











Spark-源码学习-容错-选举机制
一、概述领导选举机制(Leader Election)可以保证集群虽然存在多个 Master,但是只有一个 Master 处于激活(Active)状态,其他 Master 处于支持(Standby)状态。当 Active 状态的 Master 出现故障时,会选举出一个 Standby 状态的 Master 作为新的 Active 状态的 Master。
在 Master 的切换过程中影响:
不能够提交新的应用程序给集群, 因为只有 Active Master 才能接收新的程序提交请求
已经运行的程序中也不能因为 Action 操作触发新的 Job 提交请求。
集群 Worker, Driver 和 Application 的信息都已经通过持久化引擎持久化,因此在 Master 切换的过程中, 所有已经在运行的程序皆正常运行。因为 Spark Application 在运行前就已经通过 Cluster Manager 获得了计算资源, 所以在运行时,Job 本身的调度和处理和 Master 是没有任何关系的。
二、LeaderElectionAgent特质 LeaderEl ...

Spark-源码学习-集群启动-standalone-clustermanager
一、概述Cluster Manager 在 Standalone 部署模式下为 Master。Master 的设计将直接决定整个集群的可扩展性、可用性和容错性。
二、master 实现2.1. 属性
address: RpcEnv 的地址(即 RpcAddress)。RpcAddress 只包含 host 和 port 两个属性,用来记录 Master URL 的 host 和 port
webUiPort: 参数要指定的 WebUI 的端口
securityMgr: 即 SecurityManager
conf: 即 SparkConf
forwardMessageThread: 包含一个线程的 ScheduledThreadPoolExecutor,启动的线程以 master-forward-message-thread 作为名称。forwardMessageThread主要用于运行 checkForWorkerTimeOutTask 和 recoveryCompletionTask。
