
云原生-相关技术-容器化-容器编排-Kubernetes-理论笔记-架构设计
当前最具代表性的容器编排工具,当属 Docker 公司的 Compose+Swarm 组合,以及 Google 与 RedHat 公司共同主导的 Kubernetes 项目
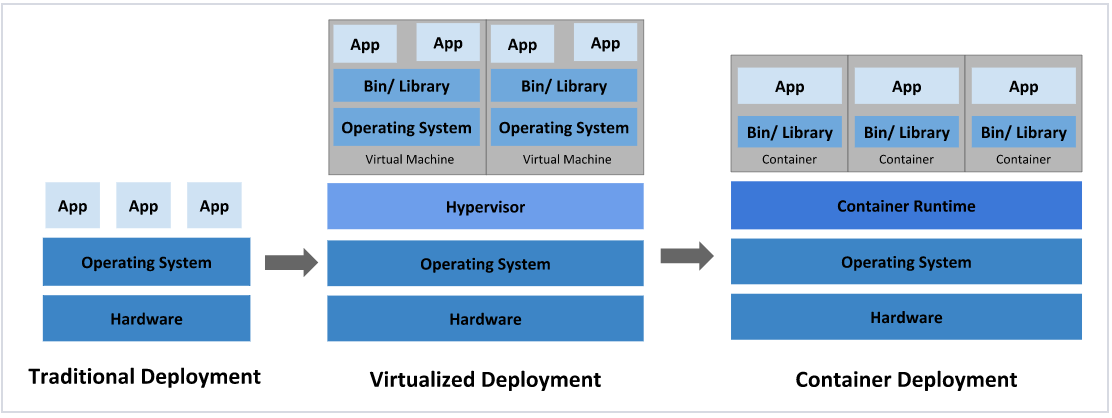
在部署应用程序的方式上,主要经历了三个时代:
传统部署:互联网早期,会直接将应用程序部署在物理机上
优点:简单,不需要其它技术的参与
缺点:不能为应用程序定义资源使用边界,很难合理地分配计算资源,而且程序之间容易产生影响
虚拟化部署:可以在一台物理机上运行多个虚拟机,每个虚拟机都是独立的一个环境
优点:程序环境不会相互产生影响,提供了一定程度的安全性
缺点:增加了操作系统,浪费了部分资源
容器化部署:与虚拟化类似,但是共享了操作系统
优点:
可以保证每个容器拥有自己的文件系统、CPU、内存、进程空间等
运行应用程序所需要的资源都被容器包装,并和底层基础架构解耦
容器化的应用程序可以跨云服务商、跨Linux操作系统发行版进行部署
容器化部署方式给带来很多的便利,但是也会出现一些问题,比如说:
- 一个容器故障停机了,怎么样让另外一个容器立刻启动去替补停机的容器
- 当并发访问量变大的时候,怎么样做到横向扩展容器数量
这些容器管理的问题统称为容器编排问题,为了解决这些容器编排问题,就产生了一些容器编排的软件:
- Swarm:Docker自己的容器编排工具
- Mesos:Apache的一个资源统一管控的工具,需要和Marathon结合使用
- Kubernetes:Google开源的的容器编排工具
kubernetes,是一个基于容器技术的分布式架构方案,是谷歌 Borg 系统的一个开源版本,于2014年9月发布第一个版本,2015年7月发布第一个正式版本。
kubernetes的本质是一组服务器集群,它可以在集群的每个节点上运行特定的程序,来对节点中的容器进行管理。目的是实现资源管理的自动化,主要提供了如下的主要功能:
- 自我修复:一旦某一个容器崩溃,能够在1秒中左右迅速启动新的容器
- 弹性伸缩:可以根据需要,自动对集群中正在运行的容器数量进行调整
- 服务发现:服务可以通过自动发现的形式找到它所依赖的服务
- 负载均衡:如果一个服务起动了多个容器,能够自动实现请求的负载均衡
