Spark-源码学习-SparkCore-调度机制-任务调度-Task 调度-TaskSetManager
一、概述
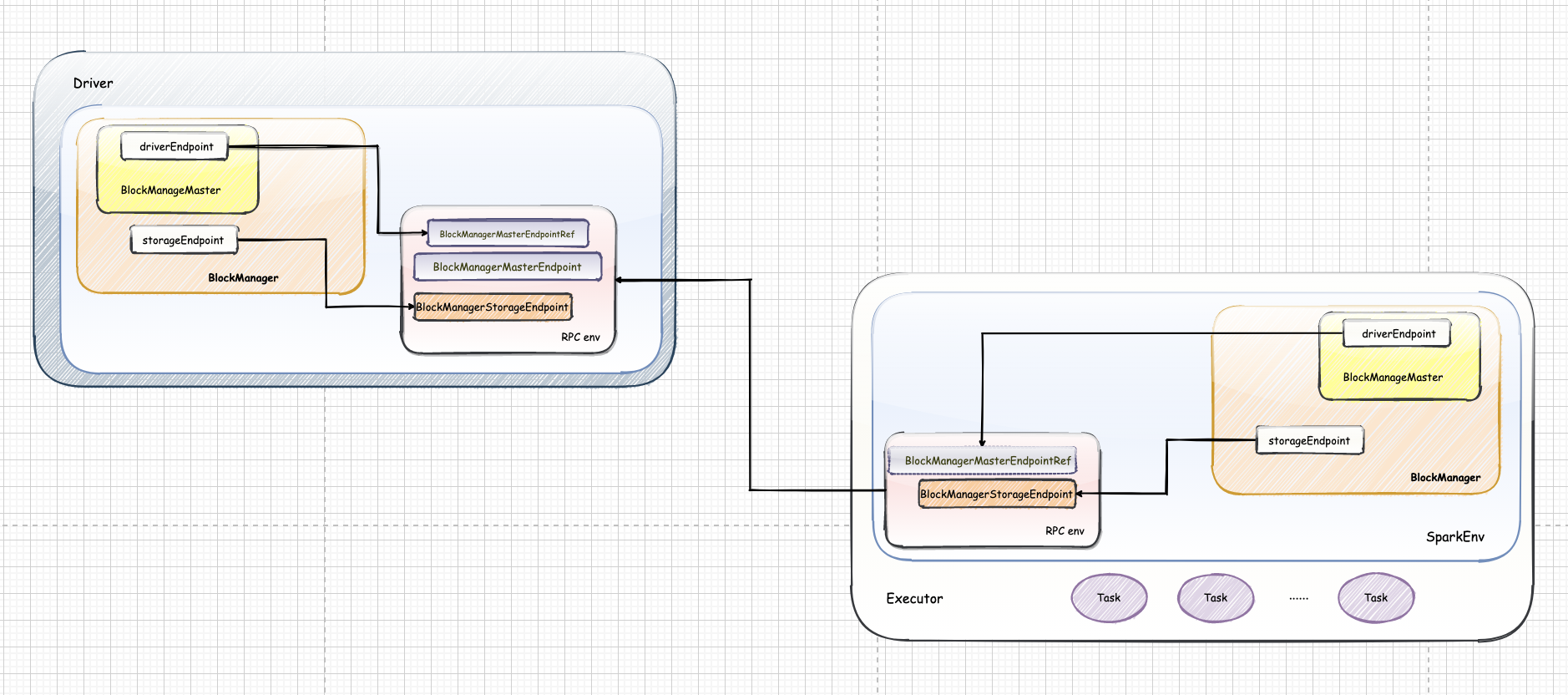
TaskSetManager 实现了 Schedulable 特质,并参与到调度池的调度中。TaskSetManager 对 TaskSet 进行管理,包括任务推断、Task 本地性,并对Task 进行资源分配。TaskSchedulerImpl 依赖于 TaskSetManager。
DAGScheduler 将 Stage 打包到 TaskSet 交给 TaskScheduler, TaskSet 调度池中对 Task 进行调度管理的基本单位, TaskScheduler 会 将 TaskSet 封装为 TaskSetManager, 负责监控管理同一个 Stage 中的 Tasks, TaskScheduler 就是以 TaskSetManager 为单元来调度任务。
TaskSetManager 负责监控管理同一个 Stage 中的 Tasks, TaskScheduler 会先把 DAGScheduler 给过来的 TaskSet 封装成,TaskSetManager 放到任务队列里,然后再按照指定的调度策略在调度队列中选择 TaskSetManager。

https://blog.csdn.net/lidongmeng0213/article/details/109722690
https://weread.qq.com/web/reader/0c832fb05e12e40c8ca6190k7cb321502467cbbc409e62d
二、实现
2.1. 本地化调度
从调度队列中拿到TaskSetManager后,那么接下来的工作就是TaskSetManager按照一定的规则一个个取出task给TaskScheduler,TaskScheduler再交给SchedulerBackend发送到具体的Executor上执行。TaskSetManager封装了一个Stage的所有Task,并负责管理调度这些Task,每个Task都有数据依赖的优先位置,在调度执行时,Spark调度总是会尽量让每个task以最高的本地性级别来启动,当一个task以本地性级别启动,但是该本地性级别对应的所有节点都没有空闲资源而启动失败,此时并不会马上降低本地性级别启动而是在某个时间长度内再次以本地性级别来启动该task,若超过限时时间则降级启动,去尝试下一个本地性级别,依次类推。 可以通过调大每个类别的最大容忍延迟时间,在等待阶段对应的Executor可能就会有相应的资源去执行此task,这就在在一定程度上提升了运行性能。
