












Spark-源码学习-SparkCore-调度机制-任务调度-Stage 调度
一、概述DAGScheduler 实现了面向 DAG 的高层次调度,通过计算将 DAG 中的一系列 RDD 划分到不同的 Stage,然后构建 Stage 之间的父子关系,最后将每个 Stage 按照 Partition 切分为多个 Task,并以 Task 集合(TaskSet)的形式提交给底层的 TaskScheduler。
二、实现2.1. DAGSchedulerEvent所有的组件都通过向 DAGScheduler 投递 DAGSchedulerEvent 来使用 DAGScheduler。
DAGScheduler 内部的 DAGSchedulerEventProcessLoop 根据不同的 DAGSchedulerEvent 事件(JobSubmitted、MapStageSubmitted…),并调用 DAGScheduler 的不同方法。
12345678private def doOnReceive(event: DAGSchedulerEvent): Unit = event match { case JobSubmitted(jobId, r ...

Spark-源码学习-SparkCore-调度机制-任务调度-Task 调度-调度池 Pool
一、概述TaskSchedulerImpl 对 Task 的调度依赖于调度池 Pool,所有需要被调度的 TaskSet 都被置于调度池中。调度池 Pool 通过调度算法对每个 TaskSet 进行调度,并将被调度的 TaskSet 交给 TaskSchedulerImpl 进行资源调度。
调度池内部有一个根调度队列,根调度队列中包含了多个子调度池。子调度池自身的调度队列中还可以包含其他的调度池或者TaskSetManager,整个调度池是一个多层次的调度队列。
二、调度算法调度池对 TaskSet 的调度取决于调度算法
2.1. FIFO 调度算法 FIFOSchedulingAlgorithm如果是采用 FIFO 调度策略,则直接简单地将 TaskSetManager 按照先来先到的方式入队,出队时直接拿出最先进队的 TaskSetManager
12345678910111213private[spark] class FIFOSchedulingAlgorithm extends SchedulingAlgorithm { override def comp ...
Spark-源码学习-SparkCore-调度机制-任务调度-Task 调度
一、概述二、TaskSetManagerDAGScheduler 将 Stage 打包到 TaskSet 交给 TaskScheduler, TaskSet 调度池中对 Task 进行调度管理的基本单位, TaskScheduler 会 将 TaskSet 封装为 TaskSetManager, 负责监控管理同一个 Stage 中的 Tasks, TaskScheduler 就是以 TaskSetManager 为单元来调度任务。
TaskSetManager 负责监控管理同一个 Stage 中的 Tasks,TaskScheduler 会 先 把 DAGScheduler 给 过 来 的 TaskSet 封装成 TaskSetManager 放到任务队列里,然后再按照指定的调度策略在调度队列中选择 TaskSetManager
引用本站文章
Spark-源码学习-SparkCore-调度机制-任务调度-Task 调度-TaskSetManager
...
Spark-源码学习-SparkCore-调度机制-任务调度-设计
一、概述一个 Spark Application 包括 Job、 Stage 以及 Task 三个概念:
Job
由于 Spark 的懒执行,在 driver 调用一个action 之前,spark application 不会做任何事情。针对每个 action,Spark调度器就创建一个执行图(execution.graph) 并且启动一个 Spark Job。
stage
每个 job 有多个 stage 组成,这些 stage 就是实现最终的RDD所需的数据转换的步骤,以 RDD 宽依赖为界,遇到宽依赖即划分 stage,
task
每个 stage 由多个 tasks 组成,这些 tasks 就表示每个并行计算并且会在多个执行器上执行
在 Spark 中,调度执行一个Job 总体分两路进行: Stage 级的调度和 Task 级的调度~
任务调度模块作为 Spark Core 的核心模块之一,充分地体现了与 MapReduce 完全不同的设计思想,主要包含两大部分,即 DAGScheduler和 TaskScheduler,它们负责将用户提交的计算任务按照D ...
