











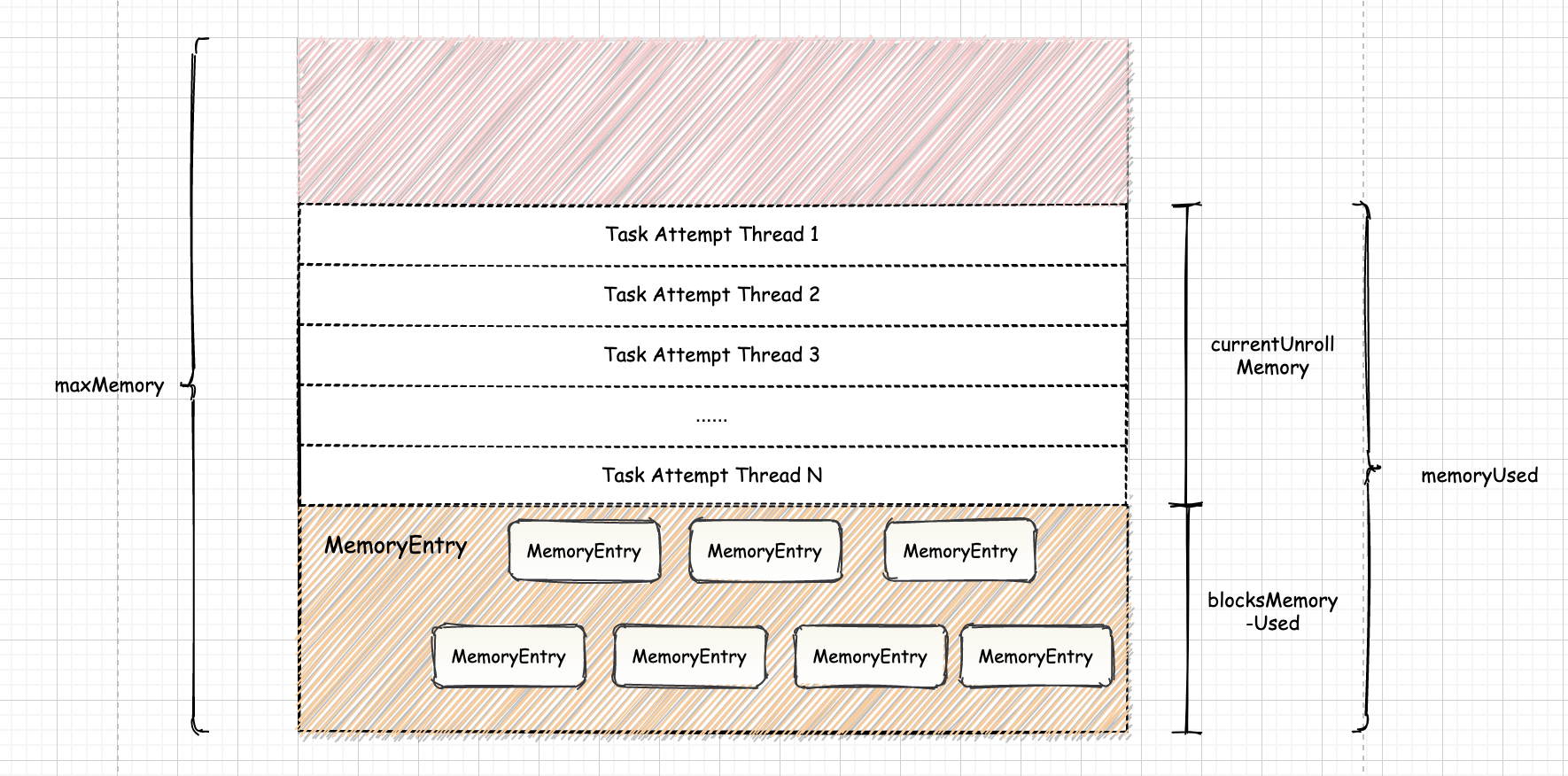
Spark-源码学习-SparkCore-存储服务-内存组件-Memstore
一、概述MemoryStore 负责 Spark 内存存储,管理以 MemoryEntry 为父接口的内存对象,实现了一个简单的基于 Block 的内存数据库,用来管理需要写入到内存中的 Block 数据。可以按序列化或非序列化的形式存放块数据,存放这两种块数据的数据结构是不同的,但都必须实现 MemoryEntry 接口~
二、内存结构2.1. 已使用内存已经使用的内存,内存里存放 entries 中,该 entries 由不同数据块生成的 MemoryEntry 构成,MemoryStore 通过以 MemoryEntry 对象为元素的 LinkedHashMap 来管理 MemoryEntry 数据。LinkedHashMap 是一个有序的 HashMap,这样可以按插入顺序来对元素进行管理,此时各个节点构成了一个双向链表。
1private val entries = new LinkedHashMap[BlockId, MemoryEntry[_]](32, 0.75f, true)
MemoryStore 不仅使用了 LinkedHashMap 的基本特性,还使用了其 ...

