












Flink-源码学习-元数据体系-Catalog-CatalogManager
一、概述CatalogManager 用来管理 Catalog,且可以同时管理多个 Catalog。也就是说,可以通过在一个相同 SQL 中,跨 Catalog 做查询或者关联操作。
在一个 Flink Session 当中,是可以创建多个 Catalog ,每一个 Catalog 对应于一个外部系统。用户可以在 Flink Table API 或者如果使用的是 SQL Client 的话,可以在 Yaml 文件里指定定义哪些 Catalog 。然后在 SQL Client 创建 TableEnvironment 的时候,就会把这些 Catalog 加载起来。TableEnvironment 通过CatalogManager 来管理这些不同的 Catalog 的实例。这样 SQL Client 在后续的提交 SQL 语句的过程中,就可以使用这些 Catalog 去访问外部系统的元数据了。
Flink在创建运行环境时会同时创建一个CatalogManager,用来管理不同的 Catalog 实例,
https://developer.aliyun.com/article/752539 ...

Spark-源码系列
一、架构设计Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark 是 UC Berkeley AMP lab(加州大学伯克利分校的AMP实验室)所开源的类 Hadoop MapReduce 的通用并行框架。
引用本站文章
Spark-理论笔记-架构设计
Joker
二、阅读环境准备
引用本站文章
Spark-源码学习-阅读环境搭建
Joker
三、集群启动Spark 采用了分布式架构的 master一slave 模型
引用本站文章
...

数据湖-Iceberg-源码学习-Kernal-Table-数据操作-Upsert
一、概述Hudi 在处理 Upsert 请求时,会有一个 tagging 过程,主要是给每条数据打标,标明这条数据是 insert 还是 update。这个标签起到以下作用:
对于 insert 的数据,Hudi 会写入新的 base 文件
对于 update 的数据,Hudi 会写入新的 delta 文件,文件名使用原数据的 fileId
Hudi 为了快速地确定每条数据到底是 insert 还是 update,减少 tagging 的时间,还引入了索引机制。索引支持三种不同的类型,但每一种类型或多或少都会带来一些成本,或是影响写入性能,或是增加维护成本。
Iceberg 没有 tagging 过程,也无需外部中间件作为索引,但相应的,Iceberg 的 update 和 delete 并不确定想要更新或删除的记录是否存在,无论如何都会在 DeleteFile 里追加一条 delete 记录,至于这条记录是否真的存在,只有在读取时做合并后才知道。
本质上相当于把 tagging 的过程放在了读取阶段,尽管减少了写入时的成本,但会影响读取的效率。
二、实现2.1. upda ...

数据湖-Iceberg-源码学习-Kernel-Table Format-数据写入
一、概述如图所示,Iceberg 在数据写入的时候:
Iceberg 先把数据写入到 DataFile 文件中
当一组 DataFile 文件写完之后,会根据这个 DataFile 文件中 column 的一些统计信息(如: 每个 column 的 min/max 值),生成一个对应的 manifest 文件
然后 Iceberg 把一次写入后涉及到的 manifest 文件组成一个 manifest list, manifest list 文件中也会存入一些相 manifest 的统计信息(如: 分区信息等)
然后按照整个 manifest list 生成一个对应的 snapshot 文件
生成完 snapshot 文件之后,Iceberg 会把当前 snapshot 的 ID 及存储路径等信息写人到 metadata.json 中。
当一切准备完毕之后,会以原子操作的方式提交元数据文件 metadata.json
二、设计
https://zhuanlan.zhihu.com/p/488467438
https://mp.weixin.qq.com/s/n97nixd ...