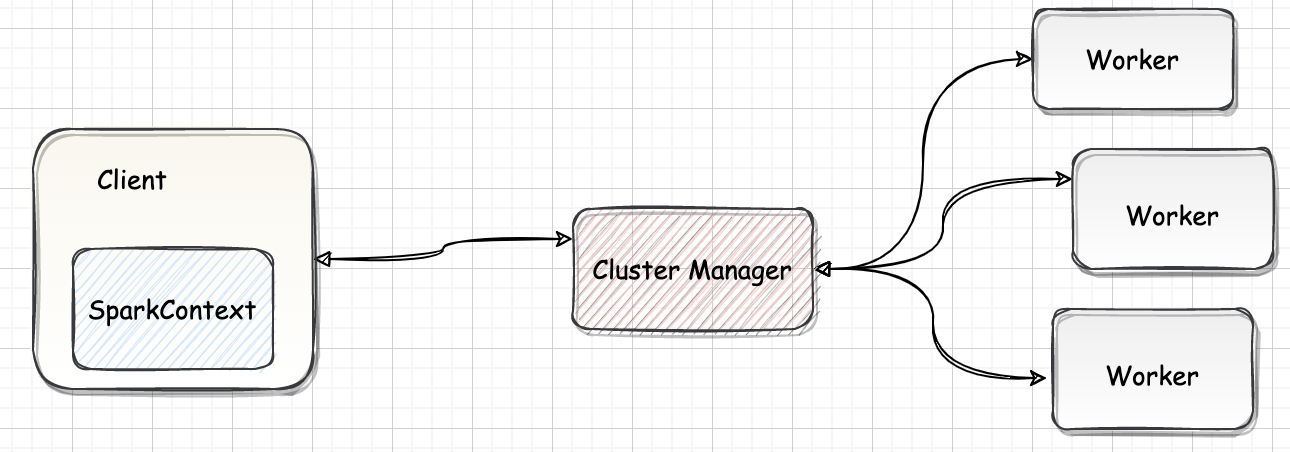
Spark-源码学习-SparkCore-调度机制-架构设计
一、概述Spark 调度模块分为资源调度和任务调度两个部分, 作业提交之后首先由资源调度系统为作业分配所需的计算资源,并创建 Driver 和 Executor实例;然后由任务调度系统通过解析作业的计算逻辑进一步划分 stage、创建 TaskSet 并根据调度算法将 TaskSet 分发到合适的 Executor 执行器上去运行。
二、资源调度Spark 的资源调度主要负责为当前提交的 Spark Application 申请资源,寻找集群空闲 Worker,根据集群资源在 Worker 上启动 Driver 和 Executor 进程。根据部署模式主要有 Standalone、Yarn、Kubernetes 以及 Mesos。
2.1. 部署模式2.1.1. standaloneStandalone 是 Spark 的原生调度方式,适用于小型或者测试集群。
引用本站文章
Spark-源码学习-SparkCore-调度机制-资源调度-Standalone
...
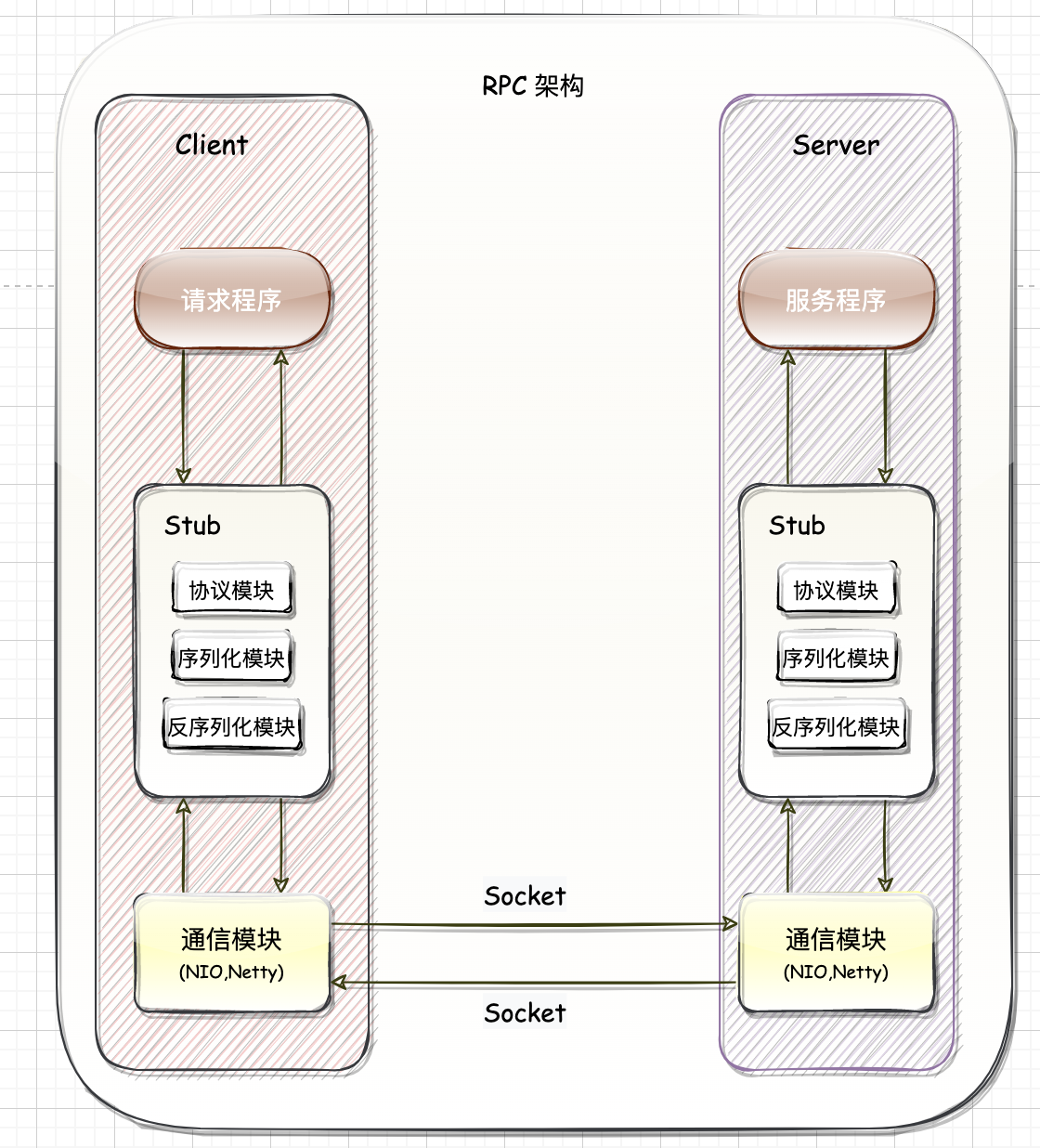
分布式通信
分布式系统可以总结为是处于不同物理位置的多个进程组成的整体,为了确保这个整体有效并且高效的对外提供服务,每个节点之间都有可能需要进行通信来交换信息,而这个交换信息的过程多数使用的是 tcp 协议。
一、RPCRPC 框架屏蔽了底层的网络传输,达到调用远程方法就像调用本地方法一样的效果
1.1. 组件一个 RPC 框架总结下来需要包括 5 块核心内容:客户端请求程序、客户端 Stub、通信模块、服务端Stud、服务端响应程序等。
1.1.1. 客户端
请求程序
客户端请求程序会像调用本地方法一样调用客户端 Stub 程序,然后接收 Stub 程序返回的响应信息。
客户端存根(Client Stub)
