












Spark-源码学习-架构设计-DataSource 体系-保存数据
一、概述1234567891011df.write.format("hudi") .option(HoodieWriteConfig.TBL_NAME.key, tableName) .option(TABLE_TYPE.key, COW_TABLE_TYPE_OPT_VAL) .option(RECORDKEY_FIELD.key, "id") .option(PRECOMBINE_FIELD.key, "ts") .option(PARTITIONPATH_FIELD.key, "") .option(KEYGENERATOR_CLASS_NAME.key, classOf[NonpartitionedKeyGenerator].getName) .option(HoodieWriteConfig.INSERT_PARALLELISM_VALUE.key, "1") .option(HoodieWriteConfig.UPSERT_PARALLELISM_VALU ...
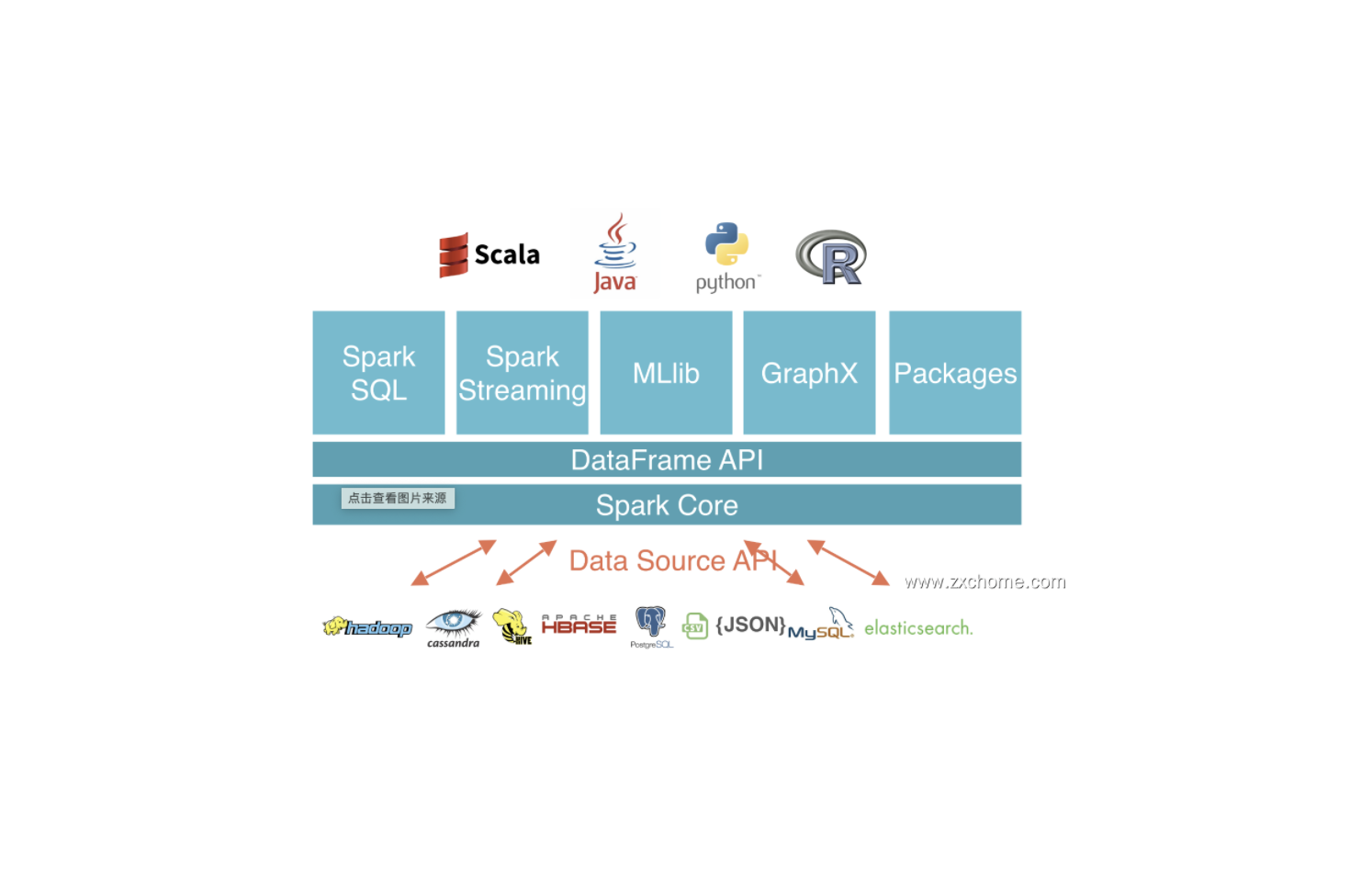
Spark-源码学习-SparkSQL-架构设计-DataSource 体系
一、概述Spark Datasource API 是一套连接外部数据源和 Spark 引擎的框架,提供一种快速读取外界数据的能力,它可以方便地把不同的数据格式通过 DataSource API 注册成 Spark 的表,然后通过 Spark SQL 直接读取。它可以充分利用 Spark 分布式的优点进行并发读取,通过 SparkSQL Catayst 优化引擎,能够加快任务的执行。
