Flink-源码学习-架构设计-部署模式-Per_job
一、概述
Per-Job 模式每次提交都会创建一个新的 Flink 集群,任务之间相互独立,当其中一个任务发生错误时只会使自己集群的 TaskManager 挂掉,不影响其他任务执行,且每个运行任务的 Flink 集群可以独立进行配置。任务执行结束后创建的 Flink 集群也会消失,其他中间产生或缓存的文件将会被清理。考虑到集群的资源隔离情况,一般生产上的任务都会选择 Per-Job 模式。

在 Flink 1.10 版本中,只有 Yarn 上实现了 Per-Job 模式。
Per-Job 模式下,因为不需要共享集群,所以在 PipelineExecutor 中执行作业提交的时候,可以创建集群并将 JobGraph 以及所需要的文件等一同交给 Yarn 集群,Yarn 集群在容器中启动 JobManager 进程,进行一系列的初始化动作,初始化完华之后,从文件系统中获取 JobGraph,交给 Dispatcher。之后的执行流程与 Session 模式下的执行流程相同。
对应源码,在 Flink 集群运行时启动过程中,会通过 ClusterEntrypoint 集群入口类启动管理节点中的核心组件与服务。集群运行时会根据资源管理器的不同,选择不同的 ClusterEntrypoint 实现类启动集群组件。Per-Job 部署模式下 ClusterEntrypoint 实现类为 JobClusterEntrypoint。
二、架构设计
2.1. Yarn Per-Job
Yarn Per-Job 下,JobGraph 和集群的资源需求一起提交给 Yarn
2.1.1.启动集群
- 使用
./flink run -m yarn-cluster提交 Per-Job 模式的作业。 - Yarn 启动 Flink 集群。该模式下 Flink 集群的启动入口是 YarnJobClusterEntryPoint,其他与 Yarn Session模式下集群的启动类似。
