数据湖-Iceberg-源码学习-Query Engines-Spark-写数据
一、概述
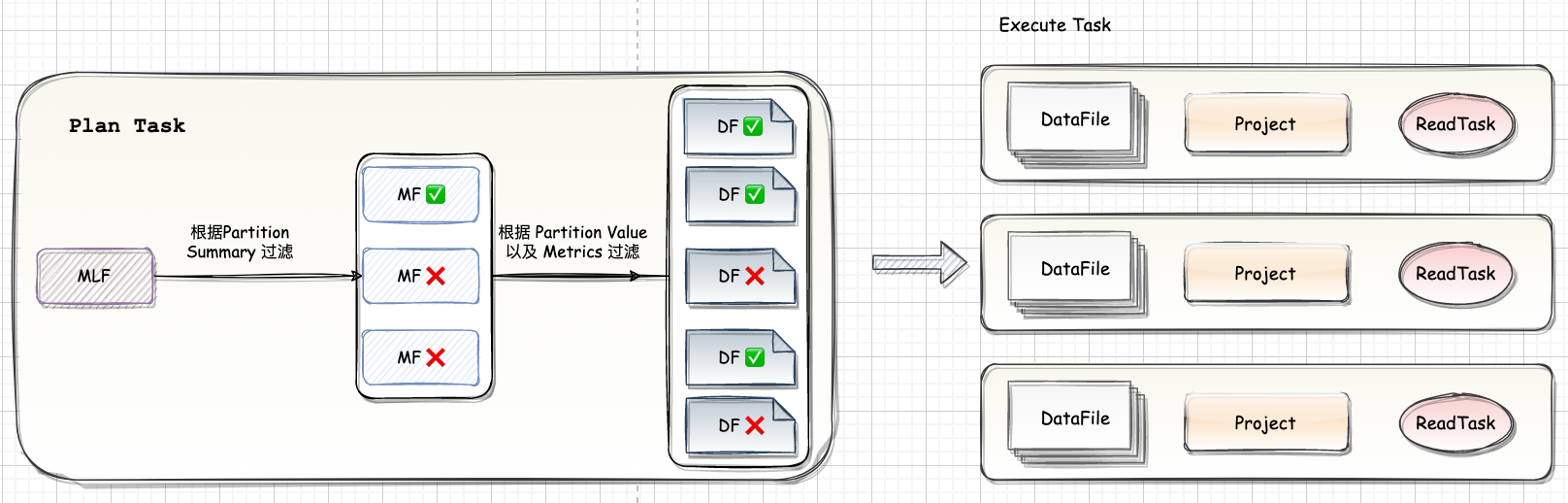
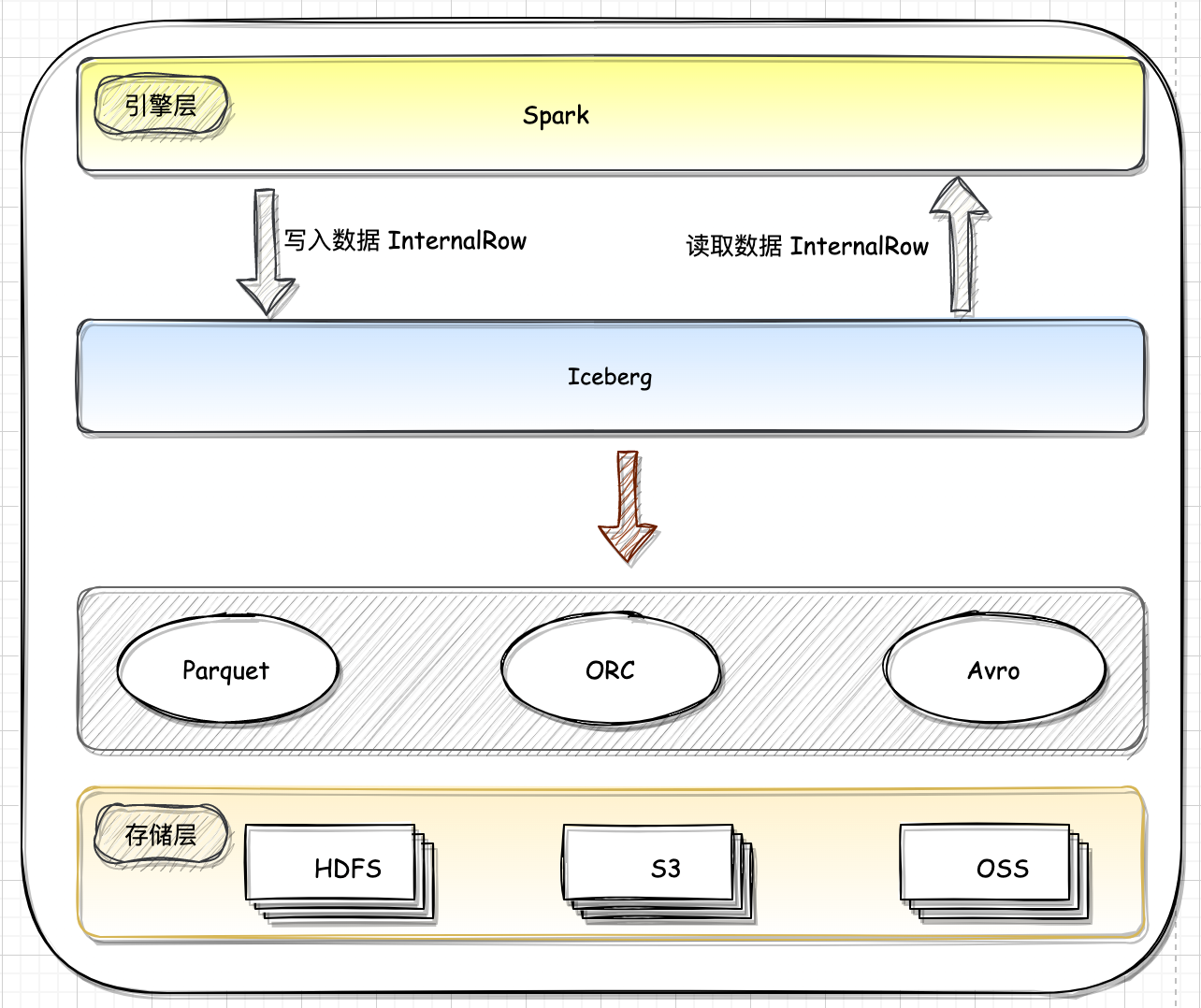
Iceberg 定位是计算引擎之下,存储之上的开放表格式 Table Format,总体上 Spark 写入 Iceberg 可以分为两步: Spark 从 数据源读取 Source 数据,切分成多个 Task,每个 Task 会根据设置生成一个或者多个 DataFile;
Task 的返回结果就是一个或者多个 DataFile 结构。
Spark Driver 在收集到所有的 DataFile 后,首先将多个 DataFile 结构写入到一个 ManiestFile 里,然后生成一个由多个 ManifestFile 组成的 Snapshot 并 Commit 到 Catalog。