Spark Datasource API 同时提供了一套优化机制,如将列剪枝和过滤操作下推至数据源侧,减少数据读取数量,提高数据处理效率。
二、设计DataSource API 是 Apache Spark 中非常流行的功能。许多开发人员广泛使用它来将第三方应用程序连接到 Apache Spark。Spark DataSource API 目前有 V1 和 V2 两个版本,V1 在 2.3.x 之前就已经存在了,V2 API 在 Spark 2.3.0 中引入,并在 2.4.0 中进行了修改。在 3.0.0 中,Spark 对 V2 API 进行了重大更改,但是为了向后兼容,V1 被保留不变。
2. ...
Spark-源码学习-架构设计-DataSource-V2-2.x
一、概述DataSource API 是 Apache Spark 中非常流行的功能。许多开发人员广泛使用它来将第三方应用程序连接到 Apache Spark。Spark DataSource API 目前有 V1 和 V2 两个版本,V1 在 2.3.x 之前就已经存在了,V2 API 在 Spark 2.3.0 中引入,并在 2.4.0 中进行了修改。在 3.0.0 中,Spark 对 V2 API 进行了重大更改,但是为了向后兼容,V1 被保留不变。
二、设计
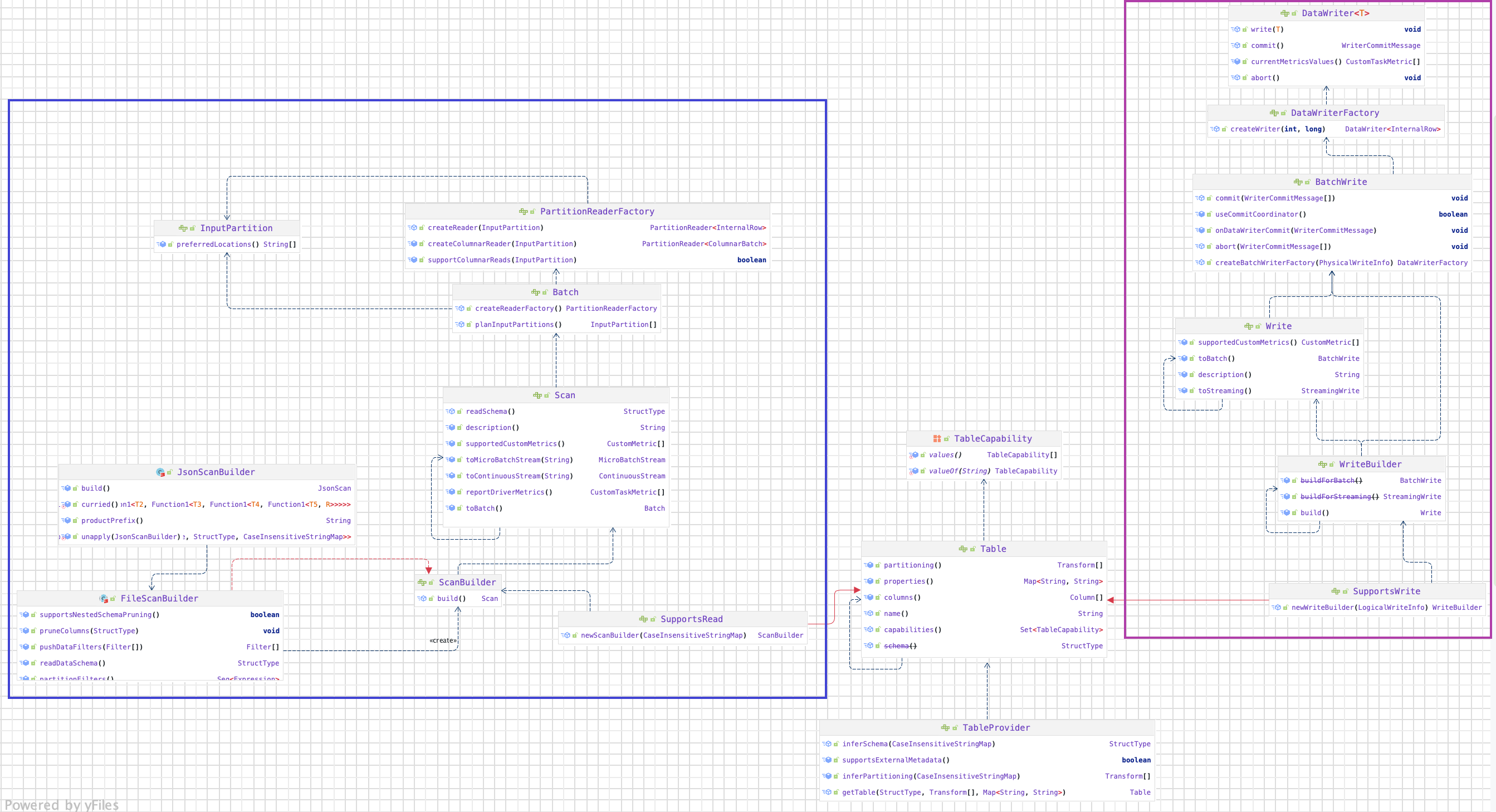
Spark-源码学习-架构设计-DataSource-V2-3.x
一、概述DataSource API 是 Apache Spark 中非常流行的功能。许多开发人员广泛使用它来将第三方应用程序连接到 Apache Spark。Spark DataSource API 目前有 V1 和 V2 两个版本,V1 在 2.3.x 之前就已经存在了,V2 API 在 Spark 2.3.0 中引入,并在 2.4.0 中进行了修改。在 3.0.0 中,Spark 对 V2 API 进行了重大更改,但是为了向后兼容,V1 被保留不变。
