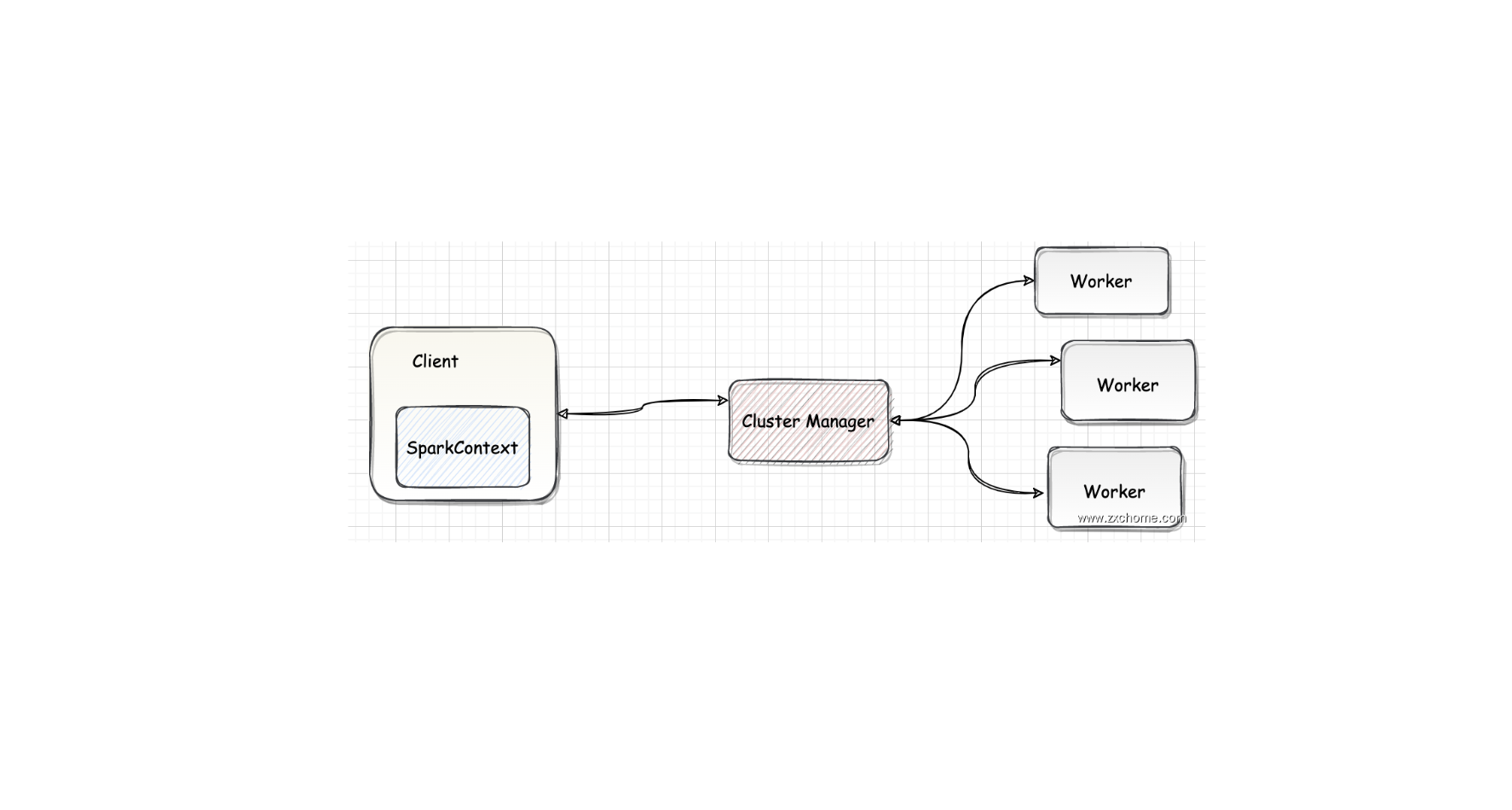
一、编译
引用站外地址,不保证站点的可用性和安全性
Spark 编译
spark.apache.org
1.1. 下载源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| $ ls
CONTRIBUTING.md conf mllib-local
LICENSE connector pom.xml
LICENSE-binary core project
NOTICE data python
NOTICE-binary dev repl
R docs resource-managers
README.md examples sbin
appveyor.yml graphx scalastyle-config.xml
assembly hadoop-cloud sql
bin launcher streaming
binder licenses target
build licenses-binary tools
common mllib
(base)
|
1.2. maven
maven 配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| <mirrors>
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云spring插件仓库</name>
<url>https://maven.aliyun.com/repository/spring-plugin</url>
</mirror>
<mirror>
<id>repo2</id>
<name>Mirror from Maven Repo2</name>
<url>https://repo.spring.io/plugins-release/</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirror>
