
Spark-源码学习-架构设计-DataSource 体系-加载数据
一、概述
1 | val df: DataFrame = spark.read.format("jdbc") |
二、read()
创建 DataFrameReader 对象,进行数据读取任务。
1 | def read: DataFrameReader = new DataFrameReader(self) |
DataFrameReader 用于从外部数据源加载数据到 DataFrame 中。它支持多种格式,如 JSON,CSV,Parquet,JDBC 等
三、load()
在 Spark 中调用 load() 触发加载数据源操作。
3.1. 配置项 pathOptionBehavior
spark.sql.legacy.pathOptionBehavior.enabled 用于控制在使用 spark.sql() 或 spark.catalog() 时,是否使用绝对路径或相对路径来指定表或视图。
该配置项的默认值是
true意味着使用 spark.sql() 等 API 时,使用相对路径来指定表或视图(相对于当前数据库的路径)。当将此配置设置为false时,将使用绝对路径来指定表或视图(无论当前的数据库是什么)
1 | def load(paths: String*): DataFrame = { |
3.2. 查找数据源
3.2.1. lookupDataSource()
查找数据源时,首先从内置数据源中 backwardCompatibilityMap 进行查找,查找失败时,以输入的数据源类路径加类名 . DefaultSource 构建出数据源实例。
1 | val cls = lookupDataSource(provider, conf) |
创建
provider1从 backwardCompatibilityMap 获取 provider 所对应的默认的 DataSourceProvider 的全类名。如果 provider 为 jdbc、json、parquet、orc 等相关的全类名,则可直接返回对应的 DataSourceProvider 的全类名,否则返回 provider 本身。
