 catalog进行提交。
HiveTableOperations commit 操作实际交给了 $doCommit$ 方法进行执行:

- 把元数据信息写入到存储中
初次建表只写 metadata.json 文件
- 生成 metadata.json 的存储路径
- 通过 FileIO 创建一个底层存储的文件,FileIO 是 iceberg 对底层存储的抽象
- 将 TableMetadata 对象的数据序列化成 JSON,然后存储在底层
将 Iceberg 的schema 转成 Hive metastore 表的数据结构
设置表 properties 属性
交给 HiveMetaStoreClient 进行持久化
Iceberg 将 Spark 传递下来的 Schema 信息转换成 TabelMetadata,然后将 TableMetadata 序列化成 JSON 保存在底层存储上。
这里发生过3次 schema 转换
第一次是 spark 解析SQL 语句转换成 StructType
Iceberg 将 StructType 转换成自己内部的 Schema
Iceberg 将schema,转换成底层 Catalog 的 Schema
 微信
微信 支付宝
支付宝