











Spark-源码学习-通信服务-架构设计-路由层
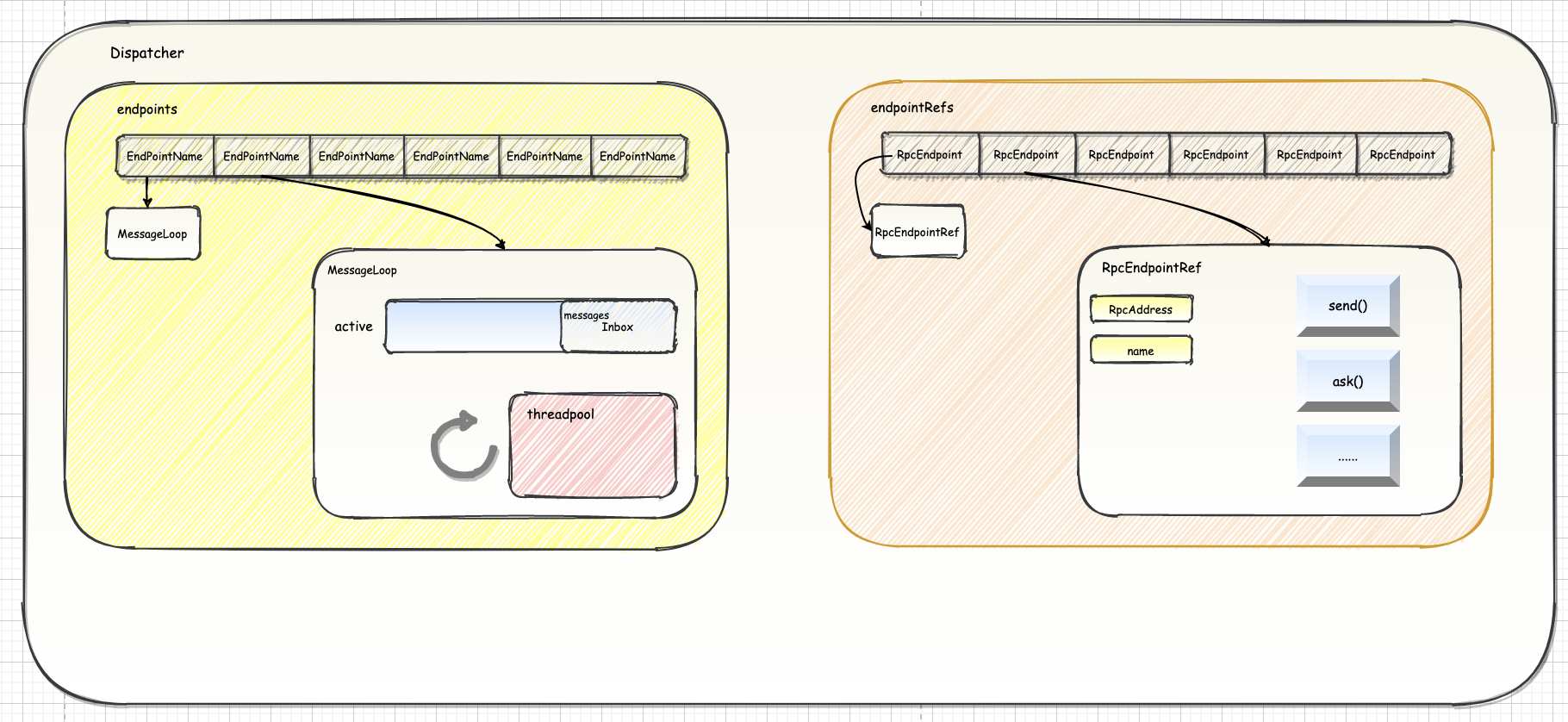
一、概述Spark RPC 路由层负责将 RPC 消息路由到要该对此消息处理的 RpcEndpoint。在 Spark 中,RpcEndpoint 使用 Dispatcher、Inbox 和 Outbox 三个组件进行消息路由。当一个 RpcEndpoint 接收到来自远程进程的消息时,Dispatcher 会将消息存储在 RpcEndpoint 的 Inbox 中,然后 RpcEndpoint 的线程会从 Inbox 中取出消息并处理它。当 RpcEndpoint 需要向远程进程发送消息时,它会使用 Outbox 将消息发送到远程进程的 Dispatcher。
二、架构设计2.1. 消息分发器 Dispatcher消息分发器 Dispatcher 是有效提高 NettyRpcEnv 对消息异步处理并最大提升并行处理能力的前提。
引用本站文章
Spark-源码学习-通信服务-架构设计-路由层-Dispatcher
Joker
...