二、设计
2.1. TableProviderTableProvider 是一个用于解析表和获取相应元数据的接口。实现此接口将允许用户在 SQL 中使用 Spark 读取自定义数据源。在 Spark 2.4.X 中,数据源 API 中的主要接口是DatasourceV2,所有自定义数据源都需要实现它或其中一个专业化接口,如 ReadSupport 或 WriteSupport。在 3.0.X 中,此接口被删除。引入了一个新的 TableProvider 接口。它是所有不需要支持 DDL 的自定义数据源的基本接口。
2.2. ...
Flink-源码学习-FlinkCore-TaskManager-任务运行服务
一、概述二、TaskManagerServices 架构TaskManagerServices 中包含多种多样的内部组件,以实现不同的功能。
2.1. 公共基础服务
安全服务 SecurityManager
通信服务 RpcEnv
序列化服务 SerializerManager
度量系统
Flink 作为优秀的开源系统,在监控方面也有自己的一整套体系,Flink 基于 Metrics 实现了自己的度量系统。
2.2. 运行时服务
存储服务
Flink 提供的存储服务包括内存管理服务和文件管理服务,TaskManager 启动时也会初始化 I/O 管理组件 IOManager 负责将数据溢出到磁盘并将其读取回来以及内存管理组件 MemoryManager 负责协调内存使用。
引用本站文章
Flink 源码学习-存储服务-架构设计
Joker
...