数据写入 Write
Spark 引擎层调用接口将数据往下发,Iceberg 接受数据,将数据按照指定的格式写入对应的存储中。
数据提交 Commit
Spark 数据写入完成时,Iceberg 按照自己的表规范生成对应的元数据文件。
二、Spark 引擎层和 Iceberg 对接
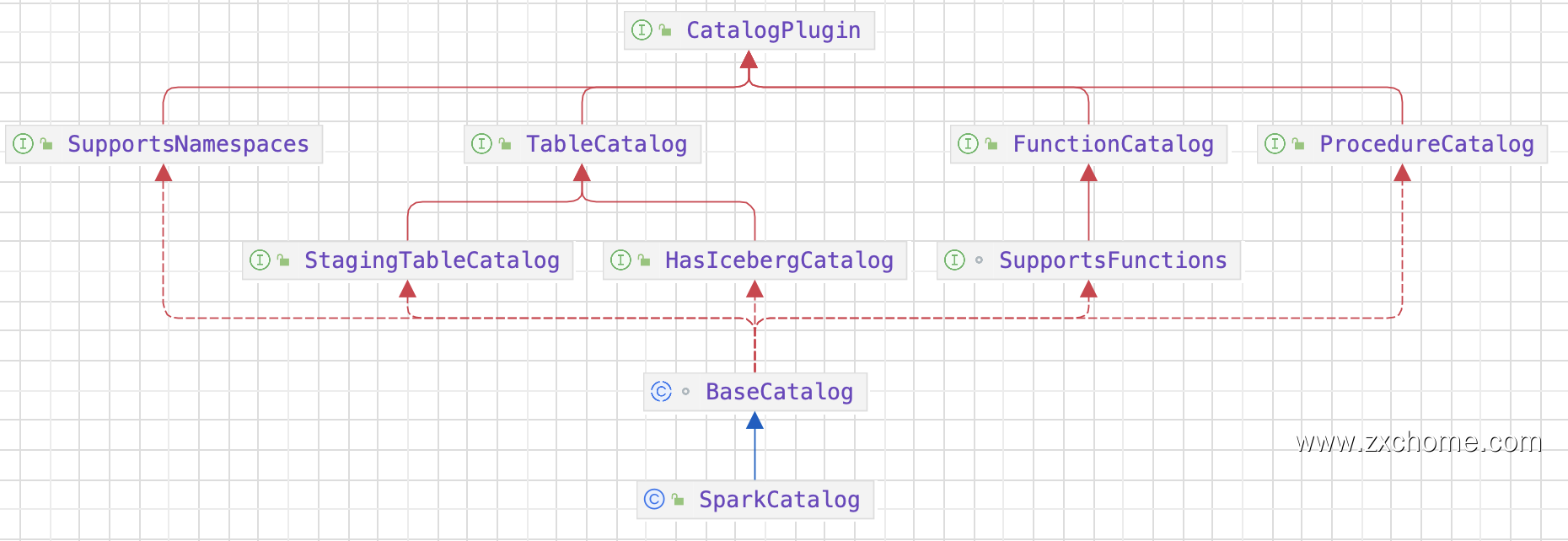
2.1. Catalog
2.1.1. Spark Catalog API
2.1.2. Iceberg Catalog API
2.1.3. 集成
Iceberg 提供了 SparkCatalog,用于与 Flink 集成并管理 lceberg 表。FlinkCatalog 通过 Spark SQL 接口暴露 Iceberg表,使得用户可以使用 Spark SQL 查询和操作 Iceberg 表。