1
2
3
4
5
6
7
8
9
10
11
12private val backwardCompatibilityMap: Map[String, String] = {
val jdbc = classOf[JdbcRelationProvider].getCanonicalName
val json = classOf[JsonFileFormat].getCanonicalName
val parquet = classOf[ParquetFileFormat].getCanonicalName
// ...
Map(
"org.apache.spark.sql.jdbc" -> jdbc,
"org.apache.spark.sql.jdbc.DefaultSource" -> jdbc,
"org.apache.spark.sql.execution.datasources.jdbc.DefaultSource" -> jdbc,
//...
)
}创建
provider21
val provider2 = s"$provider1.DefaultSource"
以数据湖 Hudi 为例: provider1 =
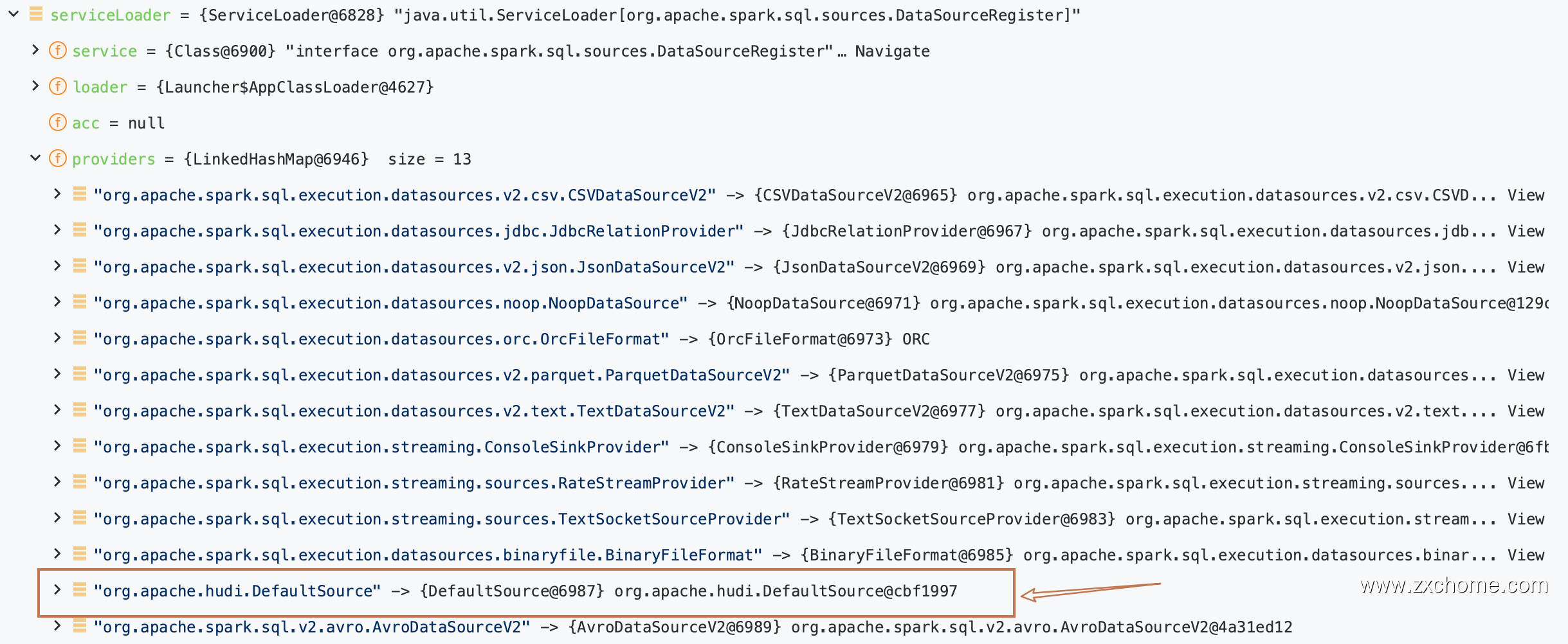
hudi; provider2 =hudi.DefaultSource使用 ServiceLoader 加载所有继承 DataSourceRegister 的类,得到 serviceLoader
1
val serviceLoader = ServiceLoader.load(classOf[DataSourceRegister], loader)
获取 getContextOrSparkClassLoader
1
val loader = Utils.getContextOrSparkClassLoader
搜索 DataSource