checkForWorkerTimeOutTask: 检查 Worker 超时的任 ...
Spark-源码学习-集群启动-standalone-选举机制
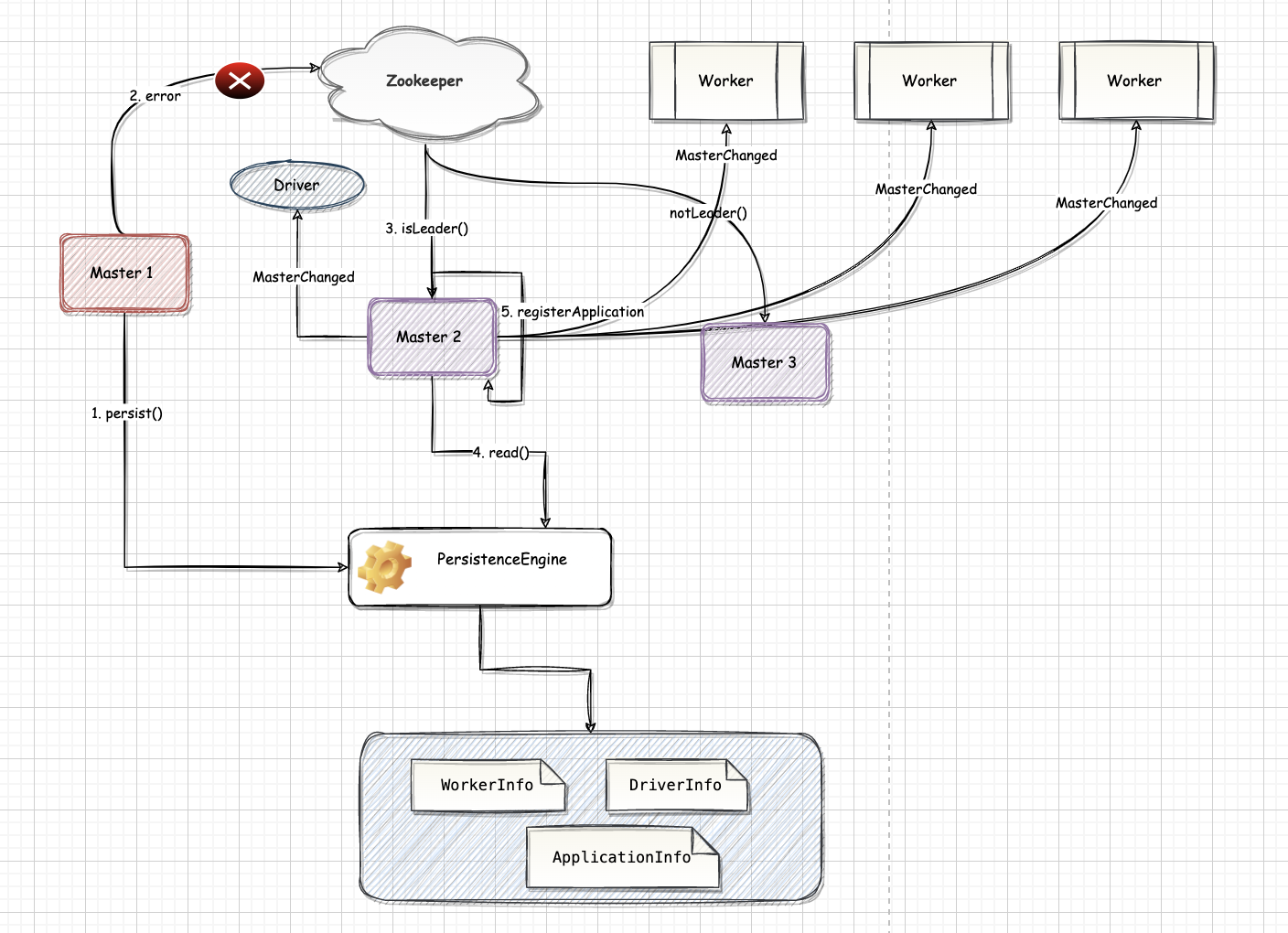
一、概述领导选举机制(Leader Election)可以保证集群虽然存在多个 Master,但是只有一个 Master 处于激活(Active)状态,其他的 Master 处于支持(Standby)状态。当 Active 状态的 Master 出现故障时,会选举出一个 Standby 状态的 Master 作为新的 Active 状态的 Master。由于整个集群的 Worker, Driver 和 Application 的信息都已经通过持久化引擎持久化,因此切换 Master 时只会影响新任务的提交,对于正在运行中的任务没有任何影响。
二、LeaderElectionAgent特质 LeaderElectionAgent 定义了对当前的 Master 进行跟踪和领导选举代理的通用接口。
1234trait LeaderElectionAgent { val masterInstance: LeaderElectable def stop(): Unit = {} // to avoid noops in implementations. ...
Spark-源码学习-集群启动-standalone 设计
启动 Master
Standalone 部署模式中首先会启动一到多个 Master.main 函数的进程。每个 Master.main 进程中都会创建 Master 实例并注册到 Master 自己的 RpcEnv 中
引用本站文章
Spark-源码学习-集群启动-standalone-Master 启动
Joker
Master 选举
Standalone 模式下可以存在多个Master,这些 Master 之间通过持久化引擎 (PersistenceEngine) 和领导选举机制解决生成环境下 Master 的单点问题,使 Master 在异常退出后,能够重新选举激活状态的 Master,并从故障中恢复集群。
在启动 Master 实例的过程中创建 ZooKeeperLeaderElectionAgent 实例,每个 Master 实例对 ...