<id>UK</id>
<name>UK Central</name>
<url>http://uk.maven.org/maven2</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirror>
<id>jboss-public-repository-group</id>
<name>JBoss Public Repository Group</name>
<url>http://repository.jboss.org/nexus/content/groups/public</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirror>
<id>CN</id>
<name>OSChina Central</name>
<url>http://maven.oschina.net/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirror>
<id>google-maven-central</id>
<name>GCS Maven Central mirror Asia Pacific</name>
<url>https://maven-central-asia.storage-download.googleapis.com/maven2/</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirror>
<id>confluent</id>
<name>confluent maven</name>
<url>http://packages.confluent.io/maven/</url>
<mirrorOf>confluent</mirrorOf>
</mirror>
</mirrors>
|
1.3. 编译
maven 编译方式
这种编译方式最后会编译成一个 jar 包~
1
| ./build/mvn -T 16 -DskipTests clean package
|
sbt
使用 make-distribution.sh 命令
Spark 自带了一个编译命令: make-distribution.sh, 修改文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| #VERSION=$("$MVN" help:evaluate -Dexpression=project.version $@ 2>/dev/null | grep -v "INFO" | tail -n 1)
#SCALA_VERSION=$("$MVN" help:evaluate -Dexpression=scala.binary.version $@ 2>/dev/null\
#SPARK_HADOOP_VERSION=$("$MVN" help:evaluate -Dexpression=hadoop.version $@ 2>/dev/null\
#SPARK_HIVE=$("$MVN" help:evaluate -Dexpression=project.activeProfiles -pl sql/hive $@ 2>/dev/null\
# echo -n)
VERSION=3.3.0
SCALA_VERSION=2.12
SPARK_HADOOP_VERSION=2.7.3
SPARK_HIVE=1
|
执行命令:
1
| ./dev/make-distribution.sh --tgz -Phadoop-2.7 -Pyarn -DskipTests
|
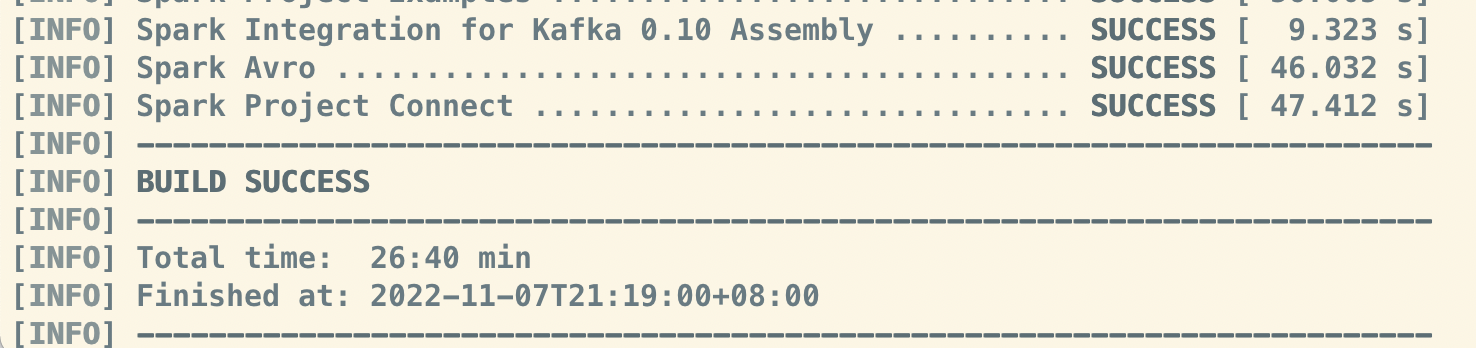
如果一切顺利, 会在目录下生成目标文件:

二、部署
为了部署方便, 简单写了个简陋的一键部署脚本💪~

1
2
3
| git clone https://gitee.com/Joccer_admin/chen-utils-manager.git
