












Flink-源码学习-FlinkSQL&Table-Table 体系-Connector-TableSink
一、概述Flink SQL 可以将多种数据源或数据落地端映射为 table
二、实现2.1. 架构设计2.1.1. DynamicTableSinkFactoryDynamicTableSinkFactory 的主要方法和 DynamicTableSourceFactory 几乎完全一致
2.1.2. DynamicTableSink它具有的方法和DynamicTableSource基本一致,只有一个方法不同:getSinkRuntimeProvider方法。这个方法是sink的关键,返回一个SinkRuntimeProvider。这个类包含如何将表中数据落地的逻辑。
2.2. 实现2.2.1. PrintSink
Spark-源码学习-SparkSQL 系列-代码生成-整体流程
一、概述1select name from student where age > 18
二、CollapseCodegenStages 规则Catalyst 全阶段代码生成的入口是 CollapseCodegenStages 规则,当设置了支持全阶段代码生成的功能时(默认将 spark.sql.codegen.wholeStage 设置为 true,CollapseCodegenStages 规则会将生成的物理计划中支持代码生成的节点生成的代码整合成一段,因此称为全阶段代码生成 WholeStageCodegen。
本例中查询生成的物理计划包括 FileSourceScanExec、FilterExec 和 ProjectExec 3 个节点。这 3 个节点都支持代码生成,因此 CollapseCodegenStages 规则会在 3 个物理算子节点上添加 WholeStageCodegenExec 节点,将这 3 个节点生成的代码整合在一起。此外,加入 WholeStageCodegenExec 物理节点后,物理计划打印输出时不会打印该节点本身,其所囊括的所有子节点在打印输出 ...
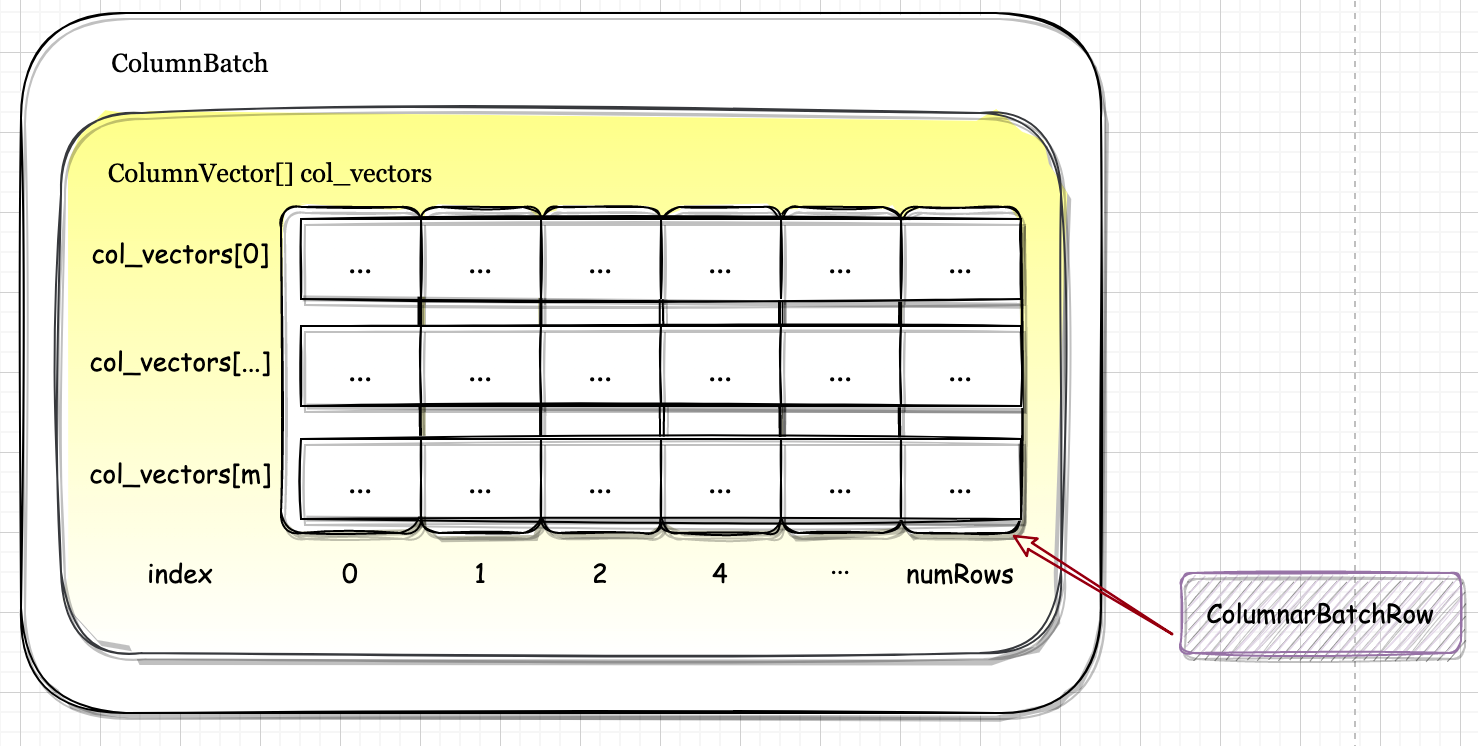
Spark-源码学习-向量计算