TaskSetManager 封装了一个 Stage 的所有 task,从调度队列中拿到 TaskSetManager 后,那么接下来的工作就是调度这些 task,
TaskSetManager是基于数据本地性来调度执行任务,取出 task 给TaskScheduler,TaskScheduler 再交给 SchedulerBackend 去发到Executor 上执行
TaskSetManager 根据每个 task 的优先位置,确定 task 的 Locality 级别,Locality 一共有五种,优先级由高到低顺序
| PROCESS_LOCAL | 进程本地化,task 和数据在同一个 Executor 中,性能最好。 |
|---|---|
| NODE_LOCAL | 节点本地化,task 和数据在同一个节点中,但是 task 和数据不在同一个 Executor 中,数据需要在进程间进行传输。 |
| RACK_LOCAL | 机架本地化,task 和数据在同一个机架的两个节点上,数据需要通过网络在节点之间进行传输。 |
| NO_PREF | 数据从哪里访问都一样快,不需要位置优先 |
| ANY | task 和数据不在一个机架中,性能最差。 |
在调度执行时,总是会尽量让每个 task 以最高的本地性级别来启动,当一个 task 以 X 本地性级别启动,但是该本地性级别对应的所有节点都没有空闲资源而启动失败,此时并不会马上降低本地性级别启动, 而是在最大容忍延迟时间长度内再次以 X 本地性级别来启动该 task,若超过限时时间则降级启动,去尝试下一个本地性级别,依次类推。
可以通过调大每个类别的最大容忍延迟时间,在等待阶段对应的 Executor 可能 就会有相应的资源去执行此 task,这就在在一定程度上提到了运行性能。
2.2. 失败重试与黑名单机制
TaskSetManager 除了调度 Task 机制外,还需要监控 Task 的执行状态。Task 被调度到 Executor 启动执行后,Executor 会将执行状态上报给 SchedulerBackend, SchedulerBackend 则通知该 Task 对应的 TaskSetManager,对于失败的 Task,TaskSetManager 会记录失败次数,如果失败次数还没有超过最大重试次数,则把该 Task 放回待调度的 Task 池子中,否则整个 Application 失败。
在记录 Task 失败次数过程中,会记录其上一次失败所在的 ExecutorId 和 Host,下次调度该 Task 时,会使用黑名单机制,避免再次被调度到上一次失败的节点上,起到一定的容错作用。
黑名单记录 Task 上一次失败所在的 ExecutorId 和 Host,以及其对应的 “拉黑时间”., “拉黑时间”是指这段时间内不要再往这个节点上调度这个 Task 了。
 微信
微信 支付宝
支付宝