2.1.2. 作业提交
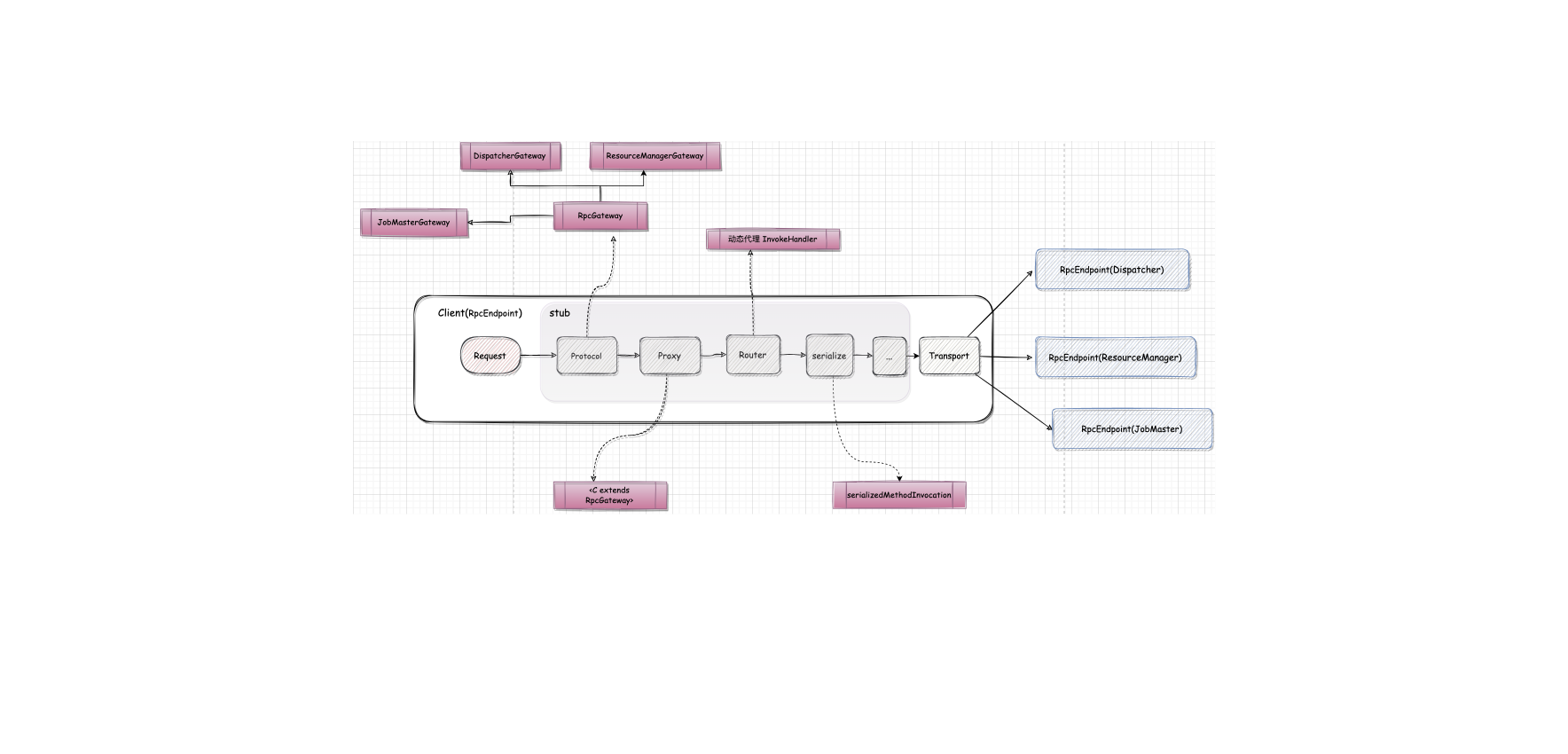
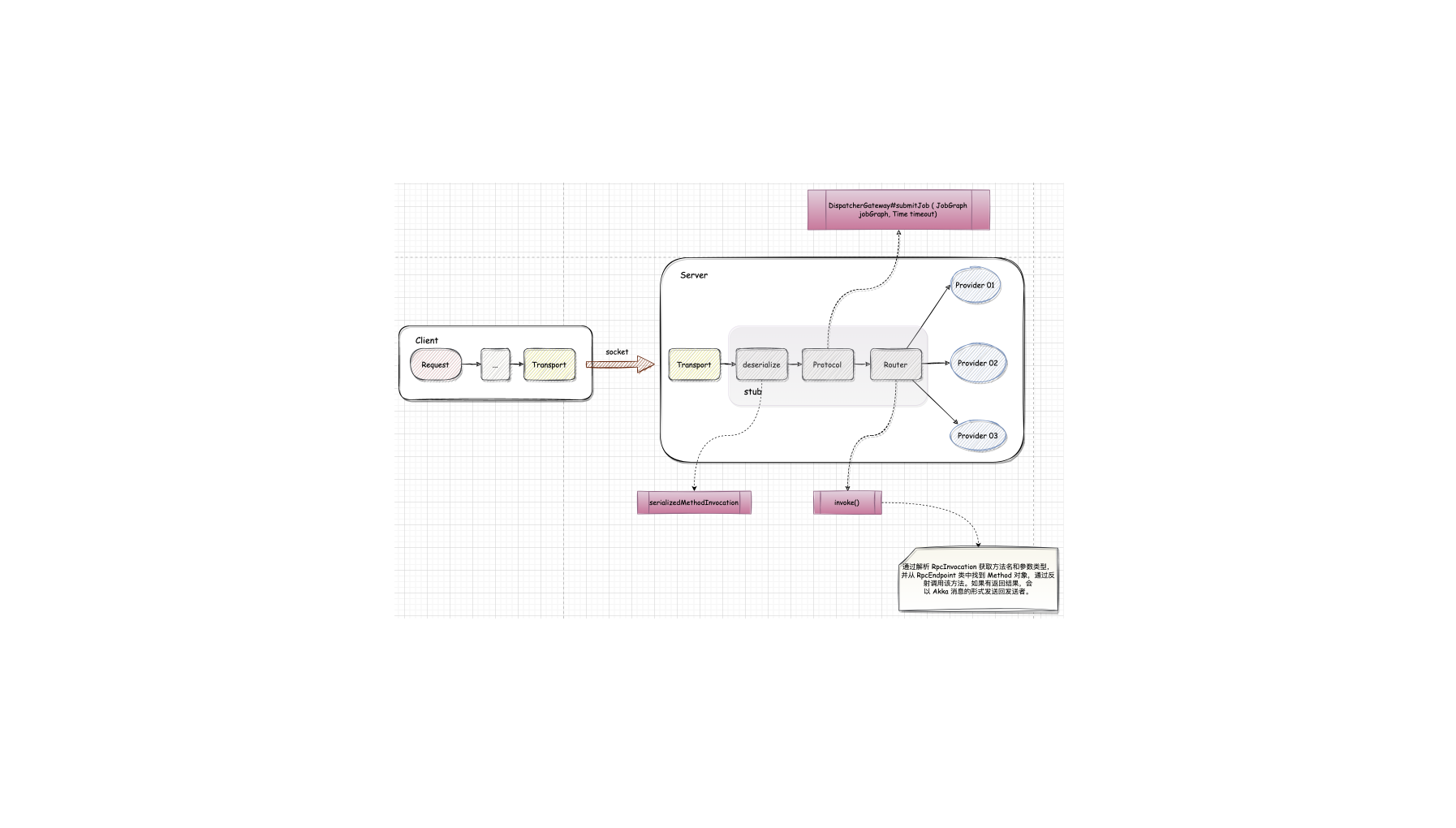
该步骤与 Session 模式下的不同,Client 并不会通过 Rest 向 Dispatcher 提交 JobGraph, 由 Dispatcher 从本地文件系统(Container 工作目录)获取 JobGraph,其后的步骤与 Session 模式一样。
2.1.3. 作业调度执行
与 Yarn Session 模式下一致。
2.2. Kubernetes Per-Job
这种模式会专门为每个 Job 任务创建一个单独的 Flink 集群,当资源描达文件被提交到 Kubenetes 集群,Kubernetes 会依次创建
FlinkMaster Deployment、 TaskManagerDeployment 并运行任务,任务完成后,这些 Deployment 会被自动清理。
2.2.1.启动集群
2.2.2. 作业提交
2.2.3. 作业调度执行
与 Yarn Session 模式下一致。
2.2.4. Native 模式
为什么叫 Native 方式 🤔️~
Flink 的 Client 内置了一个 K8s Client, 可以借助 K8s Client 去创建 JobManager,当 Job 提交之后,如果对资源有需求,
JobManager 会向 Flink 自己的 ResourceManager 去申请资源。这个时候 Flink 的 ResourceManager 会直接跟 K8s 的 API
Server 通信,将这些请求资源直接下发给 K8s Cluster,告诉它需要多少个 TaskManger,每个 TaskManager 多大。当任务运行
