












Flink-源码学习-架构设计-部署模式-PerJob-Flink On Yarn
正在总结中,等我😭~~~
Spark-源码学习-SparkSQL-一条聚合 SQL 语句的执行过程~
一、概述在典型的 Spark SQL 应用场景中,数据的读取、数据表的创建和分析都是必不可少的过程。通常来讲,SparkSQL 查询所面对的数据模型以关系表为主。
如图所示的案例显示了使用 SparkSQL 进行数据分析的一般步骤。
二、聚合体系先了解下 Spark SQL 的聚合体系设计~
引用本站文章
Spark-源码学习-SparkSQL-聚合体系-架构设计
Joker
三、流程可以先看看这个~
引用本站文章
Spark-源码学习-SparkSQL-一条 SQL 语句的执行过程概述~
Joker
...
Flink-源码学习-存储服务-架构设计-磁盘管理
正在总结中,等我😭~~~
Flink-源码学习-存储服务-架构设计
一、概述Flink 提供的存储服务包括内存管理服务和文件管理服务,TaskManager 启动时也会初始化 I/O 管理组件 IOManager,负责将数据输出到磁盘并将其读取回来以及内存管理组件 MemoryManager 负责协调内存使用。
二、内存管理Flink 为了让用户更好的调整内存分配,达到资源的合理分配,在 Flink1.10 引入了 TaskManager 的内存管理,后续在 Flink1.11 版本引入了 JobManager 的内存管理,用户可以通过配置的方式合理的分配资源。不管是 TaskManager 还是 JobManager 都是单独的 JVM 进程,共用一套内存模型抽象(TaskManager 的内存模型更加复杂), Flink 从一开始就选择了使用自主的内存管理,避开了 JVM 内存管理在大数据场景下的问题,提升了计算效率。
2.1. 架构设计Flink 的 JVM 的进程总内存(Total Process Memory) 包含了 Flink 总内存(Total Flink Memory) 和运行 Flink 的 JVM 特定内存(JVM Spec ...
Flink-源码学习-架构设计-部署模式-Application
一、概述无论是 Session 模式 还是 Per_Job 模式,其 main 方法都是在容户端执行来获取 Flink 运行时所需的依赖项,并生成JobGraph,提交到集群的操作都会在实时平台所在的机器上执行,会给服务器造成很大的压力。尤其在大量用户共享客户端时,问题更加突出。其次,两种模式提交任务的时候会把本地 Flink 的所有 jar 包先上传到 hdfs 上相应的临时目录,这个会带来大量的网络的开销,如果任务特别多的情況下,平台的吞吐量将会直线下降。Flink-1.11 中引入了一种新的部署模式,即 Application 模式。Application 模式下,用户程序的 main 方法将在集群中而不是客户端运行。用户将程序選辑和依赖打包进一个可执行的 jar 包里,集群的入口程序 (ApplicationClusterEntryPoint) 负责调用其中的 main 方法生成 JobGraph
Applicaton 模式为每个提交的应用程序创建一个集群,该集群可以看作是在特定应用程序的作业之间共享的会话集群,并在应用程序完成时终止。
二、架构设计目前,Flink- ...