一、概述通常程序代码是被串行执行的。计算型程序通常需要在数据上做大量计算。一般情况下多数数据需要被相同的方式处理。例如: 对于 1000 个粒子的模拟,模拟中会有一个步骤,用其当前速度更新每个粒子的位置: $s=s+v$ ,s[O] 到 s[999] 每个粒子都要进行这个操作。如果可以将多个粒子的计算结合起来一次计算,例如将 4 个粒子的计算放在一个组中计算:
1234s[0] = s[0] + v[0];s[1] = s[1] + v[1];s[2] = s[2] + v[2];s[3] = s[3] + v[3];
多个数据一次性执行一个操作,被叫做 SIMD (single instruction multiple data)。
SIMD 是从指令设计者(即 CPU 制造商)的角度给出的概念名称。在数学上,由固定数量的元素组成的有序组被称作向量。所以 SIMD 也被叫做向量指令。
二、Java 向量化2.1. 热点代码追踪热点追踪靠 JVM 本身内部的实现机制去做到的。当代码需要足够多的次数去执行的时候,JVM 会发现自身对这个地方优化很有价值,其中有一个优化就是把它进 ...
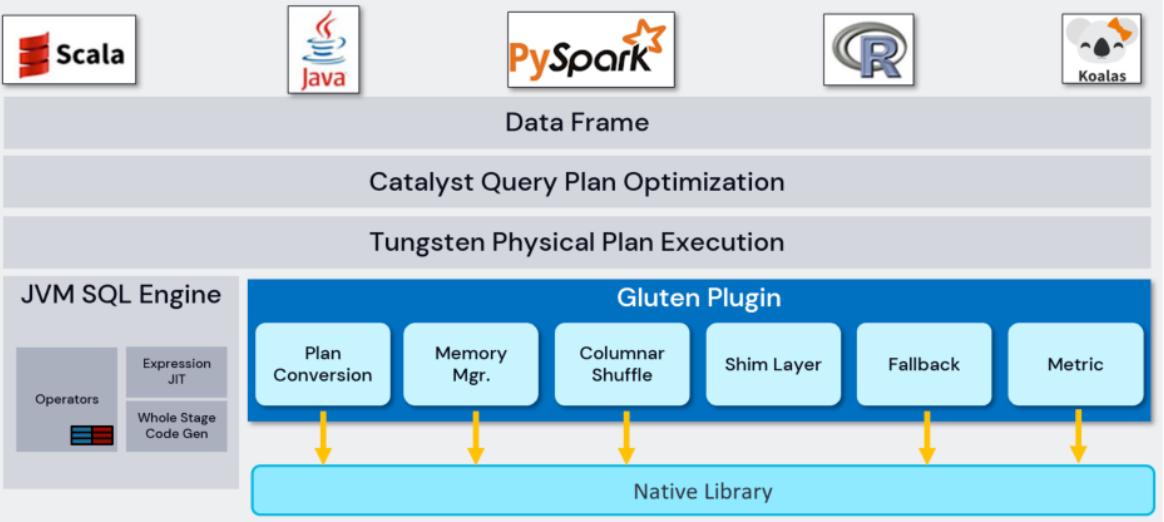
Spark-理论笔记-本地化执行引擎-Gluten
一、概述Spark 计算模型目前基于 JVM 实现,而 JVM 只能利用一些基础的 CPU 指令集。虽然有 JIT 的加持,但相比目前市面上很多的 Native 向量化计算引擎而言,性能还是有较大差距。因此考虑将具有高性能计算能为的 Native 向量引擎引用到 Spark 里来,从而提升 Spark 的计算性能,突破 CPU 瓶颈。Spark 作为基础计算框架,不管是在稳定性还是可扩展性方面,以及生态建设都得到了业界广泛认可。在不考虑改动 Spark 基础框架,使用 Native 计算引擎替换掉 Spark 原有基于 JVM 的 Task 计算模型,可以把高性能计算能力带给 Spark,突破 CPU 的瓶颈问题。
Native 计算引擎基于 C++ 开发,容易利用 CPU 原生指令集的优化。另外 Native 引擎基于列式数据格式,容易做向量化处理,进而达到高性能计算。基于这两点,Gluten 项目应运而生。Gluten 是一个基于 Spark 的向量化引擎中间件,把 Spark SQL 整个执行过程当中的计算转移到向量化引擎去执行,获得指令集的原生加速。
二、设计Gluten ...