Flink-源码学习-FlinkCore-公共基础服务
Fink 集群启动时组件会执行 initializeServices() 方法初始化一些基础服务,比如说 JobManager 启动时会初始化一些 RPC 通信服务、高可用服务以及监控服务等。
RPC 通信服务
Flink 集群内部通信框架的最底层依赖于 Akka,定义了不同类型的消息,并且设计了通用的 RPC 通信组件,Flink 的所有提供 RPC 请求的集群组件(如 JobMaster、 TaskManager、 ResourceManager、 Dispatcher 等)都使用了这些 RPC 通信基础组件來提供对外的 RPC 接口。JobManager RPC 服务如图所示:
引用本站文章
Flink-源码学习-FlinkCore-通信服务-公共基础服务-Flink RPC 设计
Joker
高可用服务
向集群组件提供高可用支持,集群 ...
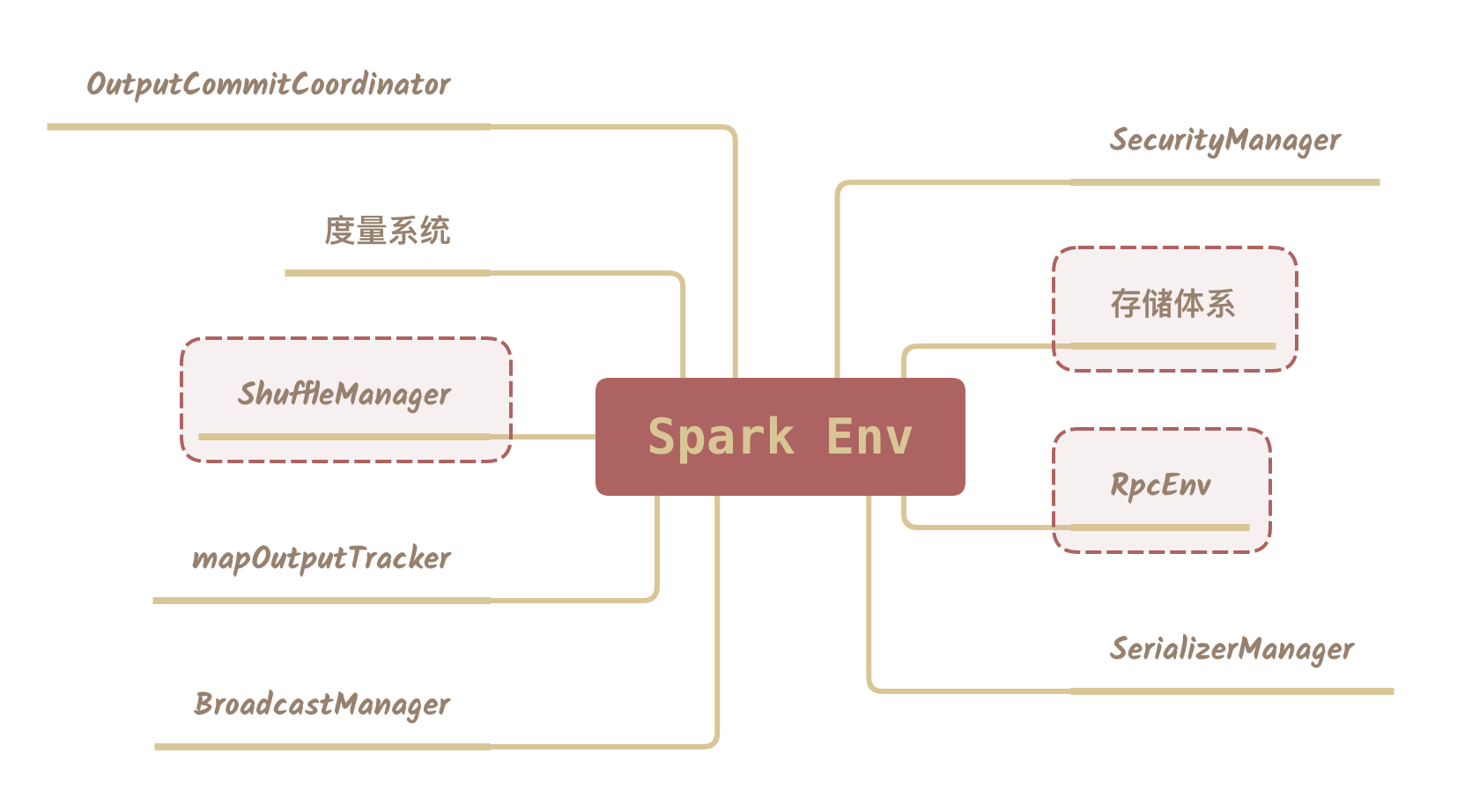
Spark-源码学习-SparkSession-SparkContext-SparkEnv
正如曹操在《建学令》中所言,优秀人才的培育离不开国家政策这个大环境。在人类生活中,总是会依赖于外部的各种环境。一个人学习成绩的好坏,很大的因素取决于他所处的教育环境;一个人健康与否,依赖于他所处的医疗卫生环境;一个人的沟通能力,与自己的家庭环境有很重要的关系。如果某一天你发现自己联系不到亲人、朋友,甚至周围的环境都是陌生的,那么你立刻会处于崩溃的边缘。
一、概述就像学习一门编程语言一样, 无论是 Java 程序还是 Scala 程序,都需要运行在其所依托的环境下。Spark 对任务的计算都依托于 Executor 的能力,所有的 Executor 都有自己的 Spark 执行环境 SparkEnv。Executor 有了 SparkEnv, 就可以将数据存储在 SparkEnv 提供的存储体系中; 就能利用计算引擎对计算任务进行处理,就可以在节点间进行通信等…