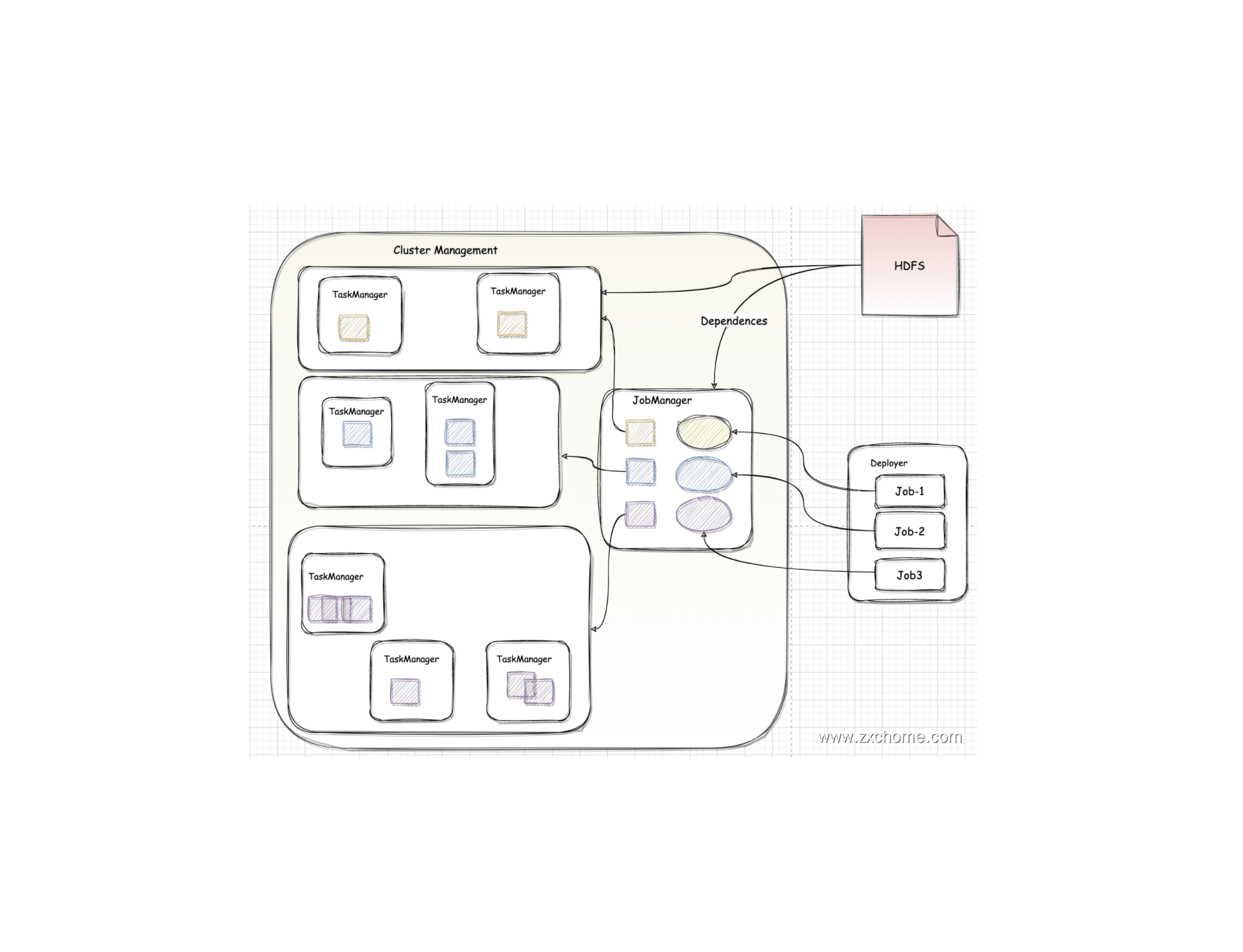
Flink-源码学习-架构设计-部署模式-Per_job
一、概述Per-Job 模式每次提交都会创建一个新的 Flink 集群,任务之间相互独立,当其中一个任务发生错误时只会使自己集群的 TaskManager 挂掉,不影响其他任务执行,且每个运行任务的 Flink 集群可以独立进行配置。任务执行结束后创建的 Flink 集群也会消失,其他中间产生或缓存的文件将会被清理。考虑到集群的资源隔离情况,一般生产上的任务都会选择 Per-Job 模式。
在 Flink 1.10 版本中,只有 Yarn 上实现了 Per-Job 模式。Per-Job 模式下,因为不需要共享集群,所以在 PipelineExecutor 中执行作业提交的时候,可以创建集群并将 JobGraph 以及所需要的文件等一同交给 Yarn 集群,Yarn 集群在容器中启动 JobManager 进程,进行一系列的初始化动作,初始化完华之后,从文件系统中获取 JobGraph,交给 Dispatcher。之后的执行流程与 Session 模式下的执行流程相同。对应源码,在 Flink 集群运行时启动过程中,会通过 ClusterEntrypoint 集群入口类启动管理 ...