- 版本回退:如果发现新发布的程序版本有问题,可以立即回退到原来的版本
- 存储编排:可以根据容器自身的需求自动创建存储卷
一、概述
Kubernetes 项目的架构,跟它的原型项目 Borg 类似,由 Master 和 Node 两种节点组成,这两种角色分别对应着控制节点和计算节点。
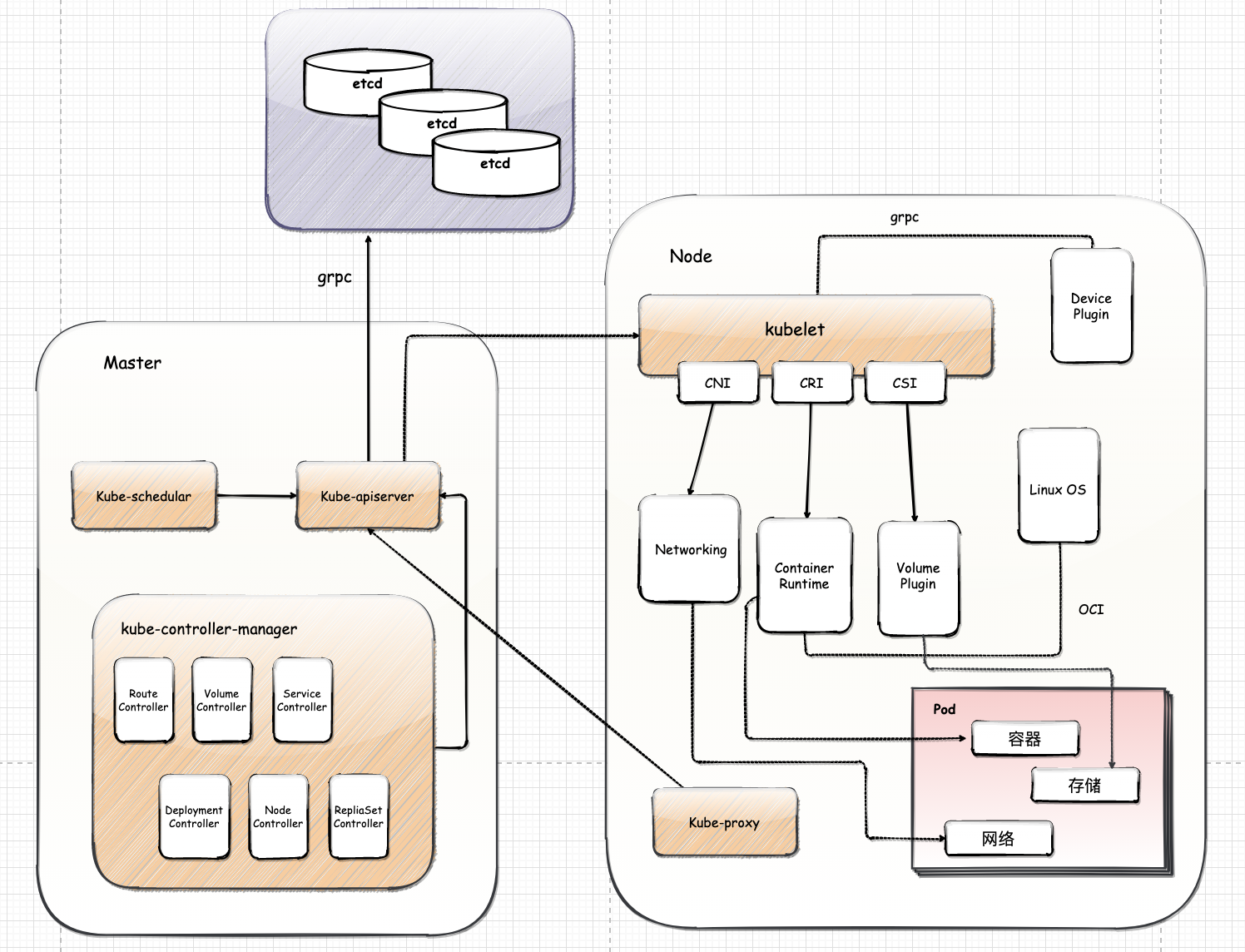
控制节点 Master 节点
由三个紧密协作的独立组件组合而成
负责 API 服务的 kube-apiserver
负责调度的 kube-scheduler
负责容器编排的 kube-controller-manager。
整个集群的持久化数据,则由
kube-apiserver处理后保存在 Etcd 中。计算节点 Worker Node
最核心的部分是 kubelet 组件
kubelet 主要负责同容器运行时(比如 Docker 项目)进行交互。而这个交互所依赖的,是一个称作 CRI (Container Runtime Interface) 的远程调用接口,这个接口定义了容器运行时的各项核心操作
比如启动一个容器需要的所有参数
etcd
在生产环境中应该以 etcd 集群的方式运行以确保其服务可用性。etcd 负责保存 Kubernetes Cluster 的配置信息和各种资源的状态信息。当数据发生变化时,etcd会快速地通知 Kubernetes 相关组件。
API Server 是 Kubernetes 集群中唯一能够与 etcd 通信的组件。
二、控制节点 Master
Master 是集群的网关和中枢,负责诸如为用户和客户端暴露API、确保各资源对象不断地逼近或符合用户期望的状态、以最优方式调度工作负载,以及编排其他组件之间的通信等任务,它是各类客户端访问集群的唯一入口,肩负Kubernetes系统上大多数集中式管控逻辑。
Master 主要由 API Server(kube-apiserver)、Controller-Manager(kube-controller-manager)和Scheduler(kube-scheduler)这3个组件,以及一个用于集群状态存储的 etcd 存储服务组成
2.1. API Server