Spark-理论笔记-内存存储设计
一、理论作为一个JVM 进程,Spark 的内存管理建立在JVM 的内存管理之上,Spark 对JVM的堆内内存基础上进行了更为详细的分配,以充分利用内存。同时,Spark 引入了堆外内存(Off-heap),可以直接在工作节点的系统内存中开辟空间,进一步 优化了内存的使用。
1.1. 内存模式1.1.1. 堆内内存(On-heap)堆内内存的大小,由 Spark 应用程序启动时的 -executor-memory 或 spark.executor.memory 参数配置。主要包括几个部分:
存储内存(Storage)Executor 内运行的并发任务共享 JVM 堆内内存,这些任务在存储 Shuffle 中间文件、缓存RDD 数据和 Broadcast 数据时占用的内存被规划为存储内存
执行内存任务在执行 Shuffle 时古用的内存被规划为执行内存
reverse默认都是 $300$ MB,硬编码到代码中。
用户内存Spark 程序中产生的临时对象实例、Spark 内部的对象实例或者是用户自己维护的一些数据结构也需要给予它一部份的存储空间,可以认为是程序运行时用户可以主导 ...
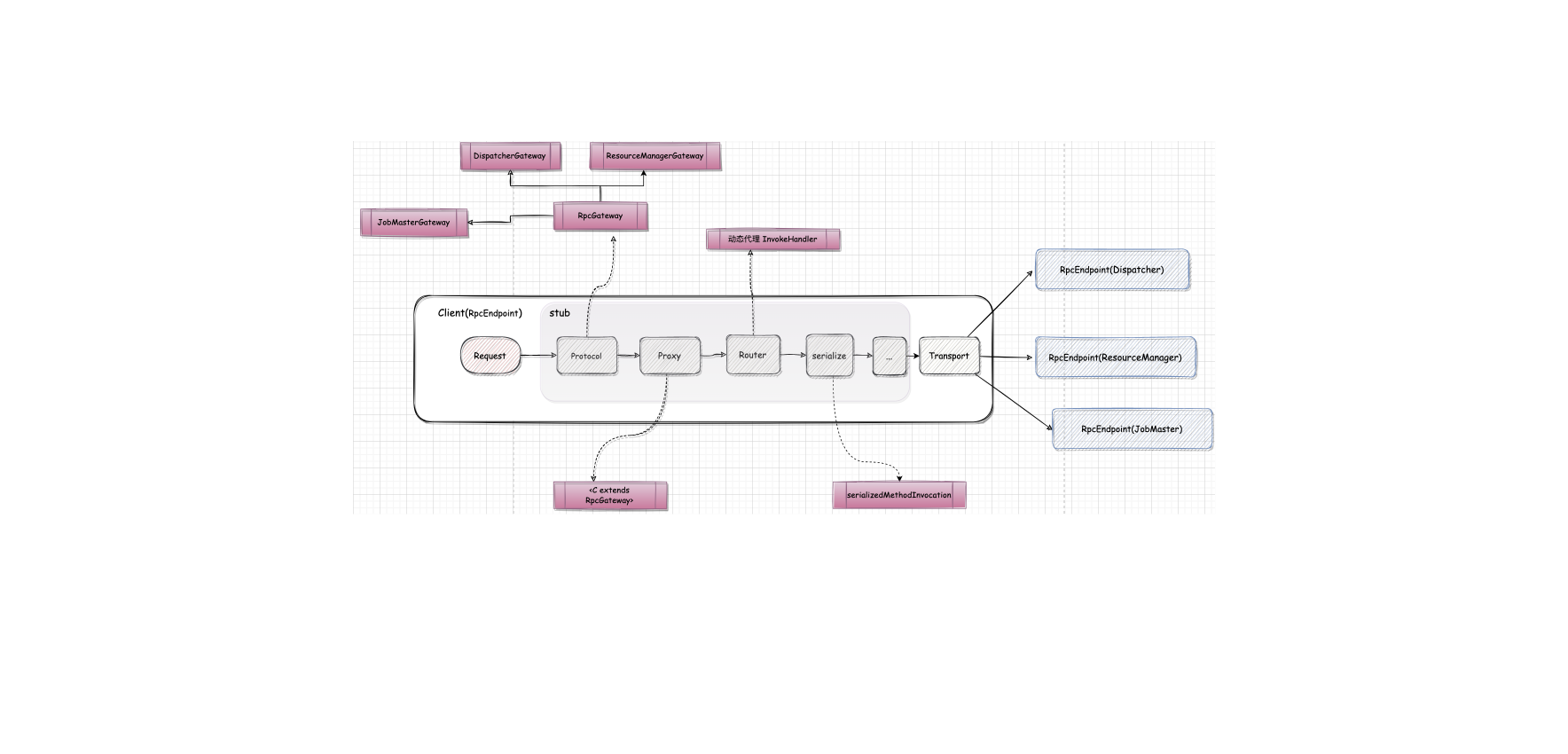
Flink-源码学习-通信服务-Flink RPC 设计-客户端
一、概述
二、请求程序三、Stub 程序3.1. 协议层Flink rpc message 包定义了使用的协议类。
在 AkkaRpcActor 中主要创建了 RemoteHandshakeMessage(主要用于进行正式RPC通信之前的网络连接检测,保障 RPC 通信正常)、ControlMessages(用于控制 Akka系统,例如启动和停业Akka Actor等控制消息)等消息对应的处理器,此外还有集群运行时中 RPC 组件通信使用的 Message 类型。
3.2. 代理层3.2.1. RpcGateway 实现RpcGateway 又叫作远程调用网关,是对外提供可调用的接口,所有实现 RPC 的组件都实现了此接口。
JobMasterGateway 接口是 JobMaster 提供的对外服务接口
TaskExecutorGateway 是 TaskManager(其实现类是TaskExecutor)提供的对外服务接口
ResourceManagerGateway 是 ResourceManager 资源管理器提供的对外服务接口
DispatcherGateway ...