2.2. Spark DataSource V2
Data Source V2 API 是 Spark3 引入的一个重要特性,最早在 Spark 2.3 提出,在 Spark 3.0 被重新设计,具有非常良好的扩展性,使得 API 可以一直进化,每个版本都新增了大量的 API。

三、创建表 Table
SparkSQL 从建表 SQL 语句中解析出表名,表的 Schema,表的属性等信息信息,调用 Catalog Api 进行建表。
1 | CREATE TABLE local.iceberg_db.table_demo ( |
https://zhuanlan.zhihu.com/p/454151753
Iceberg 中的 SparkTable 是与 Spark 集成的 Iceberg 表。SparkTable 通过 SparkCatalog 接口暴露给 Spark,可以被视为一个普通的 Spark DataFrame 对象。SparkTable 中 $newWriteBuilder$ 方法创建出 SparkWriteBuilder
SparkWriteBuilder 实现了 Spark 中的 WriteBuilder 接口,生成 batch/streaming 对应的 writer。
Datawriter 口定义了 Spark 引|擎层如何将数据一条一条往下游写,在写入完成之后便可以进行 commit
四、Executor 数据写入
Unpartitioned3Writer 实现了 spark 的 DataWriter 接口,将 write 委托给了 FileWriter
在 $SparkParquetWriters.buildWriter$ 使用访问者模式 创建 ParquetValueWriter 时,会生成每一列数据类型对应的的 Writer 传递给 InternalRowWriter 的构造方法,这样 InternalRowWriter 就拥有了每一列对应的 ParquetValueWriter,在对数据进行写入时通过InternalRowWriter 便可以对 Spark 传递下来的一行数据拆解成列存,写入 parquet 文件中。
至此已经获取到文件写入的信息,等待所有 Exector 写入结束,Iceberg 便可提交元数据。

4.1. Executor 写入数据
4.1.1. 返回
Spark 从 数据源读取 Source 数据,切分成多个 Task,每个 Task 会根据设置生成一个或者多个 DataFile;
Task 的返回结果就是一个或者多个 DataFile 结构。

五、Driver 元数据提交
commitOperation()

最终调用 $PendingUpdate.commit$~
 微信
微信 支付宝
支付宝