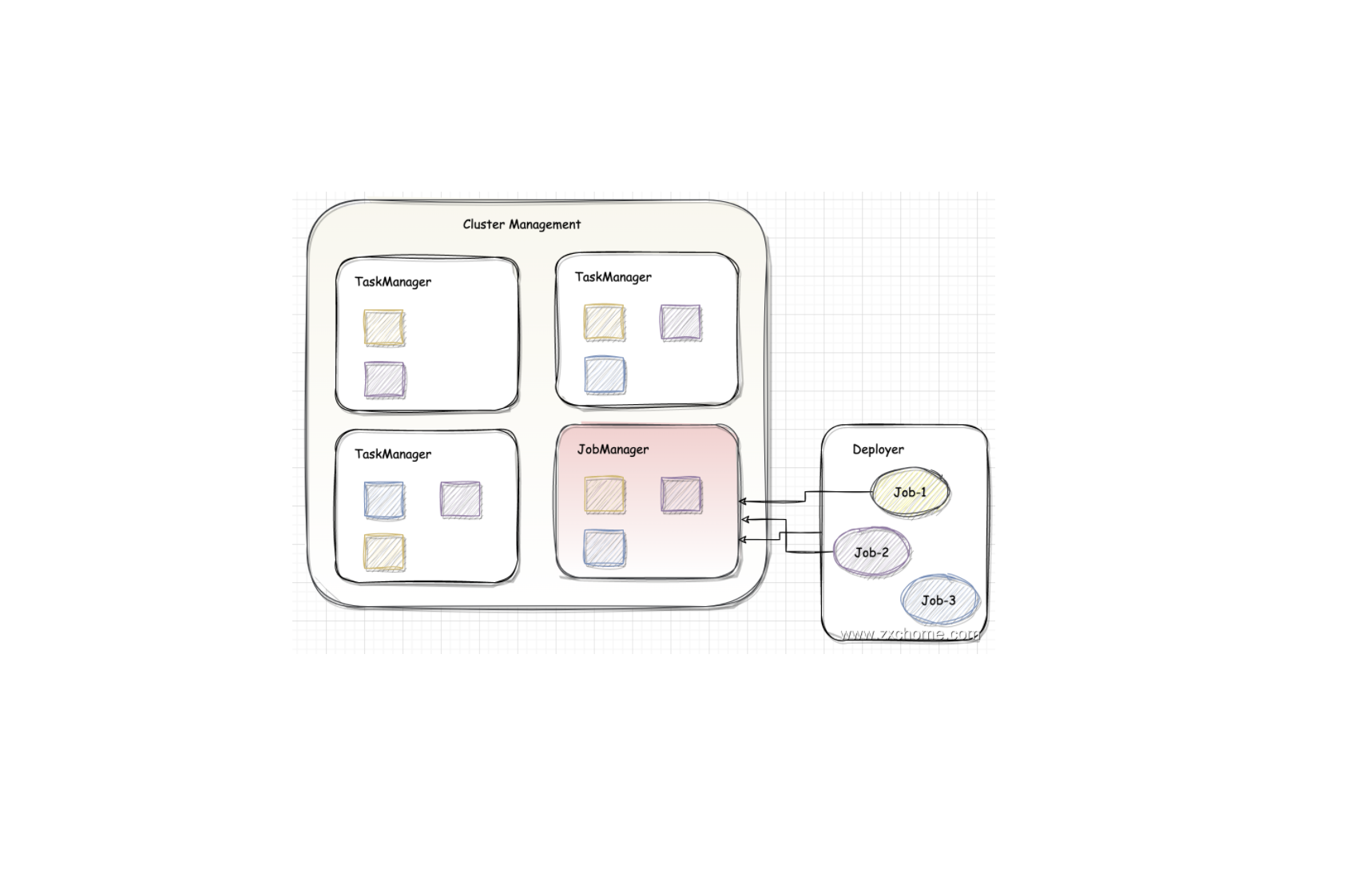
Flink-源码学习-架构设计-部署模式-Session
一、概述Session 模式会初始化一个 Flink 集群,此后提交的任务共享这个 Flink 集群资源,这个 Flink 集群会常驻,除非手动停止。在 Session 模式下,WebMonitorEndpoint、 Dispatcher、 ResourceManager 在 JobManager 启动时会一起启动,JobMaster 在有任务提交时才会启动。
二、架构设计在 Flink 1.10 版本中提供了三种会话模式:Standalone、Yarn 会话模式、K8s 会话模式。对应源码,在 Flink 集群运行时启动过程中,会通过 ClusterEntrypoint 集群入口类启动管理节点中的核心组件与服务。集群运行时会根据资源管理器的不同,选择不同的 ClusterEntrypoint 实现类启动集群组件。在 Session 集群部署模式下 SessionClusterEntrypoint 的实现类主要有 StandaloneSessionClusterEntrypoint、 KubernetesSessionClusterEntrypoint、YarnSessionC ...