Spark-源码学习-SparkSQL-Join 体系-逻辑计划生成
一、概述逻辑计划阶段的开始由 AstBuilder 将抽象语法树 AST 生成 Unresolved LogicalPlan,然后在此基础上经过解析得到 Analyzed LogicalPlan,最后经过优化得到 Optimized LogicalPlan。
二、生成2.1. 从 AST 到 Unresolved LogicalPlan与 Join 算子相关的部分主要在 From 子句中,具体看,逻辑计划生成过程由 AstBuilder 类定义的 $visitFromClause()$ 方法开始,其核心代码如下:
从 FromClauseContext 中得到的 relation 是 RelationContext 的列表。根据前面的文法分析可知,每个 RelationContext 代表一个通过 Join 连接的数据表集合,每个 RelationContext 中有一个主要的数据表 RelationPrimaryContext 和多个需要 Join 连接的表 JoinRelationContext。
针对 RelationContext 对象列表进行 $foldLeft$ ...
Spark-源码学习-SparkSQL-Join 体系-物理计划-Join 生成
一、概述相比单机环境,分布式环境中的数据关联在计算环节依然遵循着 NLJ、SMJ 和 HJ 这 3 种实现方式,只不过是增加了网络分发这一变数。在 Spark 的分布式计算环境中,数据在网络中的分发主要有两种方式,分别是 Shuffle 和 Broadcast。
2.1. Shuffle采用 Shuffle 的分发方式来完成数据关联,那么外表和内表都需要按照 Join Key 在集群中做数据分发。因为只有这样,两个数据表中 Join Key 相同的数据记录才能分配到同一个 Executor 进程,从而完成关联计算
2.2. Broadcast采用广播机制下,Spark 只需要把内表封装到广播变量,然后进行分发。由于广播变量中包含了内表的全量数据,因此体量较大的外表只要“待在原地、保持不动”,就能完成关联计算
结合 Shuffle、广播这两种网络分发方式和 NLJ、SMJ、HJ 这 3 种计算方式,对于分布式环境下的数据关联,就能组合出 6 种 Join 策略
从执行性能来说,6 种策略从上到下由弱变强。相比之下,CPJ 的执行效率是所有实现方式当中最差的,网络开销、计算开 ...
Spark-源码学习-SparkSQL-Join 体系-物理计划-Join 选择
一、概述在生成物理计划的过程中,JoinSelection 根据若干条件判断采用何种类型的 Join 执行方式。 目前在 Spark SQL 中, Join 的执行方式主要有 BroadcastHashJoinExec (BHJ)、 ShuffledHashJoinExec (SHJ)、SortMergeJoinExec (SMJ)、BroadcastNestedLoopJoinExec (BNLJ) 和 CartesianProductExec (CPJ) 这 5 种。
等值 Join
在等值数据关联中,Spark 会尝试按照 BHJ > SHJ > SMJ 的顺序依次选择 Join 策略
不等值 Join
不等值 Join 只能使用 NLJ 来实现,因此 Spark SQL 可选的 Join 策略只剩下 BNLJ 和 CPJ。在同一种计算模式下,相比 Shuffle,Broadcast 的网络开销更小。Spark SQL 会按照 BNLJ > CPJ 的顺序进行尝试。BNLJ 生效的前提自然是内表小到可以放进广播变量,否则 Spark SQL 用 CPJ ...
Akka 概述
一、什么是 Akka?Akka 基于 Actor 并发模型,提供了一个用于构建可扩展的(Scalable)、弹性的(Resilient)、快速响应的(Responsive) 应用程序的平台。
1.1. Actor 模型Actor 模型被提出的初衷是解决并行处理的问题。在传统的面向对象模型下,完成一套复杂的逻辑功能,需要创建一些对象,每个对象包含一些方法,然后方法之间调来调去。在这个框架下,通常通过多线程来实现并行计算,涉及了线程阻塞的问题,以及资源冲突和锁的问题,代码的设计和编写变得复杂。
那 Actor 模型是怎么解决阻塞和锁的问题呢🤔️~
Actor 模型把一套复杂功能拆分成不同的 actor,不同的 actor 完成不同的逻辑,actor 之间通过传递消息来进行交互。不同于方法的调用,actor 在发出消息后不需要等待返回,因此 actor 在发送消息后可以马上继续执行,避免了阻塞。
一个 actor 同时最多只能处理 1 条消息,并且消息是不可变的,也就不再需要锁了。
mapReduce 其实就可以理解为一种 actor 模型~
Actor 模型中并不是通过 ...
