












Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Analyzer 模块-Rule-Substitution-CTESubstitution
一、概述CTESubstitution 规则是用来处理 With 语句。 在遍历逻辑算子树的过程中,当匹配到 With(child, relations) 节点时,将子 LogicalPlan 替换成解析后的 CTE,由于 CTE 的存在,SparkSqlParser 对 SQL 语句从左向右解析后会产生多个 LogicalPlan。
二、实现Catalyst 实现了完善的表达式体系,与各种算子(QueryPlan)占据同样的地位。算子执行前通常都会进行”绑定”操作,将表达式与输入的属性对应起来,同时算子也能够调用各种表达式处理相应的逻辑。
在 Expression 类中,主要定义了5个方面的操作,包括基本属性、核心操作、输入输出、字符串表示和等价性判断
核心操作 eval 函数实现了表达式对应的处理逻辑,也是其他模块调用该表达式的主要接口,而 genCode 和 doGenCode 用于生成表达式对应的 Java 代码。字符串表示用于查看该 Expression 的具体内容,如表达式名和输入参数等。
Spark-源码学习-SparkSQL 系列-代码生成
一、概述SparkSQL 的优越性能背后有两大技术支柱: Optimizer 和 Runtime。前者致力于寻找最优的执行计划,后者则致力于把既定的执行计划尽可能快地执行出来。Runtime 的多种优化可概括为两个层面:
全局优化
从提升全局资源利用率、消除数据倾斜、降低 IO 等角度做优化,包括自适应执行 (Adaptive Execution), Shuffle Removal 等。
局部优化
优化具体的 Task 的执行效率,主要依赖 Codegen 技术,具体包括 Expression 级别和 WholeStage 级别的 Codegen。
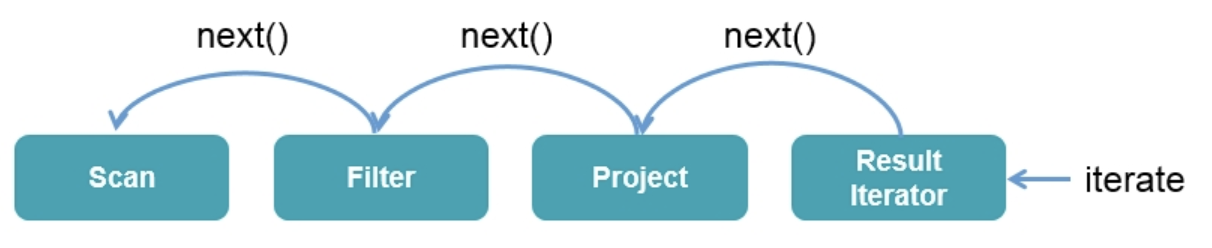
1.1. Volcano 模式1.1.1. 概述在 Apache Spark 2.0 之前,Spark SQL 的底层实现基于火山模型 $Volcano\ Iterator\ Model$ 。 Volcano 模型的执行可以概括为: 数据库引擎会将 SQL 翻译成一系列的关系代数算子或表达式 Operator/Expression,然后依赖这些关系代数算子 Operator 逐条处理输入数据并产生结果。每个算子 Operator ...

Spark-源码学习-统计信息 Statistics 设计
一、概述Spark 统计信息不仅对了解数据质量非常有用,对使用 Spark SQL 进行查询也能得到优化,进一步提升速度。统计信息是通过执行计划树的叶子节点计算的,然后从树的最底层往上传递,同时 Spark 也会利用这些统计信息来修改执行树的执行过程。
https://www.cnblogs.com/starqiu/p/12132539.html
https://blog.51cto.com/u_15127525/2686187
二、设计2.1. StatisticsSparkSQL 逻辑阶段中,统计信息一般被记录在 Statistics 类中,最初它只计算了逻辑计划的物理大小。现在它还可以估计的行数、列统计信息等。
1234567case class Statistics( sizeInBytes: BigInt, rowCount: Option[BigInt] = None, attributeStats: AttributeMap[ColumnStat] = AttributeMap(Nil), isRuntime: Boolean = fa ...