二、SparkEnv 架构SparkEnv 还提供了多种多样的内部组件,实现不同的功能。
2.1. 公共基础服务组件
安全服务 SecurityManager
SecurityManager 主要对账号、权限及身份认证进 ...
Spark 理论笔记系列
正在总结中,等我😭~~~

Spark-源码学习-DPP 设计
一、概述1.1. 分区裁剪分区剪裁是谓词下推的一种特例,它指的是在分区表中下推谓词,谓词是分区目录。分区表分不同的目录存储数,如果过滤谓词中包含分区键,Spark SQL 对分区表做扫描的时候,是完全可以跳过不满足谓词条件的分区目录,这就是分区剪裁。
1.2. 动态分区裁剪 DPP(Dynamic Partition Pruning)1.2.1. 什么是 DPP?动态分区裁剪就是基于运行时推断出来的信息来进一步进行分区裁剪。从而减少事实表中数据的扫描量降低 I/O开销,提升执行性能。DPP(Dynamic Partition Pruning,动态分区剪裁)指的是在大表 Join 小表的场景中,可以充分利用过滤之后的小表,在运行时动态的来大幅削减大表的数据扫描量,从整体上提升关联计算的执行性能。
在数仓情景下 Spark SQL 利用维度表提供的过滤信息,减少事实表中数据的扫描量、提升执行性能。
https://blog.csdn.net/Shyllin/article/details/129202728
https://zhuanlan.zhihu.com/p/5487573 ...
Spark-源码学习-SparkCore-通信服务-架构设计-传输层-Handler-MessageDecoder
一、概述Spark 针对 Netty 封装了 MessageDecoder 负责消息解码,对从管道中读取的 ByteBuf 进行解析,防止丢包和解析错误。
https://www.cnblogs.com/itboys/p/9208417.html
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.