API Server 是 Kubernetes Cluster 的前端接口,各种客户端工具(CLI或UI)以及 Kubernetes 其他组件可以通过它管理 Cluster 的各种资源。
2.2. 控制器管理器 Controller-Manager
Controller Manager 负责管理 Cluster 各种资源,保证资源处于预期的状态。Controller Manager 由多种 controller 组成
2.3. 调度器 kube-scheduler
Kubernetes系统上的调度是指为 API Server 接收到的每一个Pod创建请求,并在集群中为其匹配出一个最佳工作节点。kube-scheduler 是默认调度器程序,它在匹配工作节点时的考量因素包括硬件、软件与策略约束,亲和力与反亲和力规范以及数据的局部性等特征
三、计算节点 Worker Node
负责接收来自 Master 的工作指令并相应创建或销毁 Pod 对象,以及调整网络规则以合理完成路由和转发流量等任务,是Kubernetes集群的工作节点,每个Node节点则主要包含kubelet、kube-proxy 及容器运行时(Docker是最为常用的实现)3个组件,它们承载运行各类应用容器
3.1. kubelet
kubelet 是 Kubernetes 中最重要的组件之一,kubelet 是 Node 的 agent,当 Scheduler 确定在某个 Node 上运行 Pod 后,会将 Pod 的具体配置信息(image、volume等)发送给该节点的 kubelet,kubelet 根据这些信息创建和运行容器,并向 Master 报告运行状态。
和容器运行时交互
kubelet 负责同容器运行时(比如 Docker 项目)进行交互。这个交互所依赖的,是一个称作 CRI (Container Runtime Interface) 的远程调用接口,这个接口定义了容器运行时的各项核心操作
比如:启动一个容器需要的所有参数
Kubernetes 项目并不关心你部署的是什么容器运行时、使用的什么技术实现,只要你的这个容器运行时能够运行标准的容器镜像,它就可以通过实现 CRI 接入到 Kubernetes 项目当中,而具体的容器运行时,比如 Docker 项目
从一开始,Kubernetes 项目就没有像同时期的各种容器云项目那样,把 Docker 作为整个架构的核心,而仅仅把它作为最底层的一个容器运行时实现。