数据湖-Iceberg-源码学习-Kernel-Table Format-数据读取-数据过滤
一、概述在 Iceberg 中自上而下买现了三层的数据过滤策路分别是: 分区裁剪、文件过滤和 RowGroup 过滤。
https://zhuanlan.zhihu.com/p/530355680
二、设计2.1. 分区剪裁Iceberg 支持分区裁剪优化,对于分区表来说,优化器可以自动从 where 条件中根据分区键直接提取出需要访问的分区,从而避免扫描所有的分区,降低了 IO 请求。Iceberg 实现分区剪枝并不依赖文件所在的目录,而是利用了 Iceberg 的文件布局。在 Iceberg 的每个 Snapshot 中都存储所有 manifest 清单文件的包含分区列信息,每个清单文件每个数据文件中存储分区列值信息。这些元数据信息可以帮助确定每个分区中包含哪些文件。这样实现的好处是:
无需调用文件系统的 list 操作,可以直接定位到属于分区的数据文件。
partition 的存储方式是透明的,用户在查询时无需指定分区,Iceberg 可以自己实现分区的转换,即使用户修改分区信息后,用户无需重写之前的数据。
2.2. 文件过滤Iceberg 提供了文件级别的统计信息, ...

数据湖-Iceberg-源码学习-API-Catalog 设计
一、概述Iceberg Catalog API 用来保存和查找表的元数据,比如 Schema、 属性信息等。
二、设计2.1. Metadata LayerIceberg 数据表每一次的修改后的状态都会在 Metadata Layer 层中生成一个 Snapshot (s0,s1) 文件,Snapshot 文件中包含一个 Manifest List, List 中存储了当前的 Snapshot 状态是由哪些 Manifest 文件组成。每个 Manifest 的文件会指向到真实数据的存储文件 Date File(一股是 parquet 格式)。