cd chen-utils-manager
./chen-utils-manager.sh -m spark
|
三、调试
3.1. local
local 调试只需要配置如图所示的两处地方就可以啦~
添加 VM options : -Dspark. master=local
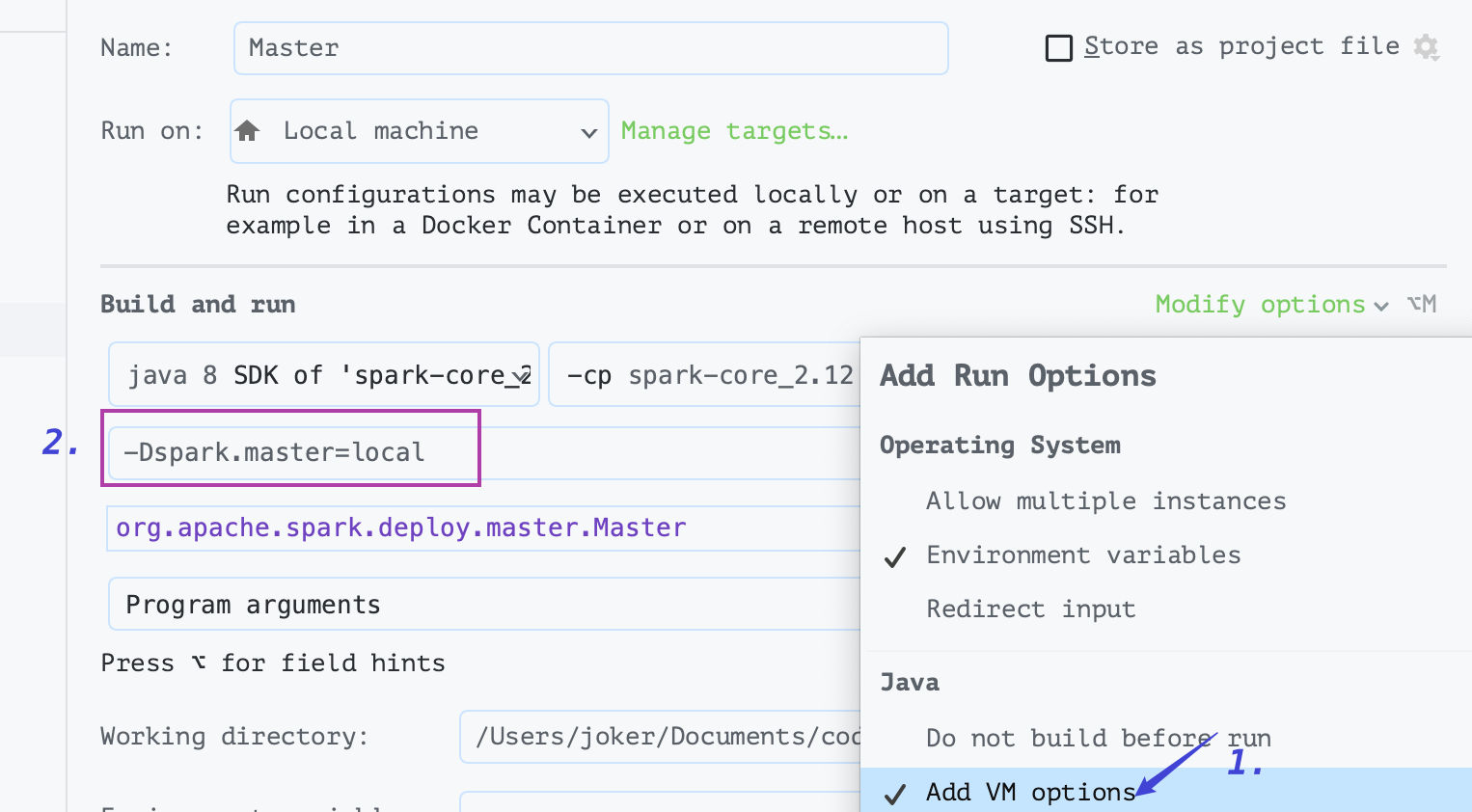
ADD DEPENDENCIES WITH "PROVIDED" SCOPE TO CLASSPATH

一定要有第二步操作: ADD DEPENDENCIES WITH "PROVIDED" SCOPE TO CLASSPATH, 否则会报 xxxx class not fount 异常
看下效果~
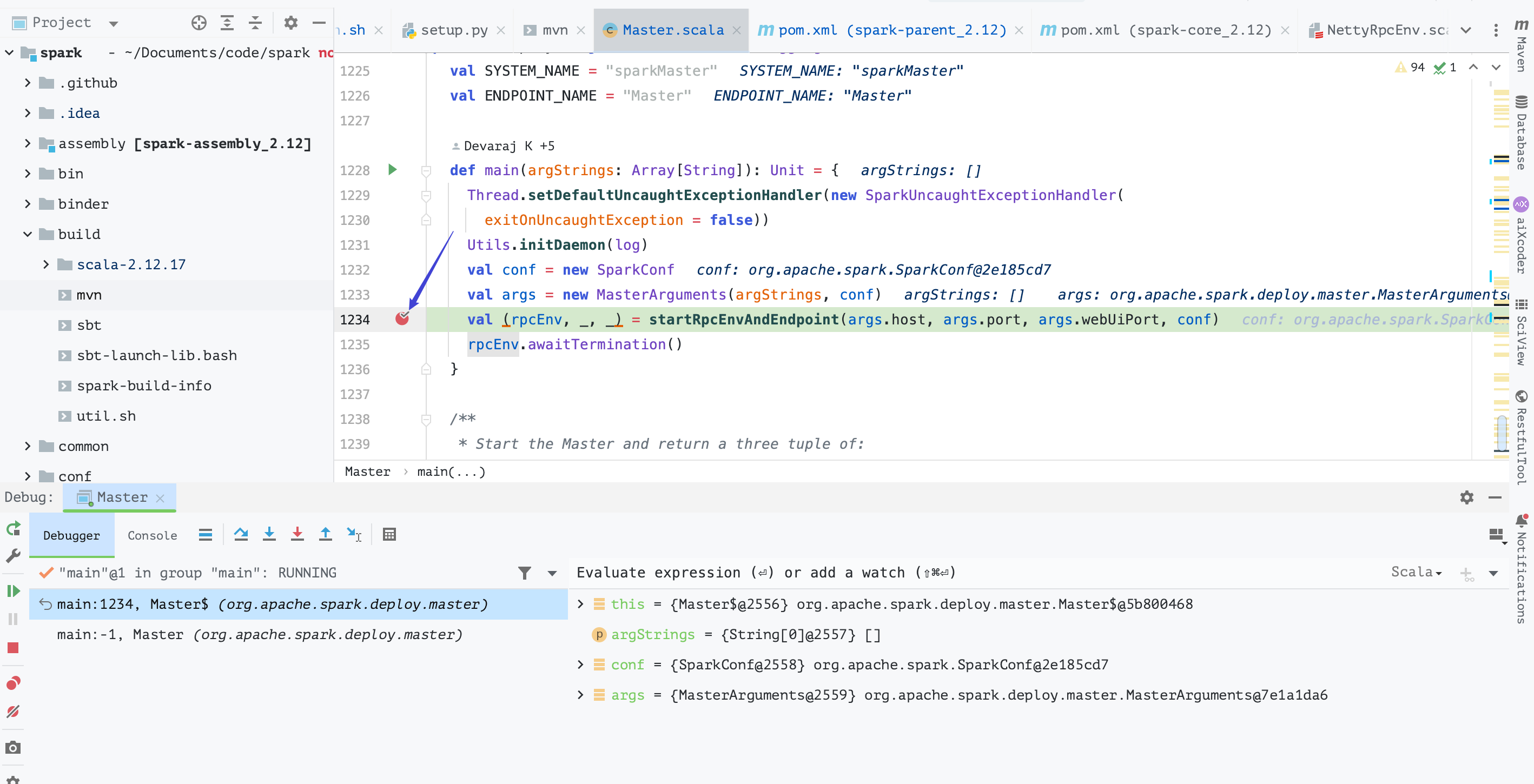
3.2. standalone
在 spaek-env.sh 里加入:
1
| export SPARK_MASTER_OPTS="-Xdebug -Xrunjdwp:transport=dt_socket,address=8003,server=y,suspend=y"
|
启动 start-master.sh~
1
2
| $ ./sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/opt/spark/spark-3.3.0-bin-2.7.3/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.out
|
查看 jps:
1
2
3
| $ jps
62833 Jps
62795 -- main class information unavailable
|
配置 idea 去连接 master:

看下控制台的提示:
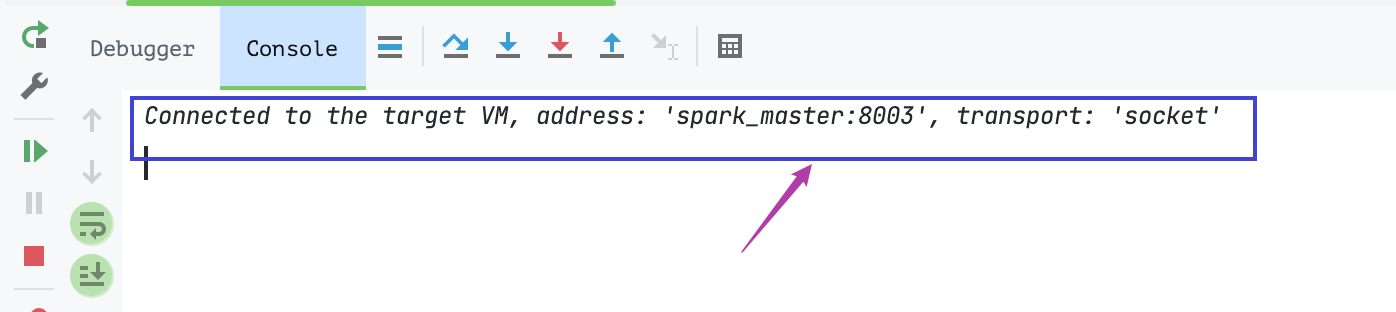
连接上远程的 spark master 啦~, 开始我们的学习之路~


 微信
微信 支付宝
支付宝