











Flink-源码学习-集群启动-standalone-jobmanager
一、概述
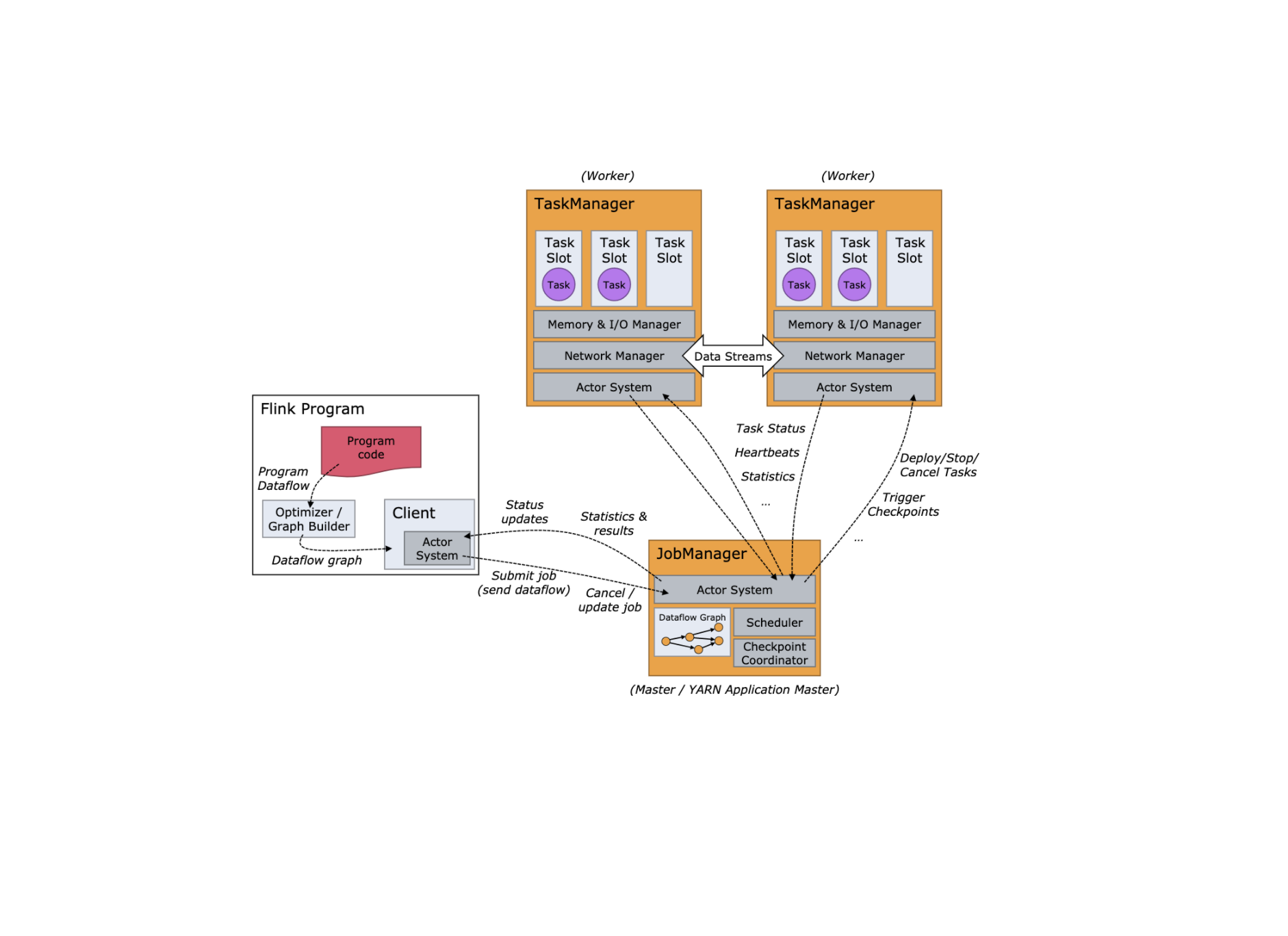
ResourceManager
Flink 的集群资源管理器,只有一个,关于slot的管理和申请等工作,都由他负责
Dispatcher
负责接收用户提交的 JobGragh, 然后为这个新提交的作业启动一个 JobMaster
WebMonitorEndpoint
WebMonitorEndpoint 基于 Netty 通信框架实现了 Restful 的服务后端,提供 Restful 接口支持 Flink Web 页面在内的所有 Rest 请求,例如获取集群监控指标。
JobMaster
负责一个具体的 Job 的执行,在一个集群中,可能会有多个 JobMaster 同时执行,类似于 YARN 集群中的 AppMaster 角色,类似于 Spark Job 中的 Driver 角色
二、启动根据以上的启动脚本分析来到 StandaloneSessionClusterEntrypoint#main() ~~~
2.1. 前置步骤
提供对 JVM 执行环境的访问的实用程序类
注册一些信号处理
安装安全关闭的钩子函数
Flink 集群启动 ...