Spark-源码学习-集群启动系列
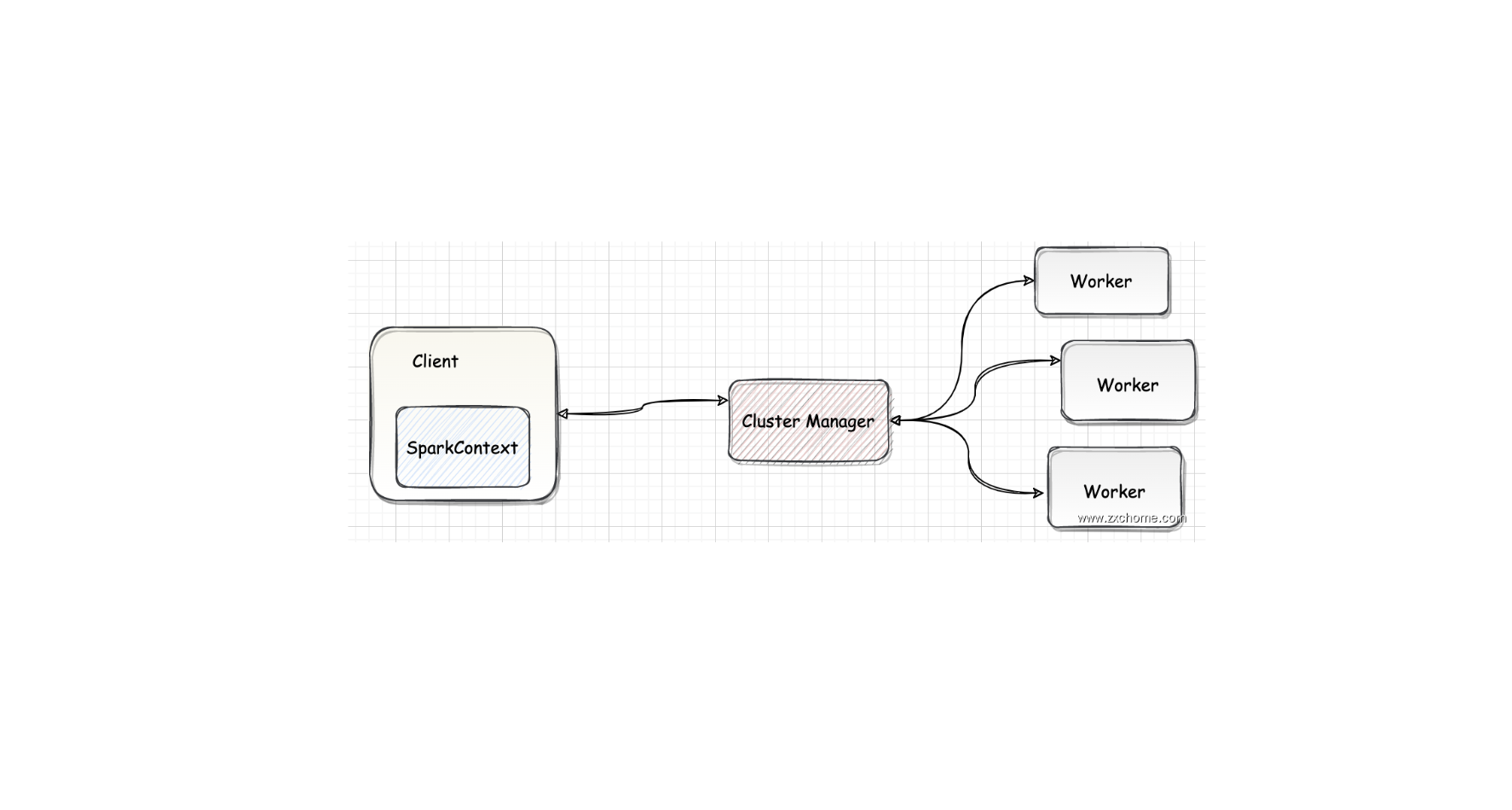
一、Spark 集群架构
1.1. ClusterManagerCluster Manager 负责集群的资源管理和调度。目前 Spark 支持4种 Cluster Manager
Standalone
Spark 自带的集群管理模式, Master
Apaehe Mesos
Mesos 是一种通用的集群资源管理服务,用于管理 MapReduce 应用或者其他类型的应用。
Hadoop YARN
YARN 是由 Hadoop 2.0 引入的集群资源管理服务。
Kubernetes
Kubernetes 是一种管理 containerized 的应用的服务。Spark 2.3以后引入了对Kubernetes的支持
1.2. WorkerWorker Node 是集群中可以执行计算任务的节点。在 YARN 部署模式下实际由 NodeManager 替代。Worker 节点主要负责以下工作
将自己的内存、CPU 等资源通过注册机制告知 Cluster Manager
创建 Executor,将资源和任务进一步分配给 Executor
二、部署模式Spark 应用程序在 ...