Spark-源码学习-SparkSQL 系列-代码生成-CodeGenerator
一、概述二、实现代码生成的过程由代码生成器(CodeGenerator)完成,CodeGenerator 是一个基类,对外提供生成代码的接口是 $generate()$
经过 CodeGenerator 类生成后的代码,由其伴生对象提供的 $compile()$ 方法进行编译,得到 GeneratedClass 的子类。GeneratedClass 仅仅起到封装生成类的作用,在具体应用时会调用 $generate()$ 方法显示地强制转换得到生成的类。
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Planner 模块-Strategy-DataSourceStrategy
一、概述Spark 针对 DataSource V1 预定义了四种 scan 接口,Tablescan、 Prunedscan、 PrunedFilteredscan、 Catalystscan,如果开发者自己实现的DataSource是实现了这四种接口之一的,在 scan 到执行计划的底层 Relation 时,就会调用来扫描文件。
对于 DataSourceStrategy,是处理使用 source api 的定义的 Data Source,会把对应的 LogicalRelation 转换为 RowDataSourceScanExec:
SQL角度讲有基本的过滤、语法树。语法树过滤也有2个层次,一个是基本的过滤,一个是真正的解析。优化是对各种fiter进行合并,而且会调整顺序。最后从 Catalyst 角度,它会变成 RDD 进行操作,最后会装入到 DataSourceStrategy。DataSourceStrategy 会通过 Parquet 高层的 API 来操作 Parquet。Parquet 内部再收到上层的过滤条件的时候底层如何映射。
DataSourceStrat ...

Spark-源码学习-SparkSQL 系列-代码生成-CodegenSupport 接口
一、概述实现 CodegenSupport 接口的 Operator 可以将自己的逻辑拼成 Java 代码
二、设计在 CodegenSupport 中比较重要的是 $consume/doConsume$ 和 $produce/doProduce$ 这两对方法。$consume()$ 和 $doConsume()$ 用来消费,返回该 CodegenSupport 节点处理数据核心逻辑所对应生成的代码;而 $produce()$ 和 $doProduce()$ 则用来生产,返回的是该节点及其子节点所生成的代码。$produce()$ 方法会调用 $doProduce()$ 方法,而 $consume()$ 方法则会调用其父节点的 $doConsume()$ 方法。此外,CodegenSupport 中还保存了其父节点 parent 作为变量,以及其他一些辅助的方法,如判断是否支持代码生成($supportCodegen$)、获得产生输入数据的 $inputRDDs$ 等。
相邻 Operator 通过 Produce-Consume 模式生成代码
2.1. 属 ...
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Planner 模块-Strategy-DataSourceV2Strategy
一、概述所有的策略都继承自 GenericStrategy 类,其中定义了 planLater 和 apply 方法;SparkStrategy 继承自 GenericStrategy 类,对其中的 planLater 进行了实现,根据传入的 LogicalPlan 直接生成前述提到的 PlanLater 节点 。 此外,在 Spark SQL 中
Strategy 是 SparkStrategy 类的别名
1type Strategy = SparkStrategy
二、实现
Spark-源码学习-SparkSession-SparkContext-ContextCleaner 设计
一、概述SparkContext 初始化的最后一个组件: 上下文清理器 ContextCleaner。它扮演着 Spark Core 中垃圾收集器的角色。Spark 运行的时候,会产生一堆临时文件和数据,比如 Shuffle 的临时数据等,如果每次运行完,或者没有运行完杀掉了,不清理,会产生大量的无用数据,最终造成大数据集群崩溃而死。
二、设计ContextCleaner 是 Spark 应用中的垃圾收集器,负责应用级别的 shuffles,RDDs,broadcasts,accumulators 及 checkpointedRDD 文件的清理,用于减少内存及磁盘存储的压力。
ContextCleaner 在 Driver 中运行,在 SparkContext 启动且 spark.cleaner.referenceTracking 配置为 true 时启动,在 SparkContext 停止的时候停止。
2.1. 属性
referenceBuffer
缓存 CleanupTaskWeakReference 的集合。CleanupTaskWeakReference 是 Java ...

Spark-源码学习-SparkSQL-SQL 语句的执行过程
一、概述在典型的 Spark SQL 应用场景中,数据的读取、数据表的创建和分析都是必不可少的过程。通常来讲,SparkSQL 查询所面对的数据模型以关系表为主。
如图所示的案例显示了使用 SparkSQL 进行数据分析的一般步骤。
二、流程2.1. 创建 SparkSession从 2.0 版本开始,SparkSession 逐步取代 SparkContext 成为 Spark 应用程序的入口,SparkSession 内封装了 SparkConf、SparkContext 和 SQLContext 等。
1234val spark: SparkSession = SparkSession.builder() .master("local") .appName("MySQLSourcePractice") .getOrCreate()
引用本站文章
Spark-源码学习-SparkSession 设计
...
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.