2.2. Catalog APICatalog API 良好的抽象来对接数据存储和元数据管理
如上图所示,Catalog 主要提供几方面的抽象。
数据 IO: File IO 都是可以定制,包括读写和删除;
元数据管理
https://zhuanlan.zhihu.com/p/389904827?utm_id=0
2.2.1. Catalog 接口Iceberg 为了支持多种 Catalog,定义了自己的 Catalog 规范,接口 ...
Spark-源码学习-SparkCore-存储服务-内存组件-内存管理器 UnifiedMemoryManager
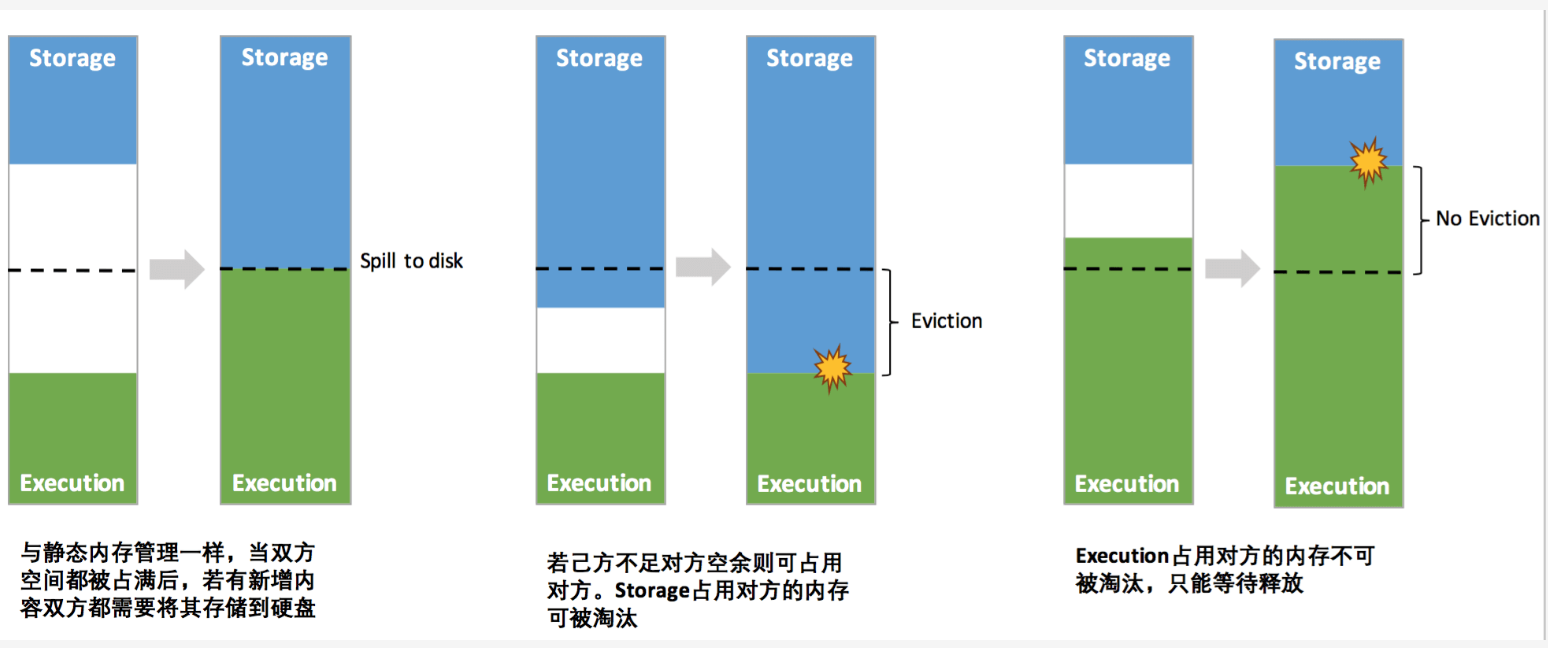
一、概述UnifiedMemoryManager 是从 1.6 开始的统一内存管理模型,统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域
二、实现2.1. 成员属性
maxHeapMemory: 最大堆内存。大小为系统可用内存与 spark.memory.fraction 属性值的乘积
onHeadpStorageRegionSize: 用于存储的堆内存大小。
numCores: CPU 内核数
2.2. 主要方法
三、内存申请3.1. 执行内存$UnifiedMemoryManager.accquireExecutionMemory()$ 方法申请执行内存~当任务尝试从 executor 中申请 numBytes 大小的内存该方法直接向 ExecutionMemoryPool 索要所需内存:
当 ExecutionMemory 内存充足,则不会触发向 Storage 申请内存: $maybeGrowExecutionPool()$
UnifiedMemoryManager 其中最重要的优化在于动态占用机制, ...
数据湖-Iceberg-源码学习-Query Engines-Spark
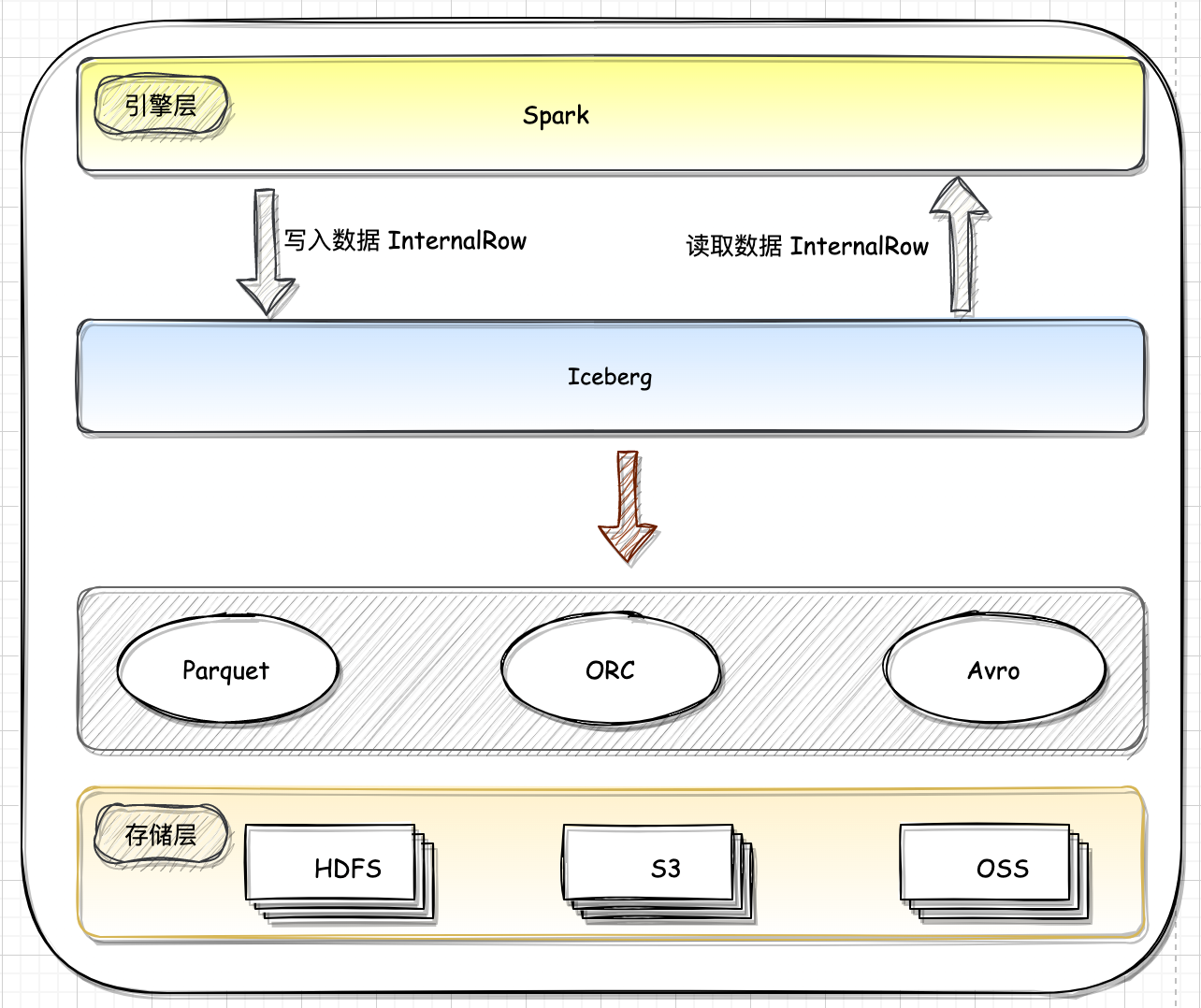