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Planner 模块-Rule-Preparations-CollapseCodegenStage
一、概述表达式一般指的是不需要触发执行引擎而能够直接进行计算的单元,例如加减乘除四则运算、逻辑操作、转换操作、过滤操作等。
二、实现Catalyst 实现了完善的表达式体系,与各种算子(QueryPlan)占据同样的地位。算子执行前通常都会进行”绑定”操作,将表达式与输入的属性对应起来,同时算子也能够调用各种表达式处理相应的逻辑。
在 Expression 类中,主要定义了5个方面的操作,包括基本属性、核心操作、输入输出、字符串表示和等价性判断
核心操作 eval 函数实现了表达式对应的处理逻辑,也是其他模块调用该表达式的主要接口,而 genCode 和 doGenCode 用于生成表达式对应的 Java 代码。字符串表示用于查看该 Expression 的具体内容,如表达式名和输入参数等。
Spark-源码学习-SparkSQL-Join 体系-BroadcastHashJoinExec
一、概述BroadcastJoinExec 主要思想是对小表进行广播操作,避免大量 Shuffle 的产生。这也是一种常见的思路,在 Spark SQL 中,对两个表做 Join 操作最直接的方式是先根据 key 分区,然后在每个分区中把 key 值相同的记录提取出来进行连接操作。这种方式不可避免地涉及数据的 Shuffle,而 Shufle 是比较耗时的操作。因此,当一个大表和一个小表进行 Join 操作时,为了避免数据的 Shufle,可以将小表的全部数据分发到每个节点上,供大表直接使用。
二、实现三、执行机制BroadcastJoinExec 主要思想是对小表进行广播操作,避免大量 Shuffle 的产生,在 Spark SQL 中,对两个表做 Join 操作最直接的方式是先根据 key 分区,然后在每个分区中把 key 值相同的记录提取出来进行连接操作。这种方式不可避免地涉及数据的 Shuffle,而 Shufle 是比较耗时的操作。因此,当一个大表和一个小表进行 Join 操作时,为了避免数据的 Shufle,可以将小表的全部数据分发到每个节点上,供大表直接使用。
Spark-源码学习-SparkSQL-Join 体系-ShuffledHashJoinExec
一、概述Spark SQL 优先级次之的是 ShuffledHashJoinExec,ShuffledHashJoinExec 执行需要满足多种条件。 ShuffledHashJoinExec 的构造同样分为 BuildLeft 和 BuildRight 两种情况,以 BuildRight 为例:
配置中优先开启 SortMergeJoin 的参数 spark.sql.join.preferSortMerge 设置为 false
右表需要满足能够”构建” ($canBuildRight$) 和能够建立 HashMap ($canBuildLocalHashMap$)
右表的数据量要比左表的数据量小很多(3 倍以上)
此外,还有一种生成 ShuffledHashJoinExec 的情况是参与连接的 key 不具有排序的特性。
二、执行
Spark-源码学习-SparkSQL-Join 体系-SortMergeJoinExec
一、概述SMJ 的思路是先排序、再归并,参与 Join 的两张表先分别按照 Join Key 做升序排序。然后,SMJ 会使用两个独立的游标对排好序的两张表完成归并关联。
SMJ 刚开始工作的时候,内外表的游标都会先锚定在两张表的第一条记录上,然后再对比游标所在记录的 Join Key。对比结果以及后续操作主要分为 3 种情况
外表 Join Key 等于内表 Join Key,满足关联条件,把两边的数据记录拼接并输出,然后把外表的游标滑动到下一条记录外表
外表 Join Key 小于内表 Join Key,不满足关联条件,把外表的游标滑动到下一条记录外表
外表 Join Key 大于内表 Join Key,不满足关联条件,把内表的游标滑动到下一条记录
SMJ 基于这 3 种情况,不停地向下滑动游标,直到某张表的游标滑到头,即关联结束。对于 SMJ 中外表的每一条记录,由于内表按 Join Key 升序排序,且扫描的起始位置为游标所在位置,因此 SMJ 算法的计算复杂度: $O(M + N)$
SMJ 计算复杂度的降低的前提是两张表预先排序,排序是一项非常 ...