Flink-源码学习-集群启动-公共基础服务
Fink 集群启动时组件会执行 initializeServices() 方法初始化一些基础服务,比如说 JobManager 启动时会初始化一些 RPC 通信服务、高可用服务以及监控服务等。
RPC 通信服务
Flink 集群内部通信框架的最底层依赖于 Akka,定义了不同类型的消息,并且设计了通用的 RPC 通信组件,Flink 的所有提供 RPC 请求的集群组件(如 JobMaster、 TaskManager、 ResourceManager、 Dispatcher 等)都使用了这些 RPC 通信基础组件來提供对外的 RPC 接口。
引用本站文章
Flink-源码学习-FlinkCore-通信服务-Flink RPC 设计
Joker
JobManager RPC 服务如图所示:
高可用服务
向集群组件提供高可用支持,集群中的组 ...
Flink-源码学习-集群启动系列
一、概述Flink 集群在不同部署模式下的启动流程也有所差距~
二、部署2.1. Standalone
引用本站文章
Flink-源码学习-集群启动-standalone
Joker
2.2. Yarnsession |per_job |application
引用本站文章
Flink-源码学习-集群启动-yarn-session
Joker
引用本站文章
Flink-源码学习-集群启动-yarn ...
Hadoop-组件-Yarn-理论笔记系列
一、概述Hadoop-组件-Yarn-理论笔记系列-概述只有 1 篇哦😯~~~
Yarn 概述
Yarn 作为 Hadoop 的资源管理系统,负责 Hadoop 集群上计算资源的管理和作业调度。
二、调度器

Iceberg 系列
loadStyle("/hexo-github/style.css");
loadStyle("/hexo-github/octicons/octicons.css");
new Badge("#badge-container-xiaochen-zhou-iceberg-35ad7", "xiaochen-zhou", "iceberg", "35ad7", false);
一、学习笔记
引用本站文章
数据湖-Iceberg-学习笔记
Joker
二、源码学习
引用本站文章
数据湖-Iceberg-源码系列
Joker
...
数据湖-Iceberg-源码系列
一、架构设计Iceberg 官网中是这样定义的:
1Apache Iceberg is an open table format for huge analytic datasets
Iceberg 是大型分析型数据集上的一个开放式表格式。通过该表格式,将下层的存储介质(HDFS、S3、OSS等)、文件格式(Parquet、Avro、ORC等)与上层计算引擎(Flink、Spark、Presto、Hive等)进行解耦。
二、阅读环境准备
引用本站文章
数据湖-Iceberg 源码学习-阅读环境准备
Joker
三、Kernel3.1. Table Format
引用本站文章
数据湖-Iceberg-源码学习-Kernel-T ...

数据湖-Iceberg-源码学习-Table Format 设计
一、概述Iceberg 是一种开放的数据湖 Table Format,其基于计算层 (Flink,Spark) 和存储层 (ORC,Parqurt,Avro) 的一个中间层,通过特定的方式将数据和元数据组织起来。
二、类型Iceberg 表格式目前有两个版本: V1 表和 V2 表。V1 表的更新采用 Copy On Write (COW) 模式,将需要更新的文件读取出来做更新后再写入。在V2 表中除了 Copy On Write,还增加了 Merge On Read (MOR),支持行级别删除(Row-level delete)、更新(Update) 等操作。MOR 通过记录另外两个文件,即 Position delete 和 Equality delete 文件对已有的文件进行删除,当读取的时候进行 merge 得到终的结果。
目前两种表在创建时需要在表的 options 中显示指定,如果不指定则默认为 V1 版本
2.1. V12.2. V2三、文件布局3.1. 设计Iceberg 文件布局可以分为数据层(Data Layer) 和元数据层(Metedata Lay ...

数据湖-Iceberg-源码学习-Kernel-Table Format-FileLayouts 设计
一、概述Iceberg 文件布局可以分为数据层(Data Layer) 和元数据层(Metedata Layer)。数据层是一系列实际存储数据记录的文件,而元数据层包括元数据描述文件、清单列表文件(Manifest List)、以及清单文件(Manifest File)。三类文件通过层级关系相互关联起来。
引用站外地址,不保证站点的可用性和安全性
Apache Iceberg 背后的设计
Joker
引用站外地址,不保证站点的可用性和安全性
浅谈 iceberg 的存储文件
Joker
二、架构设计2.1. CatalogIceberg Catalog API 用来保存和查找表的元数据,比如 Schema、 属性信息等。
2.2. Metadata ...

数据湖-Iceberg-源码学习-Kernel-Table Format-FileLayouts-Data Layer 设计
一、概述二、设计数据文件根据存储原始数据的内容类型也分为多种类型,新增数据类型、基于 Position 删除的数据类型和基于 Equality 删除的数据类型:
2.1. DataFile2.2. DeleteFile

数据湖-Iceberg-源码学习-Kernel-Table Format-FileLayout-Metadata Layer 设计
一、概述Iceberg 数据表每一次的修改后的状态都会在 Metadata Layer 层中生成一个 Snapshot (s0,s1) 文件,Snapshot 文件中包含一个 Manifest List, List 中存储了当前的 Snapshot 状态是由哪些 Manifest 文件组成。每个 Manifest 的文件会指向到真实数据的存储文件 Date File(一股是 parquet 格式)。
二、架构设计Iceberg 文件布局元数据层中,每一个快照 Snapshot 读取所需要的数据文件都已经清晰的定义在了 manifest list 和 manifest的文件中,并且manifest 文件中还存储了相关的统计信息。
https://yunche.pro/blog/?id=320
三、元数据文件 metadata.json查询 Iceberg 表数据时,首先获取最新的 metadata 信息(metadata.json 文件) 这里先获取到 00000-*ec504.metadata.json 元数据信息,解析当前 metadata.json 可以拿到当前表的快照 ...
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.