provider1不是 shortName,则使用 SparkClassLoader 加载 provider1,失败则加载 provider21
2
3
4
5
6
7
8case Nil =>
try {
Try(loader.loadClass(provider1)).orElse(Try(loader.loadClass(provider2))) match {
case Success(dataSource) =>
dataSource
case Failure(error) =>
...
}provider1 是 shortName,则直接返回其对应的 DataSource Class。
1
2case head :: Nil =>
head.getClass // org.apache.hudi.DefaultSource
3.2.2. lookupDataSourceV2()
获取 useV1Sources
1
2
3
4
5
6
7
8
9
10val useV1Sources = conf.getConf(SQLConf.USE_V1_SOURCE_LIST).toLowerCase(Locale.ROOT).split(",").map(_.trim)
val USE_V1_SOURCE_LIST = buildConf("spark.sql.sources.useV1SourceList")
.internal()
.doc("A comma-separated list of data source short names or fully qualified data source " +
"implementation class names for which Data Source V2 code path is disabled. These data " +
"sources will fallback to Data Source V1 code path.")
.version("3.0.0")
.stringConf
.createWithDefault("avro,csv,json,kafka,orc,parquet,text")lookupDataSource()
调用 lookupDataSource() 查找数据源 cls
校验 cls
1
2
3
4
5cls.newInstance() match {
case d: DataSourceRegister if useV1Sources.contains(d.shortName()) => None
case t: TableProvider if !useV1Sources.contains(cls.getCanonicalName.toLowerCase(Locale.ROOT)) => Some(t)
case _ => None
}
3.3. 加载数据源
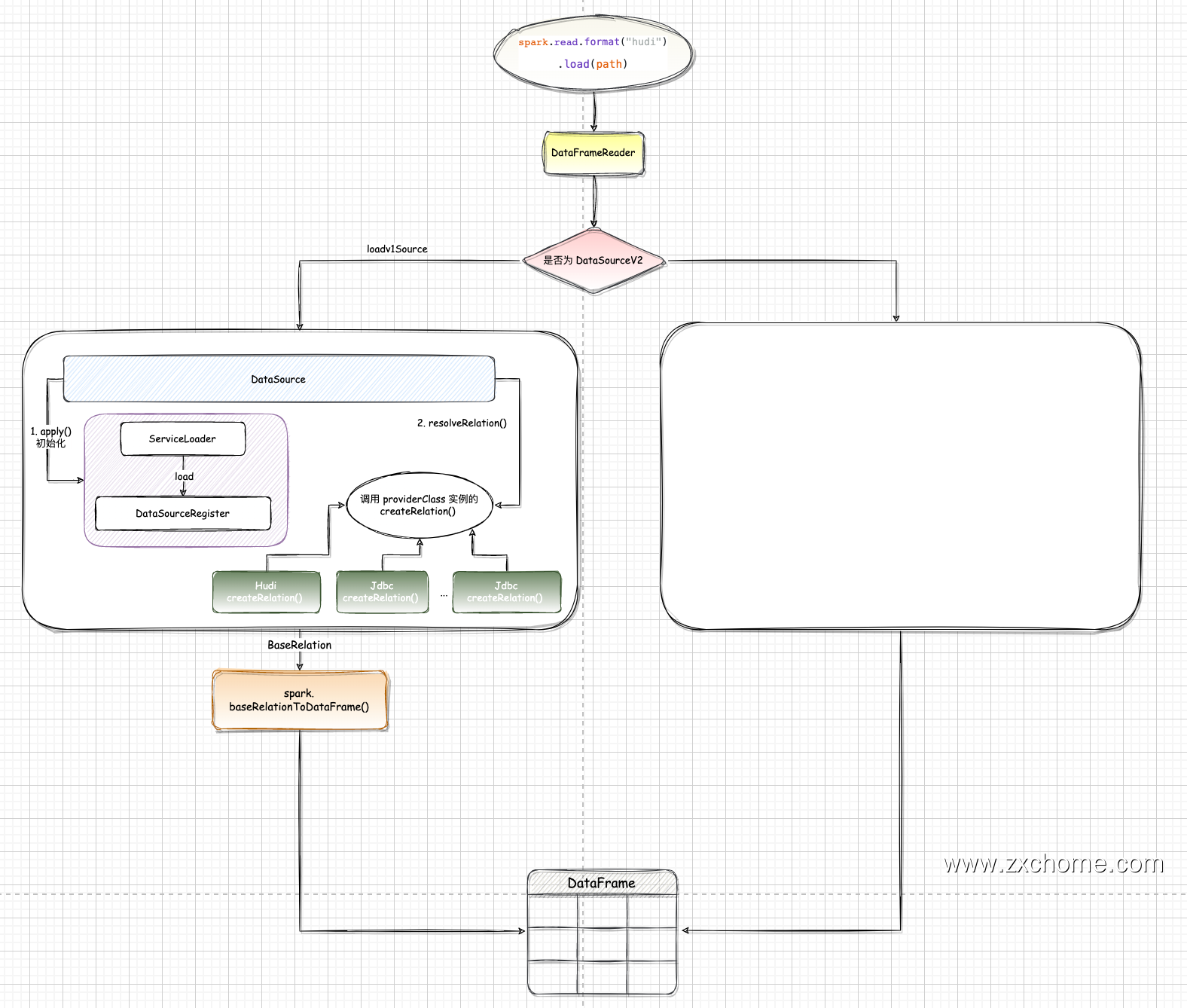
为了保证代码的兼容性,Spark 会先尝试加载一次实现类,判断是否为 DataSourceV2,如果不是则使用 loadV1Source() 方法继续加载实现类。
3.3.1. V2
1 | DataSourceV2Utils.loadV2Source(sparkSession, provider, userSpecifiedSchema, extraOptions,source, paths: _*) |
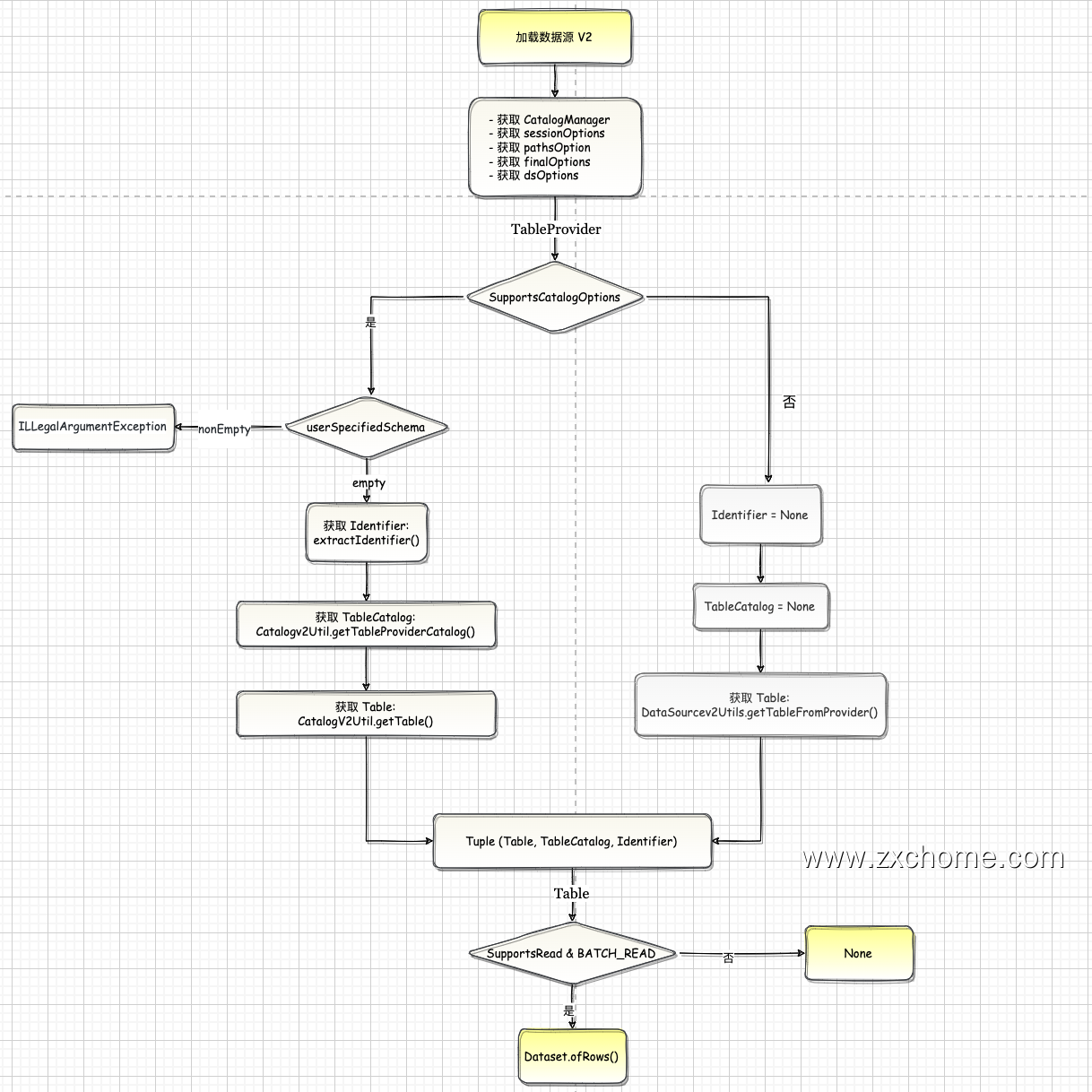
获取 Tuple (Table, TableCatalog, Identifier)
SupportsCatalogOptions
userSpecifiedSchema.nonEmpty
1
2throw new IllegalArgumentException(
s"$source does not support user specified schema. Please don't specify the schema.")userSpecifiedSchema.empty
Identifier: extractIdentifier()
