Spark-源码学习-SparkCore-调度机制-架构设计
一、概述
Spark 调度模块分为资源调度和任务调度两个部分, 作业提交之后首先由资源调度系统为作业分配所需的计算资源,并创建 Driver 和 Executor实例;然后由任务调度系统通过解析作业的计算逻辑进一步划分 stage、创建 TaskSet 并根据调度算法将 TaskSet 分发到合适的 Executor 执行器上去运行。
二、资源调度
Spark 的资源调度主要负责为当前提交的 Spark Application 申请资源,寻找集群空闲 Worker,根据集群资源在 Worker 上启动 Driver 和 Executor 进程。根据部署模式主要有 Standalone、Yarn、Kubernetes 以及 Mesos。
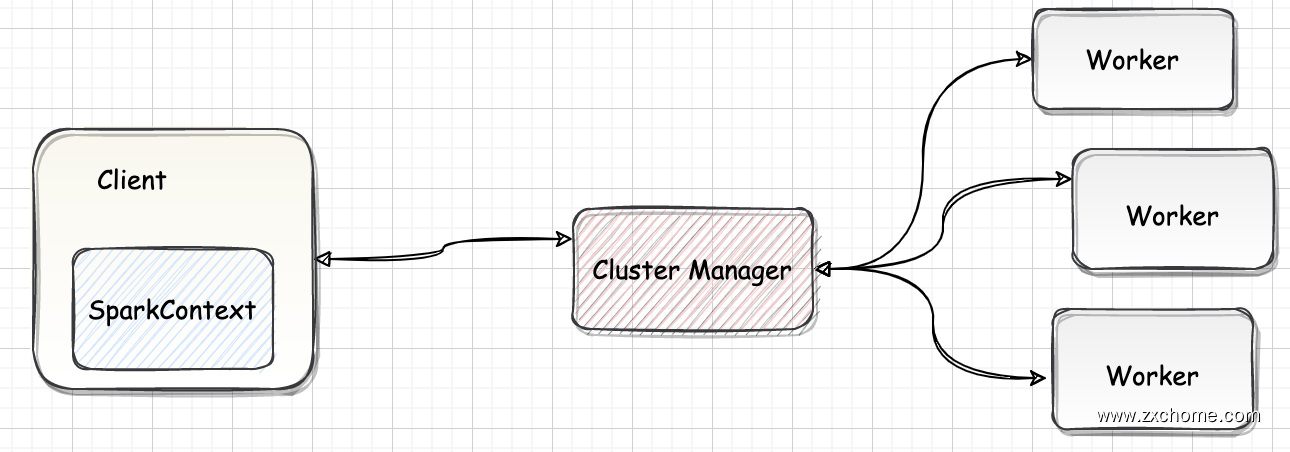
2.1. 部署模式
2.1.1. standalone
Standalone 是 Spark 的原生调度方式,适用于小型或者测试集群。
2.1.2. Yarn
当提交作业时使用 --master yarn 参数时,Spark 作业将会被调度至 Yarn 集群上去运行,基于 Yarn 的调度可适用于大型高并发的企业集群;
Yarn 作为 Hadoop 项目一部分,是业内应用非常广泛的资源调度器,支持 FIFO、Fair、Capacity 多种调度模式,并进一步定制资源分配和调度策略, 为用户提供了灵活的调度框架; 同时还支持多租户资源隔离和资源争抢,可以达到资源隔离和集群资源使用率的平衡。
Yarn 通过 ApplicationMaster 来负责作业的资源申请以及任务的调度, 而 ResourceManager 则负责集群资源的统一管理和分配。
2.1.3. Kubernetes
提交作业时使用 --master k8s://apiserver:port 参数则可以将应用调度到K8S集群运行;
Spark 从 2.4 开始支持使用 Kubernetes 进行资源调度,Spark on Kubernetes 可以方便地实现存算分离和计算资源的弹性伸缩,极大方便了业务的快速拓展, 同时还可以提高硬件资源的利用率并节约成本
Kubernetes 的调度器 kube-scheduler 根据指定的调度算法在合适的 node 节点上启动 driver pod 和 executor pod。
三、任务调度
资源调度结束后,运行 Application 资源有了,开始进行任务的调度~
一个 Spark Application 包括 Job、Stage 以及 Task 三个概念:
- Job 是以 Action 算子为界,遇到一个 Action 算子则触发一个 Job;
- Stage 是 Job 的子集,以 RDD 宽依赖 ShuffleDependency 为界,遇到 Shuffle 做一次划分;
- Task 是 Stage 的子集,以并行度(分区数)来衡量,这个 Stage 分区数是多少,则这个 Stage 就有多少个 Task。
Spark 的任务调度总体来说分两路进行,一路是 Stage 级的调度,一路是 Task 级的调度,总体调度流程如下图所示:

 微信
微信 支付宝
支付宝