
Spark-源码学习-SparkSQL-SQL 语句的执行过程
一、概述
在典型的 Spark SQL 应用场景中,数据的读取、数据表的创建和分析都是必不可少的过程。通常来讲,SparkSQL 查询所面对的数据模型以关系表为主。
如图所示的案例显示了使用 SparkSQL 进行数据分析的一般步骤。
二、流程
2.1. 创建 SparkSession
从 2.0 版本开始,SparkSession 逐步取代 SparkContext 成为 Spark 应用程序的入口,SparkSession 内封装了 SparkConf、SparkContext 和 SQLContext 等。
1 | val spark: SparkSession = SparkSession.builder() |
2.2. 加载数据源
1 | val df: DataFrame = spark.read.format("jdbc") |
2.3. 创建临时表
创建临时表或者视图,向 SessionCatalog 注册元数据
1 | df.createOrReplaceTempView("satcat") |
2.3.1. 初始化 CreateViewCommand
存放临时视图的元数据信息
1 | def createOrReplaceTempView(viewName: String): Unit = withPlan { |
1 | private def withPlan(logicalPlan: LogicalPlan): DataFrame = { |
2.3.2. $withPlan$
1 | private def withPlan(logicalPlan: LogicalPlan): DataFrame = { |
2.4. SQL->RDD
1 | spark |
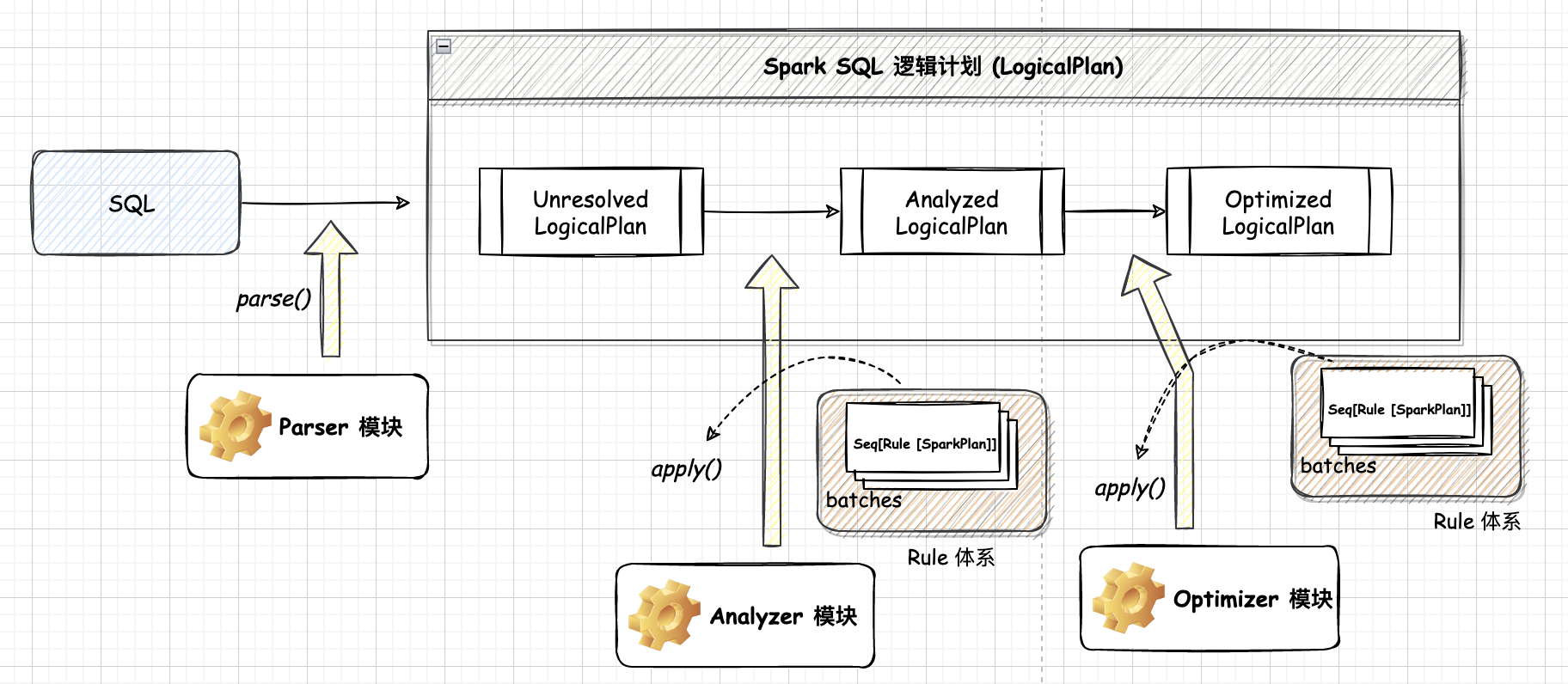
一般来讲,对于 Spark SQL 系统,从 SQL到 Spark 中 RDD 的执行需要经过两个大的阶段,分别是選辑计划 (LogicalPlan)和物理计划 (PhysicalPlan)
2.4.1. $SparkSession.sql$
在 $sql$ 中会进行 SQL->RDD 的逻辑计划阶段,逻辑计划阶段会将用户所写的 SQL 语句转换成树型数据结构(逻辑算子树),SQL 语句中蕴含的逻辑映射到逻辑算子树的不同节点。
1 | def sql(sqlText: String): DataFrame = withActive { |
逻辑计划阶段生成的逻辑算子树并不会直接提交执行,仅作为中间阶段。
2.4.2. $show$
在 $spark.show $ 中会进行 SQL->RDD 的逻辑计划阶段的 Optimizer 以及物理计划阶段,物理计划阶段将上一步逻辑计划阶段生成的逻辑算子树进行进一步转换,生成物理算子树。物理算子树的节点会直接生成 RDD 或对 RDD 进行 transformation 操作

每个物理计划节点中都实现了对 RDD 进行转换的 execute 方法。
同样地,物理计划阶段也包含3个子阶段:
生成物理算子树的列表
根据逻辑算子树,生成物理算子树的列表 Iterator[PhysicalPlan](同样的逻辑算子树可能对应多个物理算子树)
选取最优的物理算子树
从列表中按照一定的策略选取最优的物理算子树(SparkPlan)
最后,对选取的物理算子树进行提交前的准备工作,例如,确保分区操作正确、物理算子树节点重用、执行代码生成等,得到“准备后”的物理算子树(Prepared SparkPlan)。经过上述步骤后,
1 | private def withAction[U](name: String, qe: QueryExecution)(action: SparkPlan => U) = { |
来到 $QueryExecution.executedPlan$~
 微信
微信 支付宝
支付宝