TableCatalog: CatalogV2Util#getTableProviderCatalog()
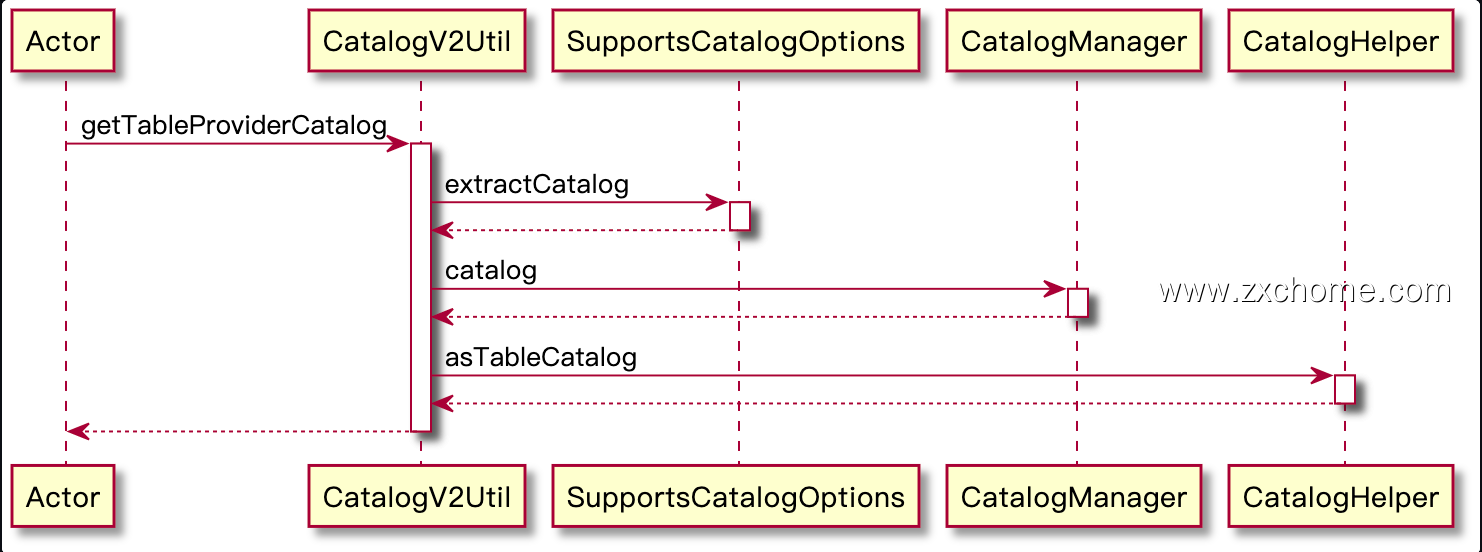
Table: CatalogV2Util.getTable()
other
- Identifier: None
- TableCatalog: None
- Table: DataSourceV2Vtils#getTableFromProvider()
加载数据
SupportsRead &
BATCH_READ: DataSet#ofRows()1
Dataset.ofRows(sparkSession, DataSourceV2Relation.create(table, catalog, ident, dsOptions))
other: 加载数据源 V1
3.3.2. V1
Spark 在 loadV1Source() 中调用 DataSource 的 apply() 进行初始化,并调用其 resolveRelation() 方法创建 BaseRelation,然后通过 SparkSession 创建 DataFrame 返回。
1 | loadV1Source(paths: _*) |
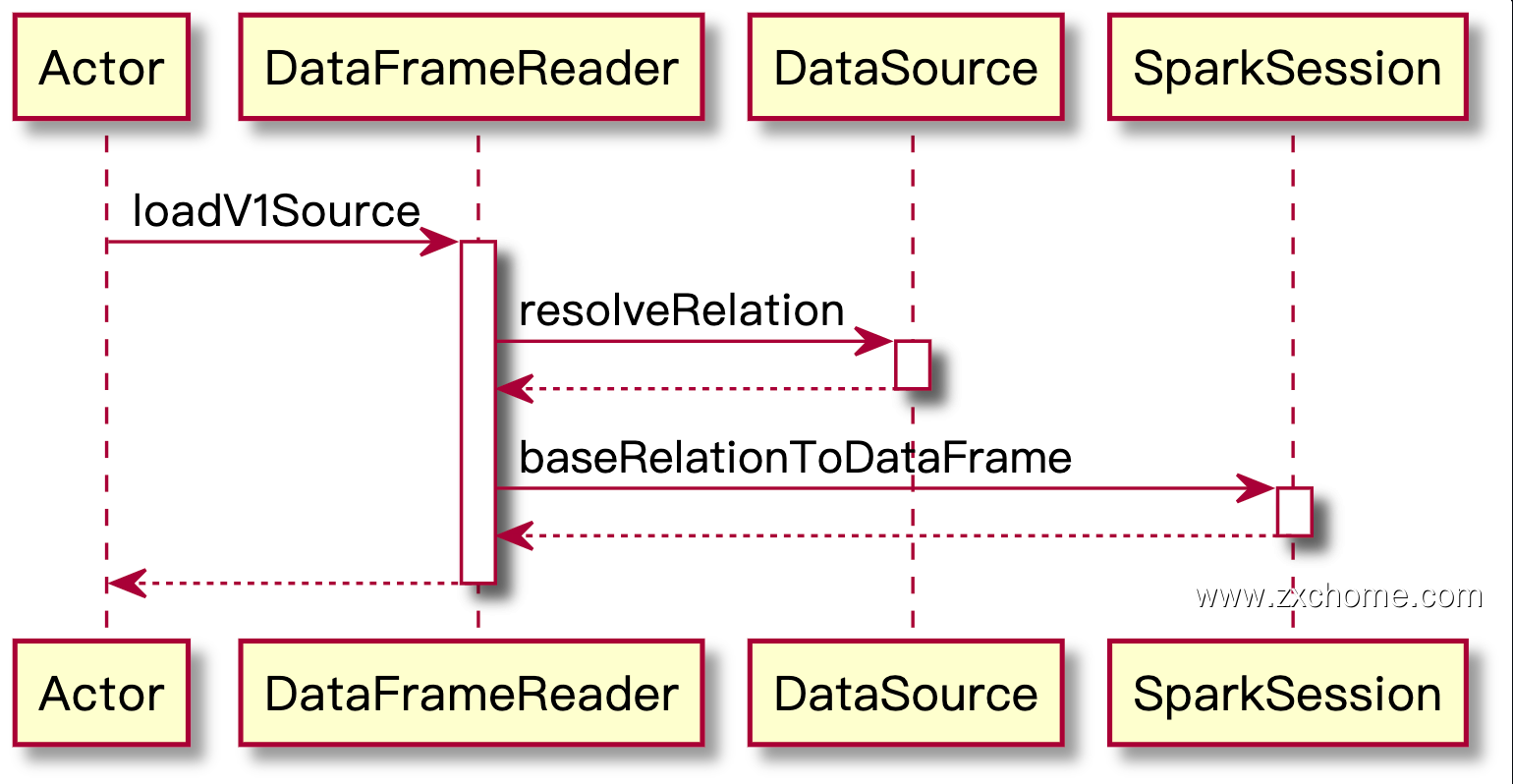
DataSource.apply()
通过 apply() 初始化 DataSource。
1
2
3
4
5
6
7
8
9sparkSession.baseRelationToDataFrame(
DataSource.apply(
sparkSession,
paths = finalPaths,
userSpecifiedSchema = userSpecifiedSchema,
className = source,
options = finalOptions.originalMap
).resolveRelation()
)解析 Relation: DataSource#resolveRelation()
providingInstance()