服务器和客户端都包括 Stub 程序。在客户端,Stub 程序表现得就像本地程序一样,底层会将调用请求和参数序列化并通过通信模块发送给服务器。之后 Stub 程序会等待服务器的响应信息,将响应信息反序列化并返回给请求程序。
Client Stub 就是将客户端请求的参数、服务名称、服务地址进行打包,统一发送给 server 方。
服务调用过程中,真正的方法逻辑存在于服务端中,那 ...
Spark-源码学习-SparkCore-调度机制-Master 资源调度
一、概述$Master.schedule()$ 为处于待分配资源的 Application 分配资源,调度当前 workers 可用的资源。在每次有新的 Application 加入或者新的资源加入时都会调用 $schedule()$ 进行调度。
$Master.schedule()$ 方法将在一个新的 Application 被提交,或者可用的 resource 变化的时候被调用。
二、设计2.1. 判断 Master 状态首先判断 Master 的状态不是 ALIVE 的时候,则直接 return
123if (state != RecoveryState.ALIVE) { return}
2.2. 选择 Worker对处于 ALIVE 状态的 Workers 进行 Shuffle
12val shuffledAliveWorkers = Random.shuffle(workers.toSeq.filter(_.state == WorkerState.ALIVE))val numWorkersAlive = shuffledAliveWorker ...
Flink-源码学习-架构设计-部署模式-Application-Flink On Kubernetes
正在总结中,等我😭~~~
Flink-源码学习-架构设计-部署模式-PerJob-Flink On Kubernetes
正在总结中,等我😭~~~
Flink-源码学习-集群启动-kubernetes-application
正在总结中,等我😭~~~
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.