完之后,它也会告诉 K8s Cluster 释放没有使用的资源。
Native 是相对于 Flink 而言的,借助 Flink 的命令就可以达到自治的一个状态,不需要引入外部工具就可以通过 Flink 完成任务在
K8s 上的运行。
2.2.5. refer
三、总结
3.1. 集群生命周期
ResourceManger 会为每一个提交的作业启动一个 Flink 集群。作业完成,集群也会终止。集群的生命周期与作业的生命周期相关。
3.2. 资源隔离
资源隔离的粒度是作业,作业间不会相互影响。JobManager 挂掉,也只会影响到一个作业。 但是运行多个作业需要启动多个 Flink 集群,反复申请资源。
3.3. main() 执行位置
客户端
3.4. 适用场景
因为该模式资源隔离程度高,所以适合稳定性要求高的作业。该模式需要反复申请资源所以更适合长期运行,对启动时间不敏感的作用。
即该场景适合长期运行、稳定性要求高、对较长的启动时间不敏感的作业。
考虑到集群的资源隔离情况,一般生产上的任务都会选择per job模式,也就是每个任务启动一个flink集群,各个集群之间独立运行,互不影响,且每个集群可以设置独立的配置。
目前,对于 per-job 模式,jar 包的解析、生成 JobGraph 是在客户端上执行,然后将生成的 JobGraph 提交到集群。很多公司都会有自己的实时计算平台,用户可以使用这些平台提交 Flink 任务,如果任务特别多的话,那么这些生成 JobGraph 提交到集群的操作都会在实时平台所在的机器上执行,会给服务器造成很大的压力。
此外这种模式提交任务的时候会把本地 Flink 的所有 jar 包先上传到 hdfs 上相应的临时目录,这个也会带来大量的网络的开销,所以如果任务特别多的情况下,平台的吞吐量将会下降。
 微信
微信 支付宝
支付宝