Flink-源码学习-FlinkSQL&Table-Table 体系-Connector 设计
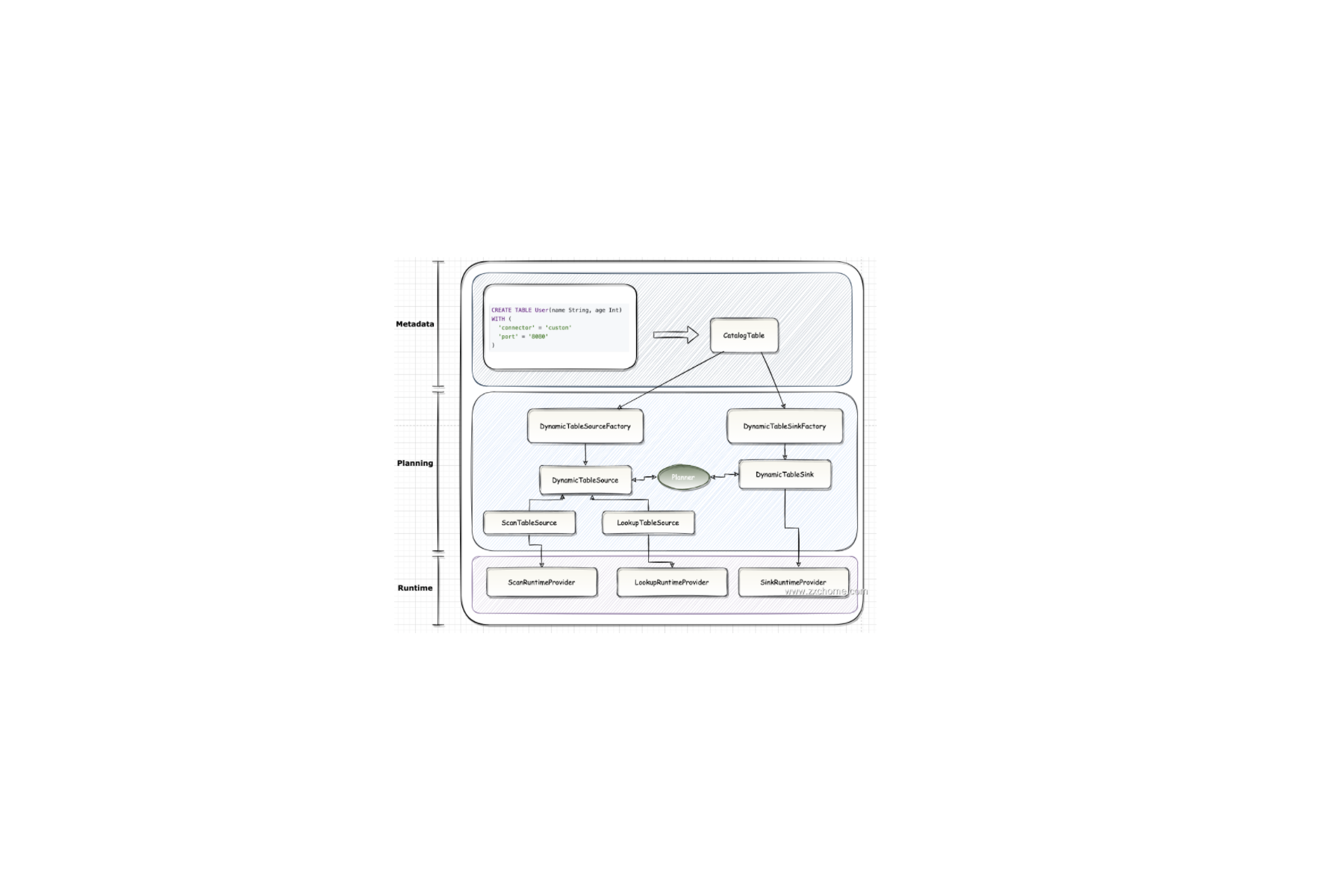
一、概述Flink 为 Table API 和 SQL 设计了 Table Connector 体系,包括 Table Source 和 Table Sink, 满足 Table API 和 SQL 对数据源访问的需求。
二、设计
2.1. MetaData通过 DDL 或由 Catalog 提供的元数据创建 CatalogTable 对象。
CatalogTable 是 Flink 中的一个表元数据管理模块,提供了一种统一的表元数据管理方式,方便管理 Fink 中的表信息,包括表的结构、存储位置、分区方式、统计信息等。
2.2. Planning在 Planning 阶段,DynamicTableSourceFactory 和 DynamicTableSinkFactory 提供特定连接器的逻辑,根据 CatalogTable 生成 DynamicTableSource 和 DynamicTableSink 的实例。
在大多数情况下,工厂的目的是验证选项(例如在示例中 ‘port’ = ‘8080’),配置编码/解码格式,以及创建表连接器(Table connectors) ...