一、概述Iceberg 的架构和实现并未绑定于某一特定引擎,它实现了通用的数据组织格式,利用此格式可以方便地与不同引擎(如Flink、Hive、Spark)对接。Flink 和 Iceberg 的集成可以提供更好的数据管理和分析功能,可以更好地管理和分析大型数据集,Spark 基于 DataSourcev2 API 实现读写 Iceberg。
https://mp.weixin.qq.com/s/QGghPixwmTXGD_vdTvFmhw
二、读数据Spark 在读 Iceberg 表时通过读取 Metadata 文件可以实现高效的文件过滤:
首先根据 Partition Summary 进行文件过滤。如图,读取 Snapshot 对应的 ManifestFile List 可以读到三个ManifestFile
然后根据 where 条件加上 Partition Summary 的 min-max 信息可以过滤掉两个 ManifestFile。
根据每个 DataFile 的 Partition Value 和 metrics 信息做进一步的过滤,最后只有三个文件需 ...
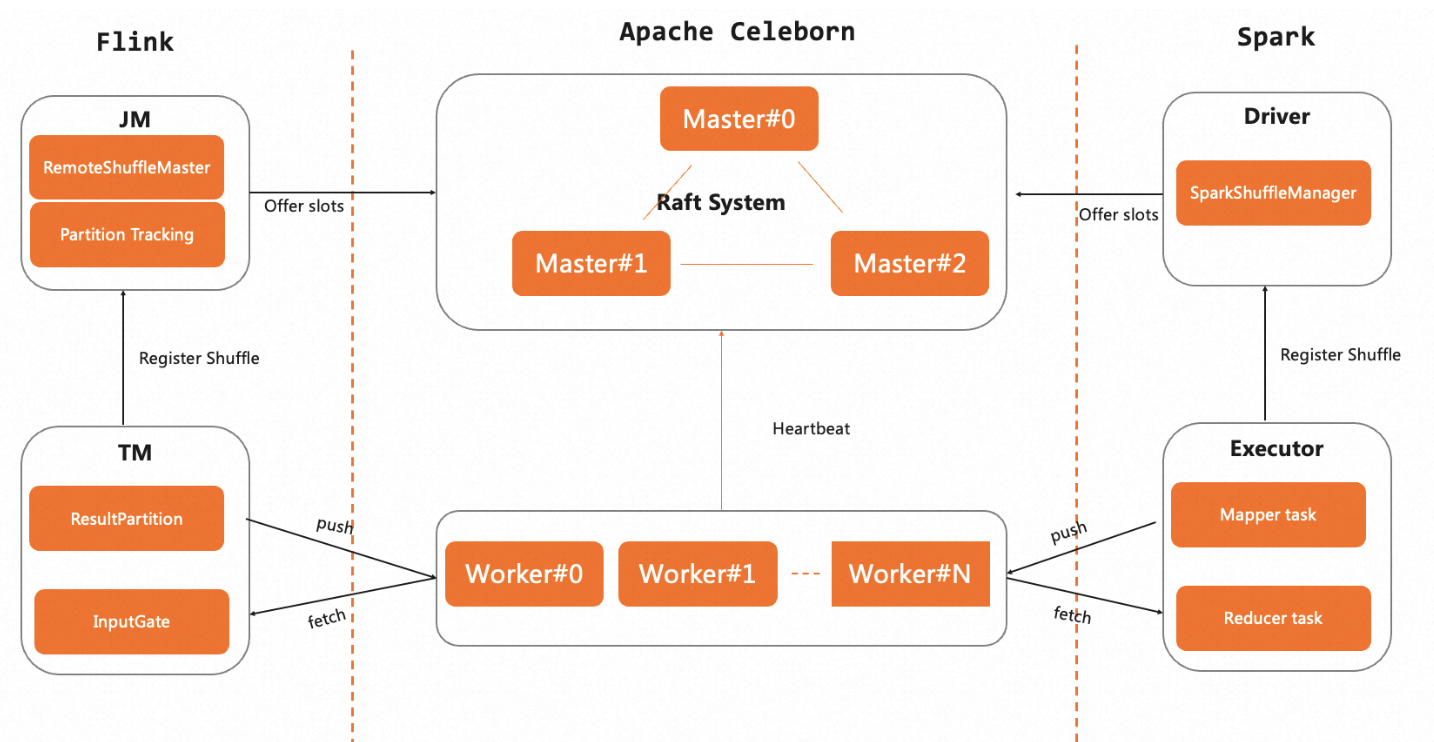
Spark-理论笔记-本地化执行引擎-SparkCore-Shuffle-RSS-Celeborn
一、概述Shuffle 是 Flink、Spark 大数据计算引擎影响计算性能的关键阶段,随着越来越多的用户选择计算存储分离的架构,将引擎部署在 K8s 集群上,而存算分离架构下计算节点 Local 磁盘不可能很大,另外 Flink、Spark 引擎还提供了根据资源量进行动态伸缩的 Adaptive Scheduler 的能力,这都要求计算节点能够将中间的 Shuffle 数据及时的卸载到外部存储服务上,以提高资源的利用效率,所以非常有必要使用独立的Shuffle 服务。