和 Device Plugin 的插件进行交互
kubelet 还通过 gRPC 协议和 Device Plugin 的插件进行交互。Device Plugin 是 Kubernetes 项目用来管理 GPU 等宿主机物理设备的主要组件,也是基于 Kubernetes 项目进行机器学习训练、高性能作业支持等工作必须关注的功能
调用网络插件容器配置网络
网络插件与 kubelet 进行交互的接口是 CNI (Container Networking Interface)
调用存储插件为容器配置持久化存储
存储插件与 kubelet 进行交互的接口是 CSI (Container Storage Interface)
3.1.1. 工作原理
kubelet 的工作核心,就是一个控制循环,即:SyncLoop
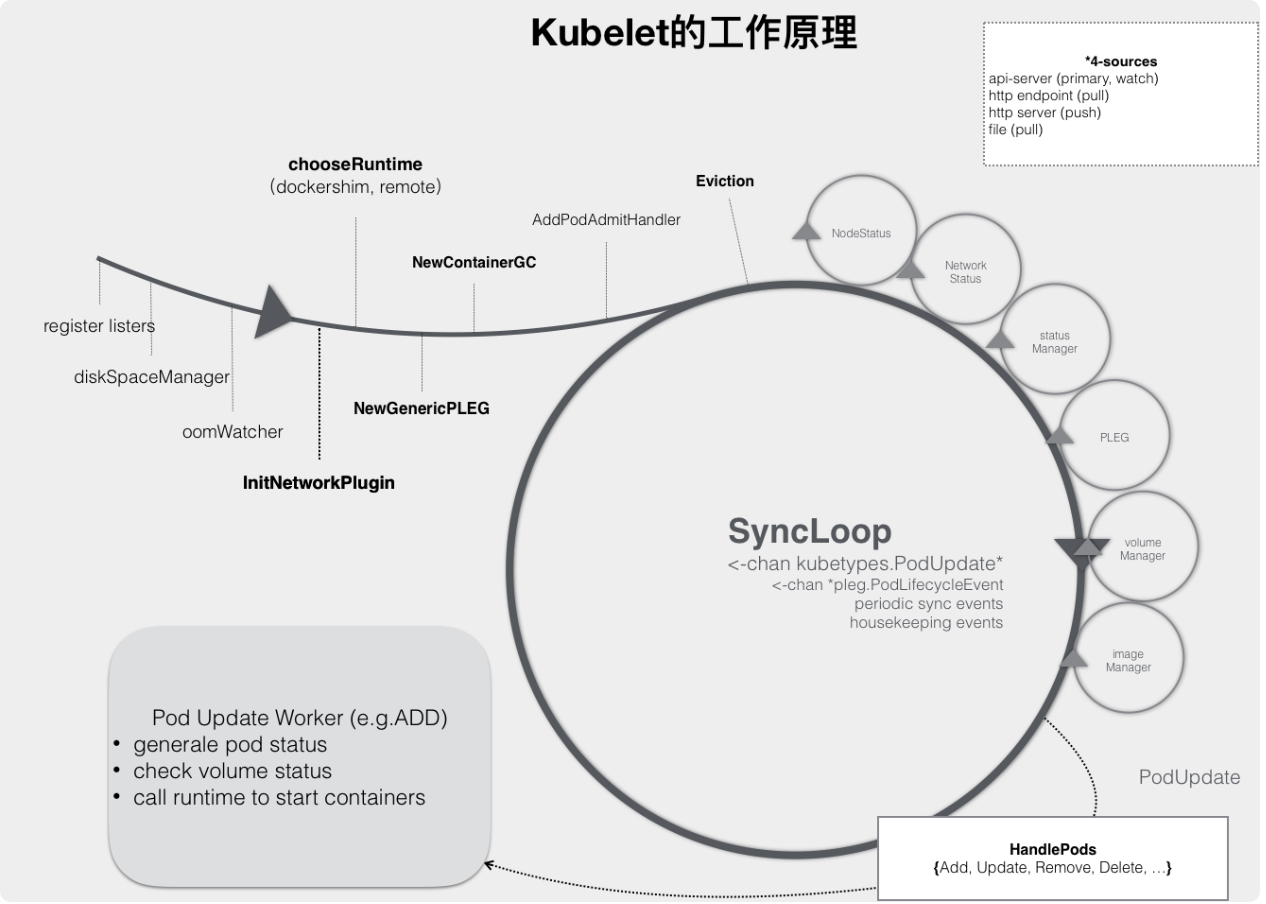
驱动这个控制循环运行的事件,包括四种:
- Pod 更新事件
- Pod 生命周期变化
- kubelet 本身设置的执行周期
- 定时的清理事件
kubelet 还负责维护着很多很多其他的子控制循环(图中的小圆圈),比如:
Volume Manager
Image Manager
Node Status Manager
负责响应 Node 的状态变化,然后将 Node 的状态收集起来,并通过 Heartbeat 的方式上报给 APIServer
当一个 Pod 完成调度、与一个 Node 绑定起来之后, 这个 Pod 的变化就会触发 kubelet 在控制循环里注册的 Handler,也就是上图中的 HandlePods 部分
kubelet 会启动一个名叫 Pod Update Worker 的、单独的 Goroutine 来完成对 Pod 的处理工作。如果是 ADD 事件的话,kubelet 就会为这个新的 Pod 生成对应的 Pod Status,检查 Pod 所声明使用的 Volume 是不是已经准备好。然后,调用下层的容器运行时(比如 Docker),开始创建这个 Pod 所定义的容器。而如果是 UPDATE 事件的话,kubelet 就会根据 Pod 对象具体的变更情况,调用下层容器运行时进行容器的重建工作。