Spark-源码学习-SparkSQL-Join 体系
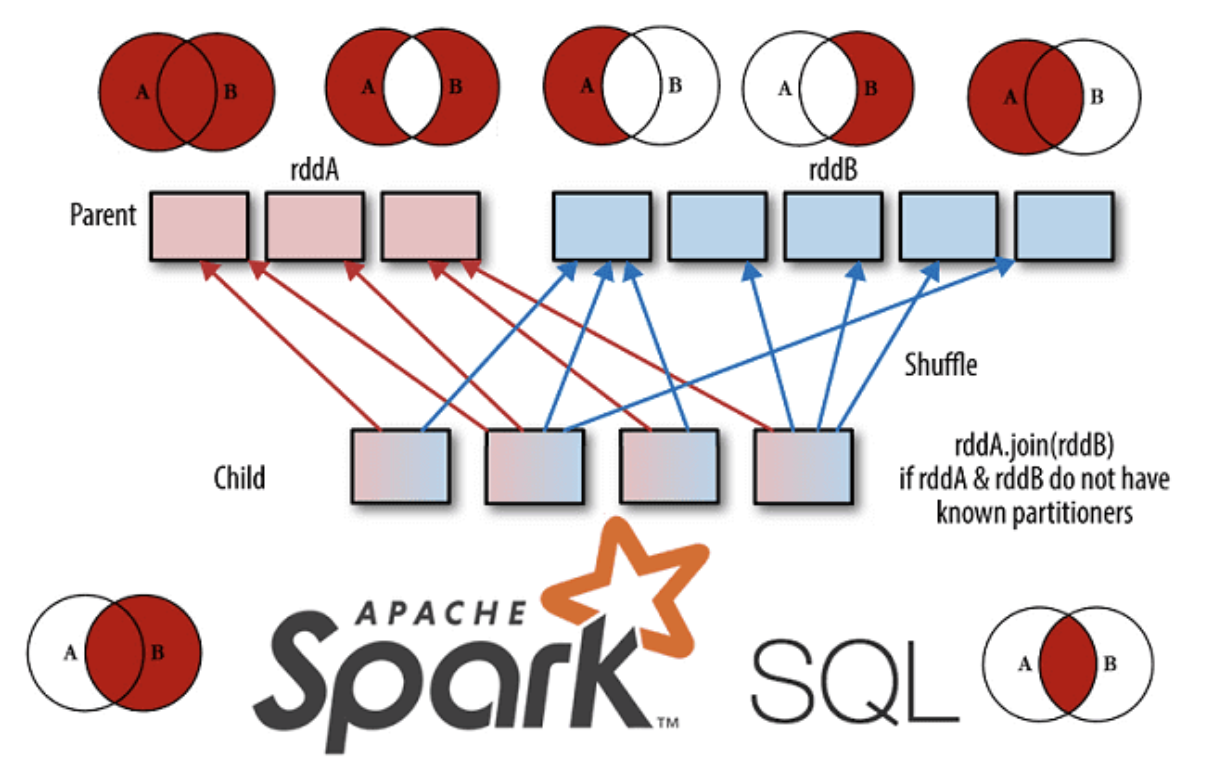
一、概述在面对多表数据分析的需求时,必须将多个分散的数据表关联起来进行 Join 操作。 目前 Spark SQL 中支持的 Join 类型主要包括 Inner、 FullOuter、 LeftOuter、 RightOuter、LeftSemi、 LeftAnti 和 Cross 共7种。
二、文法定义在 Spark SQL 的 ANTLR4 文法文件中,与 Join 相关的文法定义如下:
123456789101112131415fromClause : FROM relation (COMMA relation)* lateralView* pivotClause? unpivotClause? ;relation : LATERAL? relationPrimary joinRelation* ;joinRelation : (joinType) JOIN LATERAL? right=relationPrimary joinCriteria? | NATURAL joinType JOIN LATERAL? right=relat ...
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.















