
Spark-源码学习-SparkSQL 系列
一、执行环境
Spark2.0 中引入了 SparkSession 的概念,为用户提供了一个统一的切入点来使用 Spark 的各项功能。
在 Spark 的早期版本,SparkContext 是进入 Spark 的切入点。RDD 的创建和操作得使用 SparkContext 提供的API; 对于 RDD 之外的其他东西,需要使用其他的 Context。
比如流处理使用 StreamingContext; 对于 SQL 得使用 SQLContext; 而对于 Hive 得使用 HiveContext。然而当 Dataset 和 DataFrame 提供的 API 逐渐成为新的标准 API,Spark 需要一个切入点来构建它们,在 Spark 2.0 中引入一个新的切入点: SparkSession。
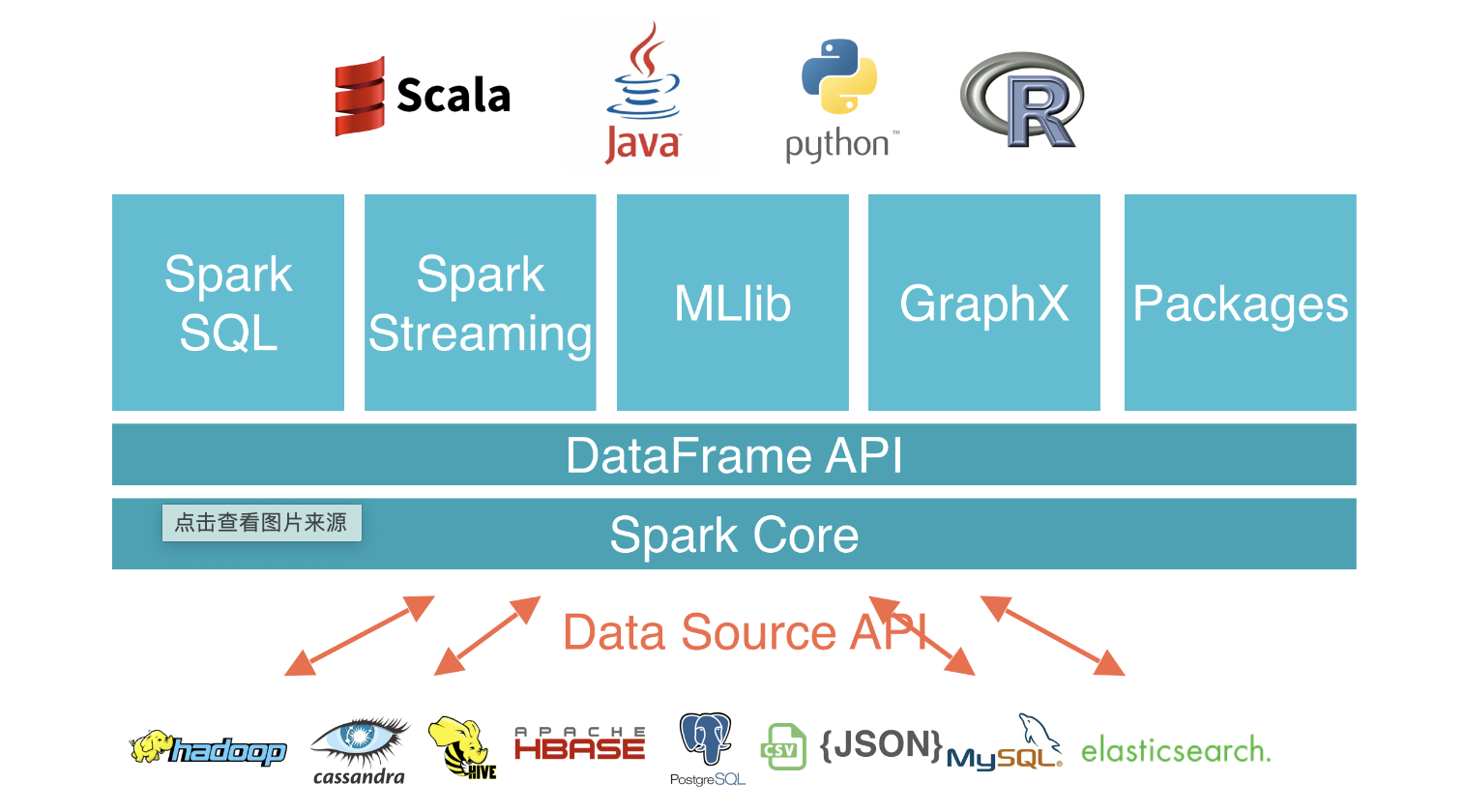
二、数据源体系
Spark DataSource 是一个 Spark 的数据连接器,可以通过该连接器进行外部数据系统的读写操作。Spark DataSource包含两部分,分别是 Reader 和 Writer。
Spark DataSource API 类似于 Flink 的 connector API
三、元数据体系
在 Spark SQL 系统中,Catalog 主要用于各种函数资源信息和元数据信息(数据库、数据表、数据视图、数据分区与函数等)的统一管理。Spark SQL 的 Catalog 体系涉及多个方面。
四、SQL 引擎
应用程序的 SQL 语句需要经过SQL解析生成逻辑执行计划、经过查询优化生成物理执行计划,然后将物理执行计划转交给查询执行引|擎做物理算子的执行操作。SQL 解析通常包含词法分析、语法分析、语义分析几个子模块。SQL 是介于关系演算和关系代数之间的一种描述性语言,它吸取了 关系代数中一部分逻辑算子的描述,而放弃了关系代数中“过程化”

五、总结
5.1. SQL 执行
一条聚合 SQL 语句的执行过程~
引用本站文章Spark-源码学习-SparkSQL-一条聚合 SQL 语句的执行过程~Joker一条连接 SQL 语句的执行过程~
引用本站文章Spark-源码学习-SparkSQL-一条连接 SQL 语句的执行过程~Joker
 微信
微信 支付宝
支付宝