注意: kubelet 调用下层容器运行时的执行过程,并不会直接调用 Docker 的 API,而是通过一组叫作 CRI(Container Runtime Interface,容器运行时接口) 的 gRPC 接口来间接执行的。Kubernetes 项目之所以要在 kubelet 中引入这样一层单独的抽象,当然是为了对 Kubernetes 屏蔽下层容器运行时的差异。
对于 1.6 版本之前的 Kubernetes 来说,它就是直接调用 Docker 的 API 来创建和管理容器的。
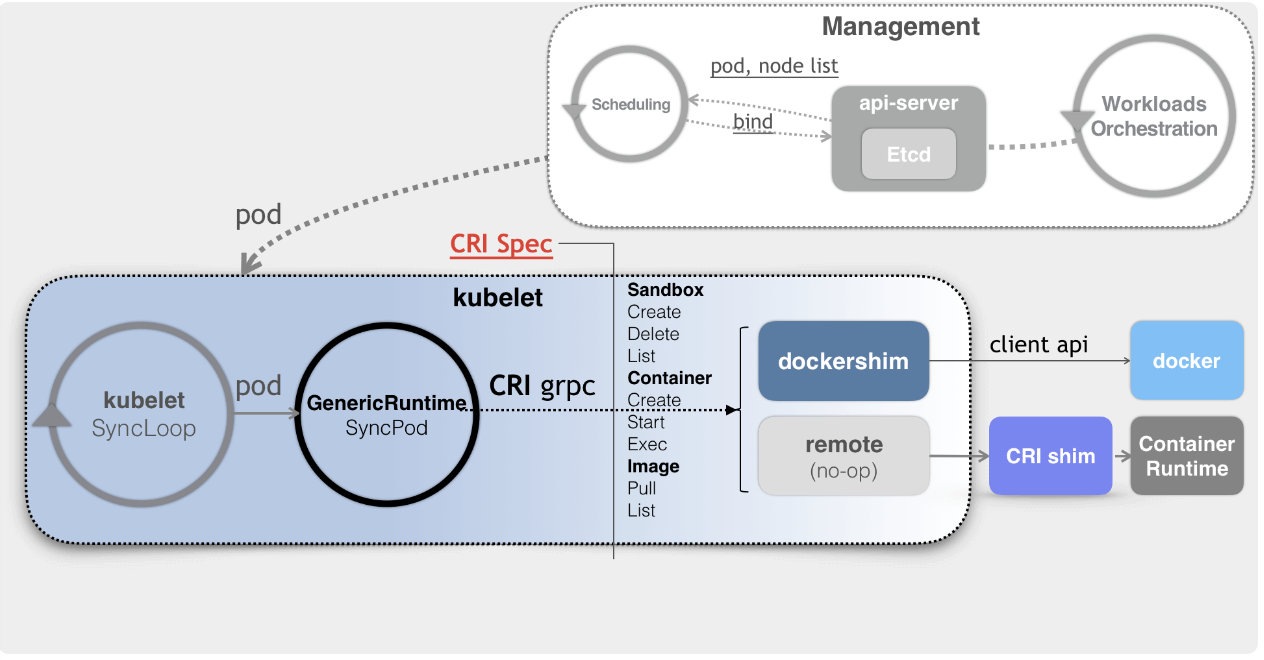
当 Kubernetes 通过编排能力创建了一个 Pod 之后,调度器会为这个 Pod 选择一个具体的节点来运行。这时候,kubelet 当然就会通过前面讲解过的 SyncLoop 来判断需要执行的具体操作,比如创建一个 Pod。那么此时,kubelet 实际上就会调用一个叫作 GenericRuntime 的通用组件来发起创建 Pod 的 CRI 请求
这个 CRI 请求,又该由谁来响应呢?🤔️~
如果使用的容器项目是 Docker 的话,Docker 并不支持 CRI,而 Kubernetes 一直以来所使用的是名为 dockershim 的桥接服务,那么负责响应这个请求的就是 dockershim 组件。它会把 CRI 请求里的内容组装成 Docker API 请求发给 Docker Daemon
Kubernetes 在 1.20 弃用 dockershim
Docker support in the kubelet is now deprecated and will be removed in a future release. The kubelet uses a module called “dockershim” which implements CRI support for Docker and it has seen maintenance issues in the Kubernetes community. We encourage you to evaluate moving to a container runtime that is a full-fledged implementation of CRI (v1alpha1 or v1 compliant) as they become available.