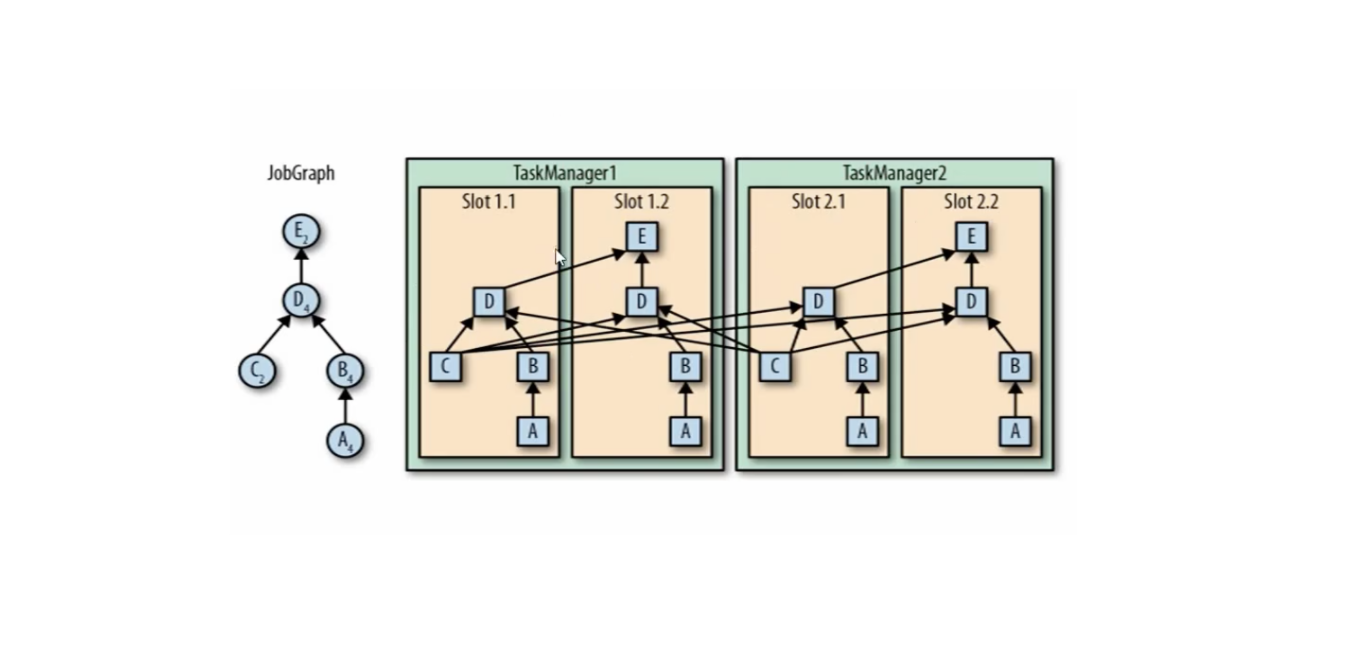
Flink-源码学习-Job 提交-Graph 演变-ExecutionGraph 构建
JobManager 根据 JobGragh 生成 ExecutionGragh, ExecutionGragh 是 JobGragh 的并行化版本,是调度层最核心的数据结构。来到 ExecutionGraph 构建源码分析~,有点难~~~
一、概述JobManager 根据 JobGragh 生成ExecutionGragh, ExecutionGragh是JobGragh的并行化版本,是调度层最核心的数据结构,每个 ExecutionGraph 都有一个与其相关联的作业状态。此作业状态指示作业执行的当前状态
ExecutionJobVertex
和 JobGraph 中的 JobVertex一一对应。每一个 ExecutionJobVertex 都有和并发度一样多的 ExecutionVertex。
ExecutionVertex
表示 ExecutionJobVertex 的其中一个并发子任务,输入是ExecutionEdge,输出是 IntermediateResultPartition。
IntermediateResult
和JobGraph中的Inte ...
