Spark-理论笔记-本地化执行引擎-SparkCore-Shuffle-RSS-Celeborn
一、概述
Shuffle 是 Flink、Spark 大数据计算引擎影响计算性能的关键阶段,随着越来越多的用户选择计算存储分离的架构,将引擎部署在 K8s 集群上,而存算分离架构下计算节点 Local 磁盘不可能很大,另外 Flink、Spark 引擎还提供了根据资源量进行动态伸缩的 Adaptive Scheduler 的能力,这都要求计算节点能够将中间的 Shuffle 数
据及时的卸载到外部存储服务上,以提高资源的利用效率,所以非常有必要使用独立的Shuffle 服务。
Celeborn 支持多种高效数据 Shuffle 方式,适配多种部署模式,其具备的 HA 架构、优雅下线等能力,也使得 Celeborn 自身具备弹性。
1.1. 背景
1.1.1. 传统 Shuffle (External Shuffle Service) 的问题
传统的 Shuffle 实现中,每个 Mapper 对 Shuffle Output 的数据,根据 Partition ID 做排序,然后把排序好的数据和索引写入本地盈。Shuffle Read 阶段,Reducer 从所有 Mapper 的 Shuffle 文件里读取属于自己的 Partition 数据。但这种实现有如下几个缺陷:
限制了存算分离
存算分离是目前大规模分布式系统的一个架构演进趋势,传统 Shuffle 依赖大容量的本地盘或云盘存储 shuffle 数据,数据需要驻留直至消费完成,限制了存算分离。
Mapper 做排序会占用较大内存,甚至触发堆外排序,引入额外的磁盘 IO。
Shuffle Read 有大量的网络连接,逻辑连接数是:
mxn存在大量的随机读盘。
当单台主机上运行较多的 executor 时,大量 Shuffle File 的并发读写速度将受制于单台主机磁盘和网络的速度,假设一个 Mapper 的 Shuffle 数据是 128M,Reducer 的并发是 2000,那么每个文件将会被读 2000 次,每次只随机读 64k,很容易达到磁盘 IOPS 的瓶颈。
数据单副本,容错性不高。
Shuffle File 存储在本地磁盘,没有备份。当所在主机故障时,所有 Spark 程序存储在该主机的 Shuffle File 都要重新计算,代价很高。
二、设计
Celeborn 整个组成分为三个部分: CelebornMaster、CelebornWorker 及 CelebornPlugin(Flink、Spark),其中 CelebornMaster 负责管理整个 Shuffle 集群包括 Worker、 Shuffle 资源管理及各种元数据等。Worker 则负责 Shuffle 数据写入读取,Flink 使用的 MapPartition 和 Spark 使用的 ReducePartition 模式复用了所有的服务端组件并在协议上达到了统一,Celeborn 服务端不感知引擎侧的差异。一套 Celeborn 集群可以同时为多种引擎提供服务。下面展现了 Flink、Spark 与 Celeborn 集群的交互架构图。
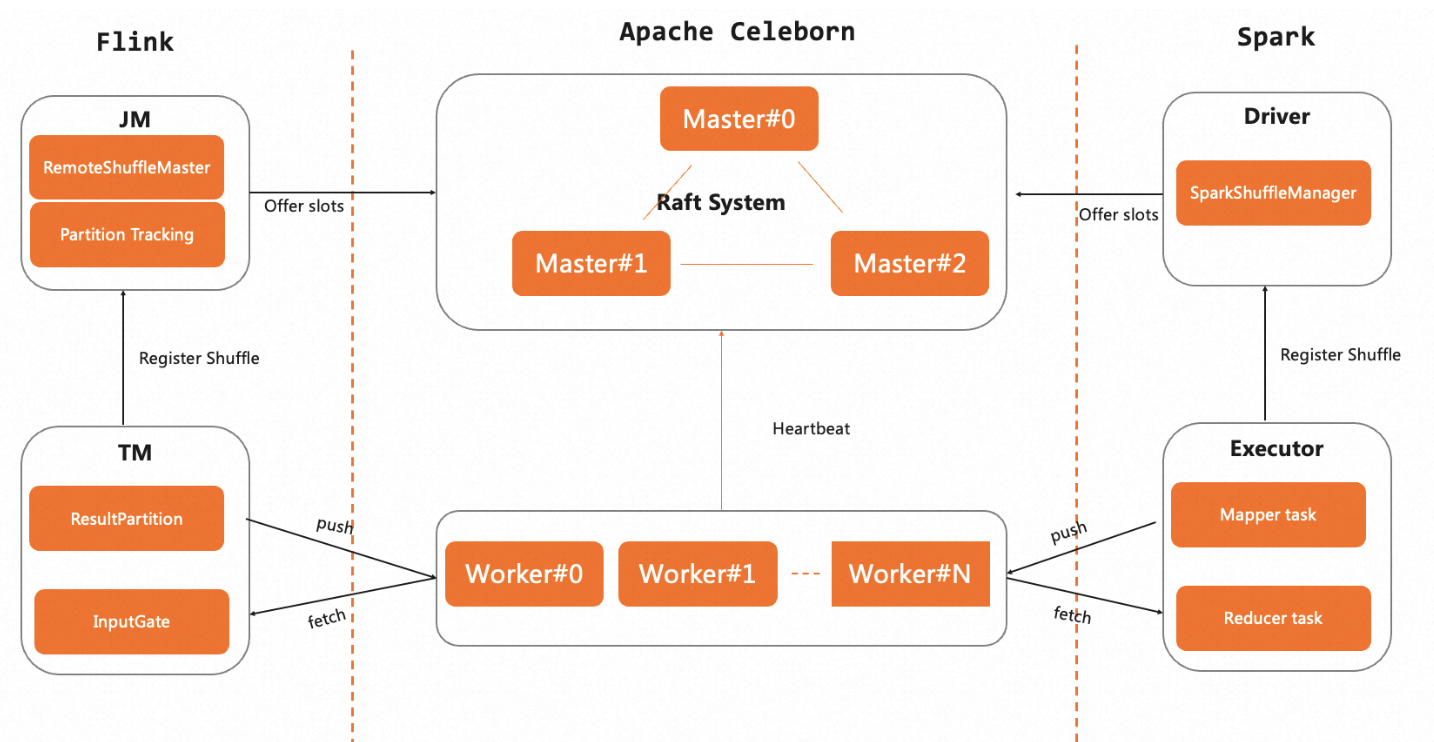
2.1. 面向多引擎
采用插件化的方式支持多引擎 Celeborn 致力于服务多引擎成为统一的 Shuffle 数据服务,在设计上 Celeborn 通过增强框架和协议的扩展性,
2.2. Credit-based 流控机制
数据则完全复用了 Celeborn 原有高效的多层存储实现。
2.3. 双 Shuffle 机制
 微信
微信 支付宝
支付宝