更普遍的场景,就是在每台宿主机上单独安装一个负责响应 CRI 的组件 CRI shim,CRI 机制能够发挥作用的核心,就在于每一种容器项目现在都可以实现一个 CRI shim,自行对 CRI 请求进行处理。这样,Kubernetes 就有了一个统一的容器抽象层,使得下层容器运行时可以自由地对接进入 Kubernetes 当中
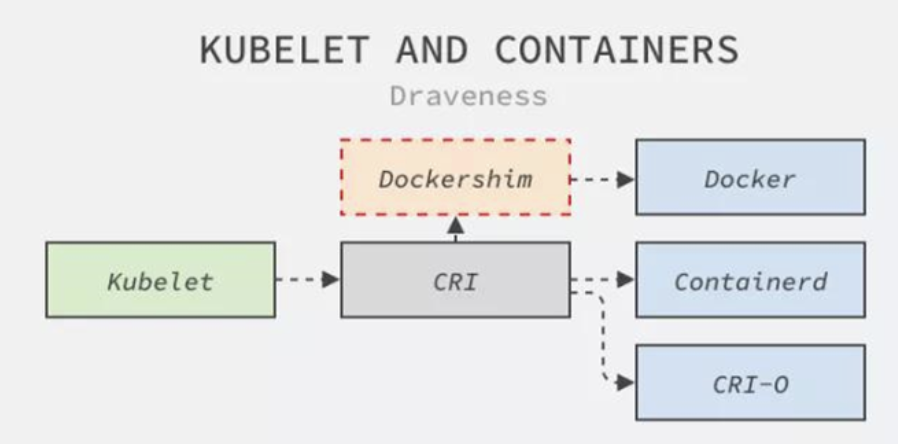
3.2. kube-proxy
service 在逻辑上代表了后端的多个 Pod,外界通过 service 访问 Pod。service 接收到的请求是如何转发到Pod的呢🤔️~
这就是 kube-proxy 要完成的工作。每个 Node 都会运行 kube-proxy 服务,它负责将访问 service 的 TCP/UDP 数据流转发到后端的容器。如果有多个副本,kube-proxy 会实现负载均衡~
3.3. 容器运行时
Pod 是一组容器组成的集合并包含这些容器的管理机制,它并未额外定义进程的边界或其他更多抽象,因此真正负责运行容器的依然是底层的容器运行时。kubelet通过CRI(容器运行时接口)可支持多种类型的OCI容器运行时,例如 docker、containerd、CRI-O、runC、fraki 和 Kata Containers 等
四、核心附件
附件(add-ons) 用于扩展 Kubernetes 的基本功能,根据重要程度将其划分为必要和可选两个类别。
网络插件
网络插件是必要附件,管理员需要从众多解决方案中根据需要及项目特性选择,常用的有 Flannel、Calico、Canal、Cilium和Weave Net等。