Spark-发展-大厂分享系列
正在总结中,等我😭~~~
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Analyzer 模块-Rule-Substitution-WindowSubstitution
一、概述表达式一般指的是不需要触发执行引擎而能够直接进行计算的单元,例如加减乘除四则运算、逻辑操作、转换操作、过滤操作等。
二、实现Catalyst 实现了完善的表达式体系,与各种算子(QueryPlan)占据同样的地位。算子执行前通常都会进行”绑定”操作,将表达式与输入的属性对应起来,同时算子也能够调用各种表达式处理相应的逻辑。
在 Expression 类中,主要定义了5个方面的操作,包括基本属性、核心操作、输入输出、字符串表示和等价性判断
核心操作 eval 函数实现了表达式对应的处理逻辑,也是其他模块调用该表达式的主要接口,而 genCode 和 doGenCode 用于生成表达式对应的 Java 代码。字符串表示用于查看该 Expression 的具体内容,如表达式名和输入参数等。
Spark-源码学习-SparkSQL 系列-代码编译
一、概述WholeStageCodegenExec 生成 Java 代码之后,就会交给 Janino 编译器进行编译。
12345678val (_, compiledCodeStats) = try { CodeGenerator.compile(cleanedSource)} catch { case NonFatal(_) if !Utils.isTesting && conf.codegenFallback => // We should already saw the error message logWarning(s"Whole-stage codegen disabled for plan (id=$codegenStageId):\n $treeString") return child.execute()}
$doCodeGen()$ 方法返回 CodegenContext 对象与生成并格式化后的代码 (cleanedSource),Spark 首先尝试编译,如果编译失 ...
Spark-源码学习-SparkSQL 系列-代码生成-CodegenContext
一、概述CodegenContext 作为代码生成的上下文,记录了将要生成的代码中的各种元素,包括变量、函数等。
二、实现CodegenContext 作为代码生成的上下文,记录了将要生成的代码中的各种元素,包括变量、函数等。
2.1. 属性2.1.1. referencesreferences 是一个数组,用来保存生成代码中的对象(objects),可以通过 addReferenceObj 方法添加。
2.2. 方法2.2.1. 变量数组 mutableStates 相关方法
$addMutableState()$
方法用来添加变量,需要指定 Java 类型、变量名称和变量初始化代码。
$addBufferedState()$
用来添加缓冲变量,与常规的状态变量的不同之处是,缓冲变量一般用来存储来自 InternalRow 中的数据,比如一行数据中的某些列等。因此,这些变量仅在类中声明,但是不会在初始化函数中执行,该方法返回的是 ExprCode 对象。
$declareMutableStates()$
用来在生成的 Java 类中声明这些变量(默认均为 priva ...
Spark-源码学习-SparkSQL 系列-代码生成-WholeStageCodegenExec
一、概述WholeStageCodegenExec 是全阶段代码生成的实现类,用来将多个处理逻辑整合到单个代码模块中,然后将SQL中的逻辑表达式转换成 Java 函数,其也是 SparkPlan,所以主逻辑在 $execute()$ 方法中。具体可以分为:代码生成、代码编译和数据获取
二、执行 doExecute()2.1. 生成代码 doCodeGen()WholeStageCodegenExec 生成代码的入口在 $doCodeGen()$ 方法中
1val (ctx, cleanedSource) = doCodeGen()
2.1.1. 构造 CodegenContext$doCodeGen()$ 方法首先构造一个 CodegenContext 对象,然后将此对象作为 CodegenSupport 中 $produce()$ 方法的参数,直接调用 $produce()$ 方法生成具体的处理代码片段;最终基于该代码片段和代码生成之后的 CodegenContext 对象,构造完整的代码段。
WholeStageCodegenExec 生成的代码中通过一个 $genera ...
Spark-源码学习-SparkSQL 系列-代码生成-CollapseCodegenStages 规则
Catalyst 全阶段代码生成的入口是 CollapseCodegenStages 规则,当设置了支持全阶段代码生成的功能时(默认将 spark.sql.codegen.wholeStage 设置为 true,CollapseCodegenStages 规则会将生成的物理计划中支持代码生成的节点生成的代码整合成一段,因此称为全阶段代码生成 WholeStageCodegen。
本例中查询生成的物理计划包括 FileSourceScanExec、FilterExec 和 ProjectExec 3 个节点。这 3 个节点都支持代码生成,因此 CollapseCodegenStages 规则会在 3 个物理算子节点上添加 WholeStageCodegenExec 节点,将这 3 个节点生成的代码整合在一起。此外,加入 WholeStageCodegenExec 物理节点后,物理计划打印输出时不会打印该节点本身,其所囊括的所有子节点在打印输出字符串时,都会统一加入特定的 * 字符作为前缀,用来区别不支持代码生成的物理计划节点。
对于物理算子树,CollapseCodegenSta ...
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.