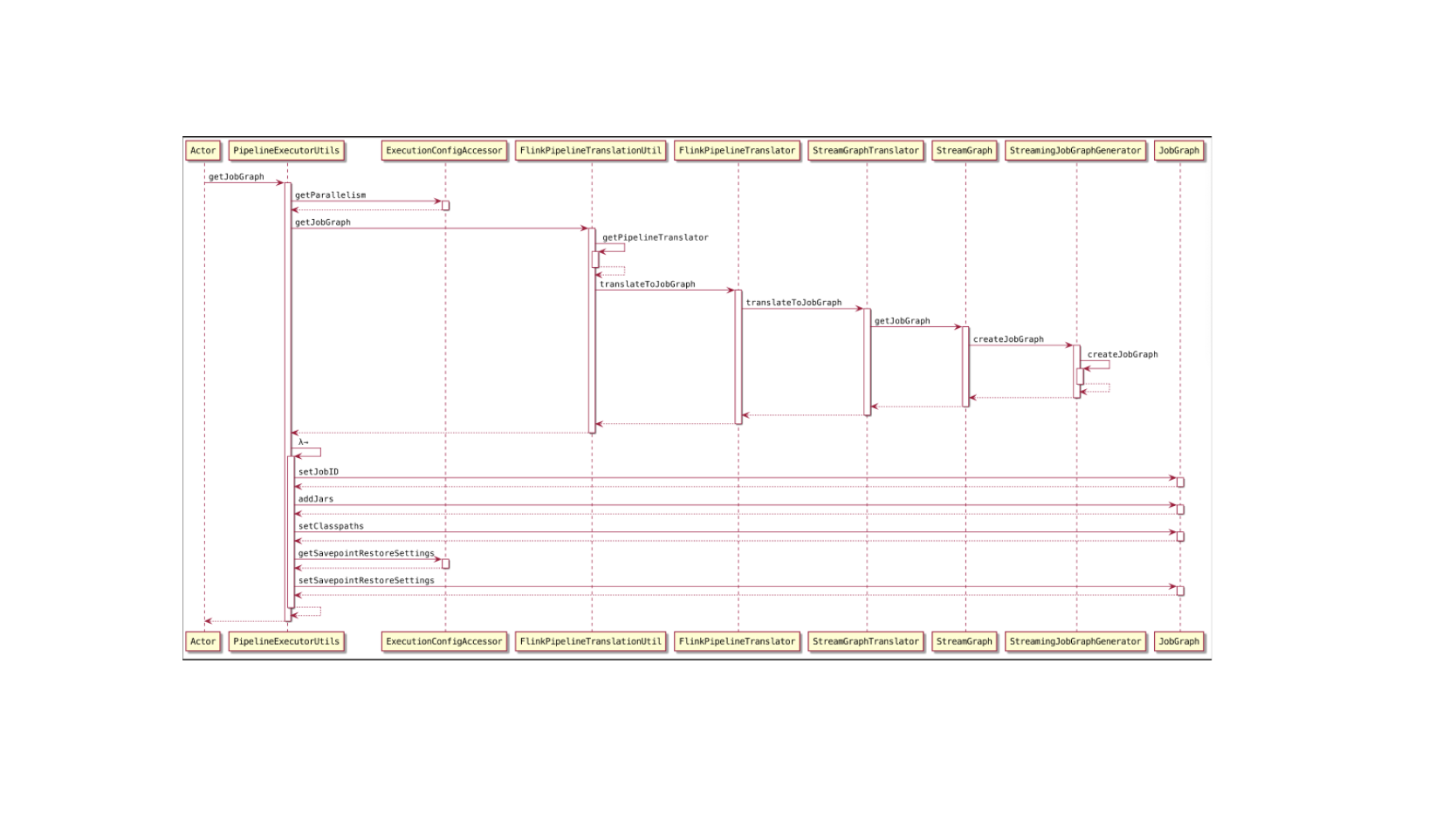
Flink-源码学习-Job 提交-Graph 演变-JobGraph 构建
JobGraph 数据结构在本质上是将节点和中间结果集相连得到有向无环图。JobGraph 是客户端和运行时之间进行作业提交使用的统一数据结构,不管是流式 (StreamGraph) 还是批量 (OptimizerPlan),最终都会转换成集群接受的 JobGraph 数据结构。
一、概述StreamGraph 经过优化后生成了 JobGraph,提交给 JobManager 的数据结构它包含的主要抽象概念有:
Jobvertex
经过优化后符合条件的多个 StreamNode 可能会 chain 在一起生成一个 Jobvertex, 即一个 JobVertex 包含一个或多个 operator, JobVertex 的输入是 JobEdge,输出是 IntermediateDataSet。
IntermediateDataSet
表示 JobVertex 的输出,即经过 operator 处理产生的数据集。producer 是 Jobvertex, consumer 是 JobEdge
JobEdge
代表了job graph中的一条数据传输通道。sour ...
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.