CoreDNS
Kubernetes 使用定制的 DNS 应用程序实现名称解析和服务发现功能,它自1.11版本起默认使用CoreDNS一种灵活、可扩展的DNS服务器
之前的版本中用到的是 kube-dns 项目,SkyDNS则是更早一代的解决方案。
Web UI
基于Web的用户接口,用于可视化Kubernetes集群。Dashboard 可用于获取集群中资源对象的详细信息
我用的是
kuboard哦😯~~~容器资源监控系统
监控系统是分布式应用的重要基础设施,Kubernetes 常用的指标监控附件有 Metrics-Server、kube-state-metrics 和 Prometheus 等
集群日志系统
日志系统是构建可观测分布式应用的另一个关键性基础设施,用于向监控系统的历史事件补充更详细的信息,帮助管理员发现和定位问题;Kubernetes常用的集中式日志系统是由 ElasticSearch、Fluentd 和Kibana (称之为EFK) 组合提供的整体解决方案
Ingress Controller
Ingress 资源是Kubernetes将集群外部HTTP/HTTPS流量引入到集群内部专用的资源类型,它仅用于控制流量的规则和配置的集合,其自身并不能进行“流量穿透”,要通过Ingress控制器发挥作用
在这些附件中,CoreDNS、监控系统、日志系统和Ingress控制器基础支撑类服务是可由集群管理的基础设施,而Dashboard则是提高用户效率和体验的可视化工具
五、总结