Spark-源码学习-SparkSession-SparkContext 设计
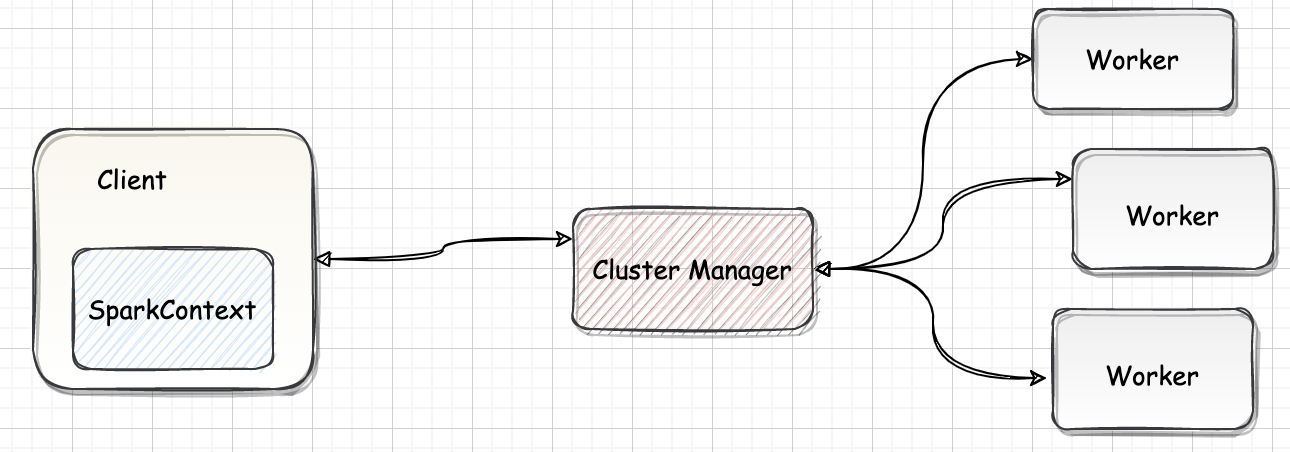
一、概述SparkContext 是 Spark 的入口,相当于应用程序的 $main$ 函数。目前在一个 JVM 进程中可以创建多个 SparkContext,但是只能有一个 active 级别的。如果需要创建一个新的 SparkContext 实例,必须先调用 $stop$ 方法停掉当前 active 级别的 SparkContext 实例。
SparkContext 处于 DriverProgram 核心位置,所有与 ClusterManager、Worker 交互的操作都需要 SparkContext 来完成。
二、设计SparkContext 包含了 Spark 程序用到的几乎所有核心对象,创建 SparkContext 时会添加一个钩子到 ShutdownHookManager 中用于在 Spark 程序关闭时对核心对象进行清理,在创建 RDD 等操作也会判断 SparkContext 是否已 $stop$ ;通常情况下一个 Driver 只会有一个 SparkContext 实例,但可通过 spark.driver.allowMultipleContexts 配置 ...

Spark-源码阅读环境搭建
一、编译
引用站外地址,不保证站点的可用性和安全性
Spark 编译
spark.apache.org
1.1. 下载源码123456789101112131415$ lsCONTRIBUTING.md conf mllib-localLICENSE connector pom.xmlLICENSE-binary core projectNOTICE data pythonNOTICE-binary dev replR docs resource-managersREADME.md ...
Flink-源码学习-FlinkSQL&Table-Planner 设计
一、概述从 Flink 1.9 开始,Flink 提供了两种不同的 Planner 实现来执行 Table & SQL API 程序:
Blink Planner:Flink 1.9+
Old Planner:Flink 1.9 之前
在 1.14 新版本中,Old Planner 被移除,Blink Planner 将成为 Planner 的唯一实现
https://mp.weixin.qq.com/s/KaRjvtfLHJRqfmf1790chQ
二、Planner二、流程一段查询 SQL / 使用TableAPI 编写的程序从输入到编译为可执行的 JobGraph 主要经历如下几个阶段
将 SQL文本 / TableAPI 代码转化为逻辑执行计划(Logical Plan)
Logical Plan 通过优化器优化为物理执行计划(Physical Plan)
通过代码生成技术生成 Transformations 后进一步编译为可执行的 JobGraph 提交运行
SQL语句经过Calcite解析生成抽象语法树SQLNode,基于生成的SQLNode并结合fli ...
Flink-源码系列
一、架构设计Flink 是一个批流一体的分布式计算引擎,作为一个分布式计算引擎,必须提供面向开发人员的 API,根据业务逻辑开发 Flink 作业,作业除了包含业务逻辑外,还需要跟外部的数据存储进行交互。作业开发、测试完华后,交给 Flink 集群进行执行,同时还要让运维人员能够管理与监控 Flink。
引用本站文章
Flink-源码学习-Flink 架构设计
Joker
二、阅读环境准备
引用本站文章
Flink-源码阅读环境搭建
Joker
三、集群启动
引用本站文章
...
Flink-理论笔记系列
正在总结中,等我😭~~~
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.