Celeborn 支持多种高效数据 Shuffle 方式,适配多种部署模式,其具备的 HA 架构、优雅下线等能力,也使得 Celeborn 自身具备弹性。
1.1. 背景1.1.1. 传统 Shuffle (External Shuffle Service) 的问题传统的 Shuffle 实现中,每个 Mapper 对 Shuffle Output 的数据,根据 Partition ID 做排序,然后把排序好的数据和索引写入本地盈。Shuffle Read 阶段,Reducer 从所有 Mapper 的 Shuf ...
Spark-源码学习-SparkCore-调度机制-任务调度-Task 调度-SchedulerBackend
一、概述SchedulerBackend 是 TaskScheduler 的调度后端接口。TaskScheduler 给 Task 分配资源实际是通过 SchedulerBackend 来完成的,SchedulerBackend 给 Task 分配完资源后将与分配给 Task 的 Executor 通信,并要求后者运行 Task。
https://weread.qq.com/web/reader/0c832fb05e12e40c8ca6190k32b321d024832bb90e89958
https://zhuanlan.zhihu.com/p/354775031https://www.yisu.com/zixun/563198.html
1.1. LauncherBackend当 Spark 应用程序没有在用户应用程序中运行,而是运行在单独的进程中时,用户可以在用户应用程序中使用 LauncherServer 与Spark 应用程序通信。LauncherServer 将提供 Socket 连接的服务端,与 Spark 应用程序中的 Socket 连接的客户端通信。
TaskSc ...
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.