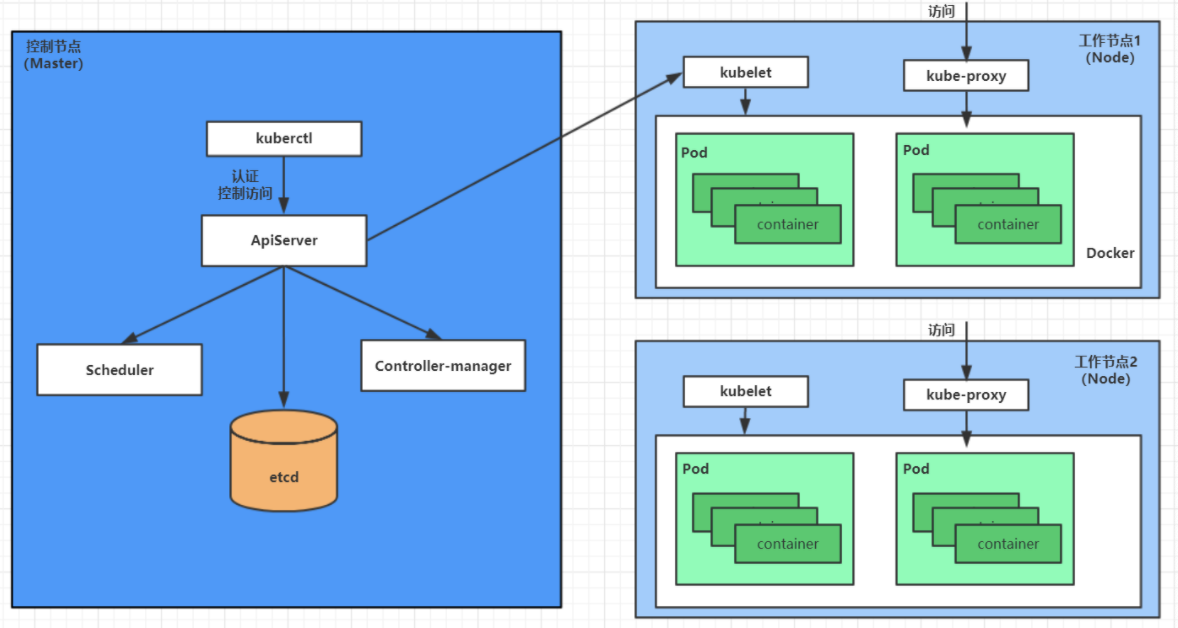
5.1. Pod 创建流程
- 用户通过 kubectl 或其他 api 客户端提交需要创建的 pod 信息给 apiServer
- API Server 开始生成 Pod 对象的信息,并将信息存入 etcd,然后返回确认信息至客户端
- API Server 开始反映 etcd 中的 pod 对象的变化,其它组件使用 watch 机制来跟踪检查 API Server 上的变动
- kube-scheduler 发现有新的 pod 对象要创建,开始为 pod 分配主机并将结果信息更新至 API Server
- node 节点上的 kubelet 发现有 pod 调度过来,尝试调用容器运行时 (比如: docker) 启动容器,并将结果回送至 API Server
- API Server 将接收到的 pod 状态信息存入 etcd 中
5.2. 疑问
为什么 我建的集群 k8s Master 上也有 kubelet 和 kube-proxy 呢?🤔️~
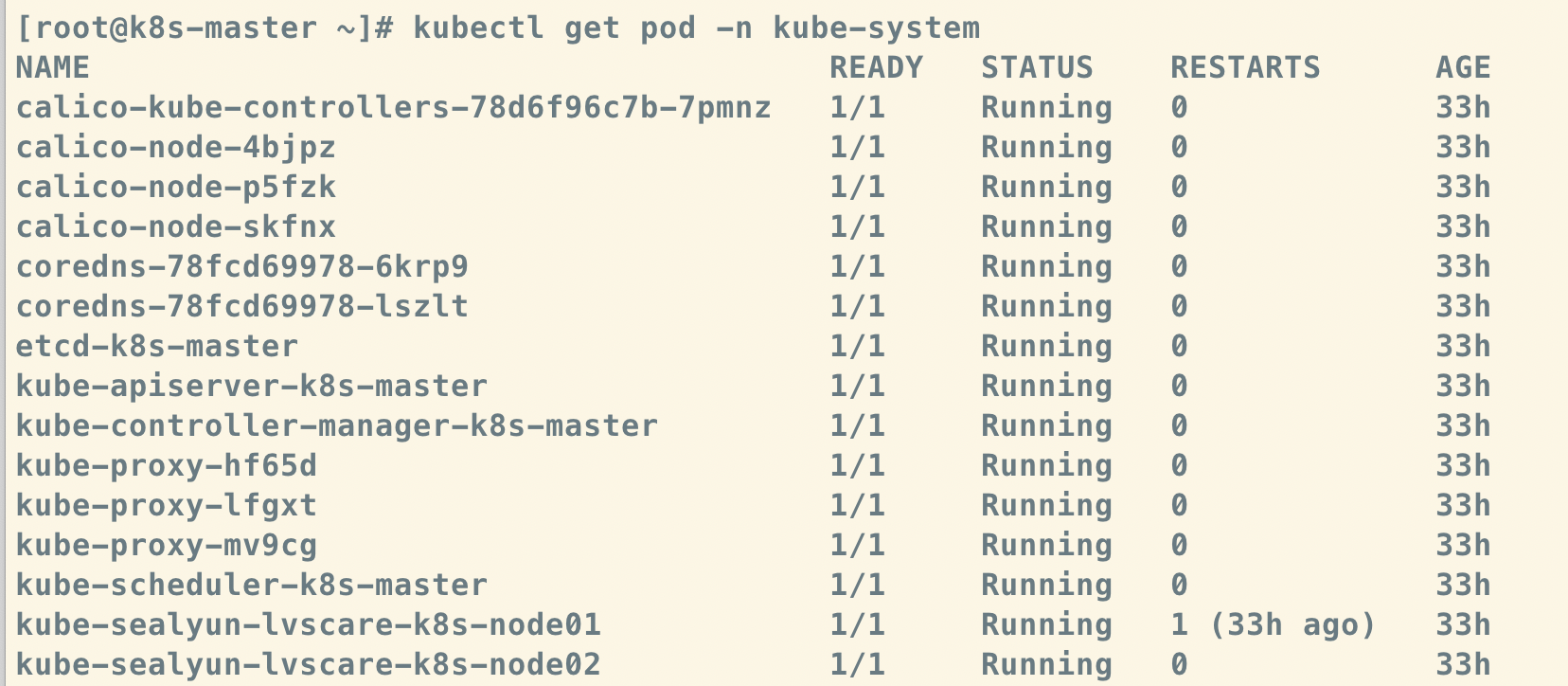
这是因为Master上也可以运行应用,即 Master 同时也是一个Node
为什么 我建的集群 k8s Node 上没有kubelet 呢?🤔️~
Kubernetes 的大部分系统组件都被放到
kube-systemnamespace中, kubelet 是唯一没有以容器形式运行的Kubernetes组件,它通过 Systemd 服务运行
 微信
微信 支付宝
支付宝