主要操作是调用 DataSource#lookupDataSource() 方法查找数据源,根据 SPI (再次)扫描 DataRegister 实现类
1
2
3
4
5
6
7
8private[sql] def providingInstance(): Any = providingClass.getConstructor().newInstance()
lazy val providingClass: Class[_] = {
val cls = DataSource.lookupDataSource(className, sparkSession.sessionState.conf)
cls.newInstance() match {
case f: FileDataSourceV2 => f.fallbackFileFormat
case _ => cls
}
}match{}
DataSource#lookupDataSource() 返回的为
Spark32PlusDefaultSource,它的父类 DefaultSource 既实现了 SchemaRelationProvider 也实现了 RelationProvider, 但是这里的 userSpecifiedSchema 为 None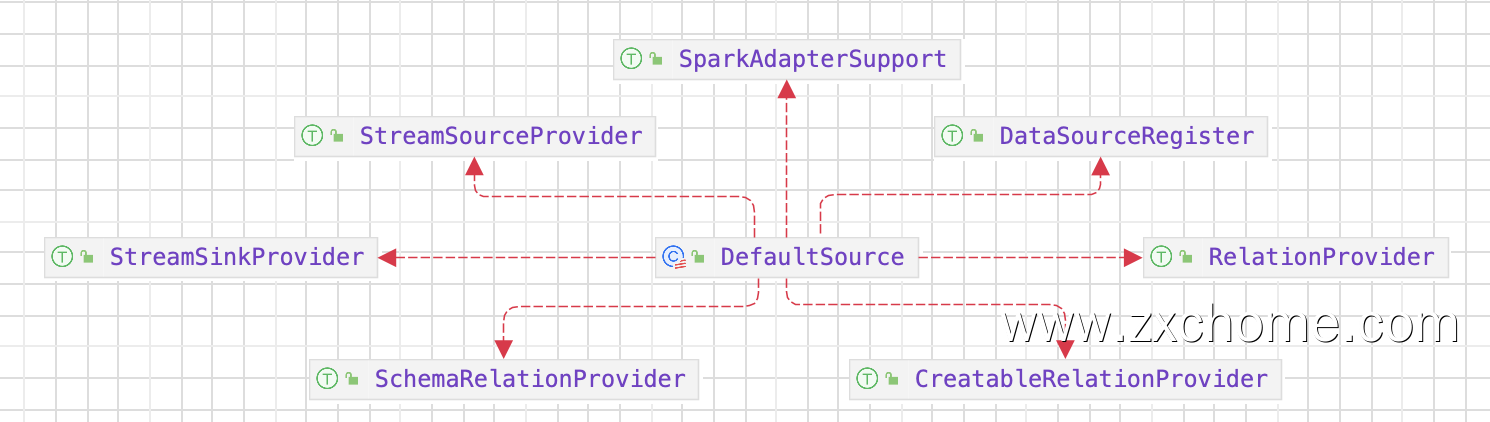
createRelation() 在 自定义实现的数据源中实现~
SparkSession#baseRelationToDataFrame()
SparkSession#baseRelationToDataFrame() 方法将 BaseRelation 转换为 DataFrame。
1
2
3def baseRelationToDataFrame(baseRelation: BaseRelation): DataFrame = {
Dataset.ofRows(self, LogicalRelation(baseRelation))
}
 微信
微信 支付宝
支付宝