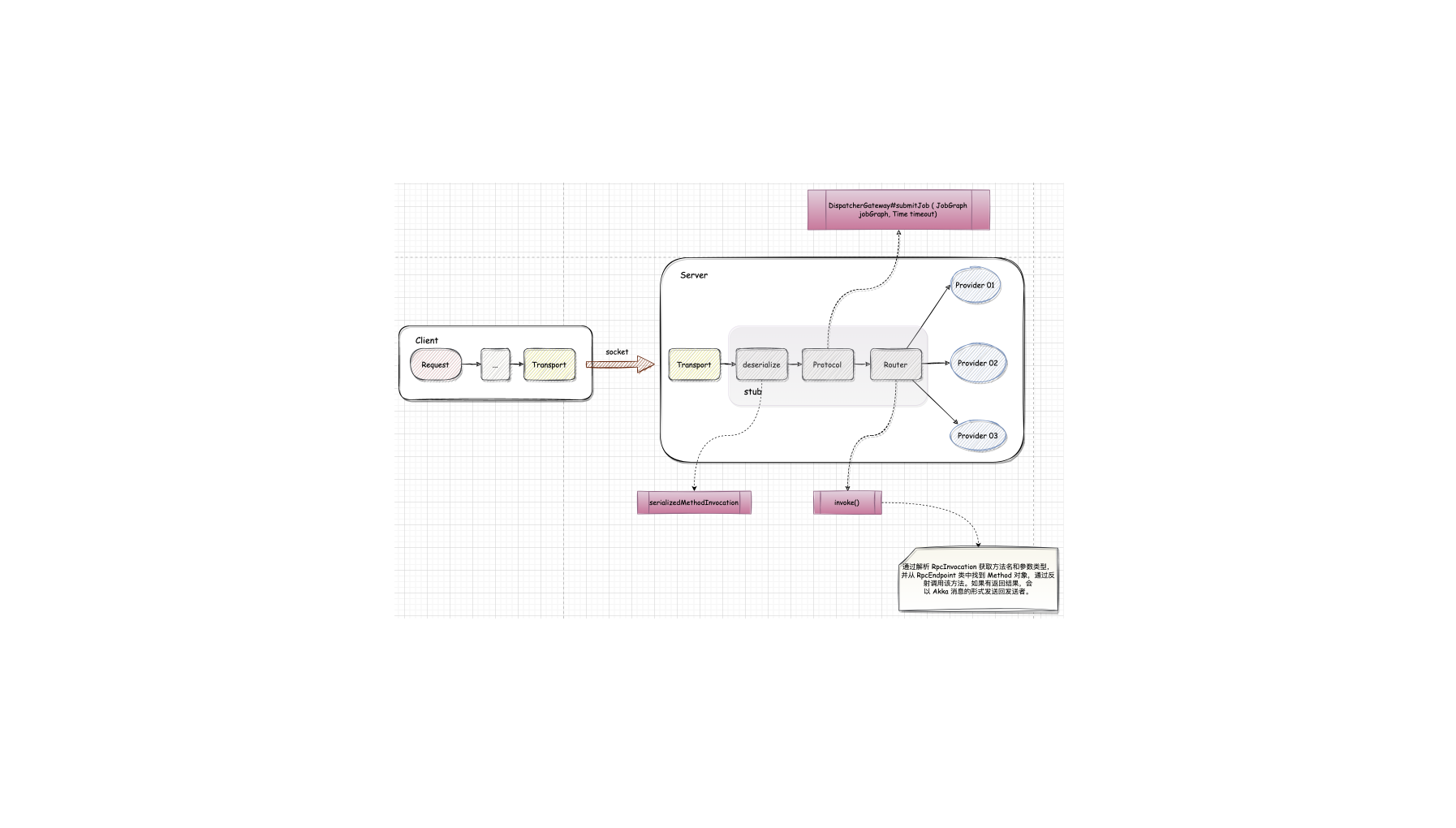
Flink-源码学习-通信服务-Flink RPC 设计-服务端
一、概述
二、传输层 ServerAkka 中 创建 actor 需要继承 AbstractActor 类并重写它的初始行为方法 createReceive(),actor 接收消息后会触发 createReceive() 方法被调用,通过 receiveBuilder() 来接收消息以及它的类型,从而判断该如何处理消息。
123456public Receive createReceive() { return ReceiveBuilder.create() .match(RemoteHandshakeMessage.class, this::handleHandshakeMessage) .match(ControlMessages.class, this::handleControlMessage) .matchAny(this::handleMessage).build();}
AkkaRpcActor 接收到的消息总共有3种。
握手消息
在客户端构造时会通过 ActorSelection 发送过来。收到消息后会检查接口、 ...
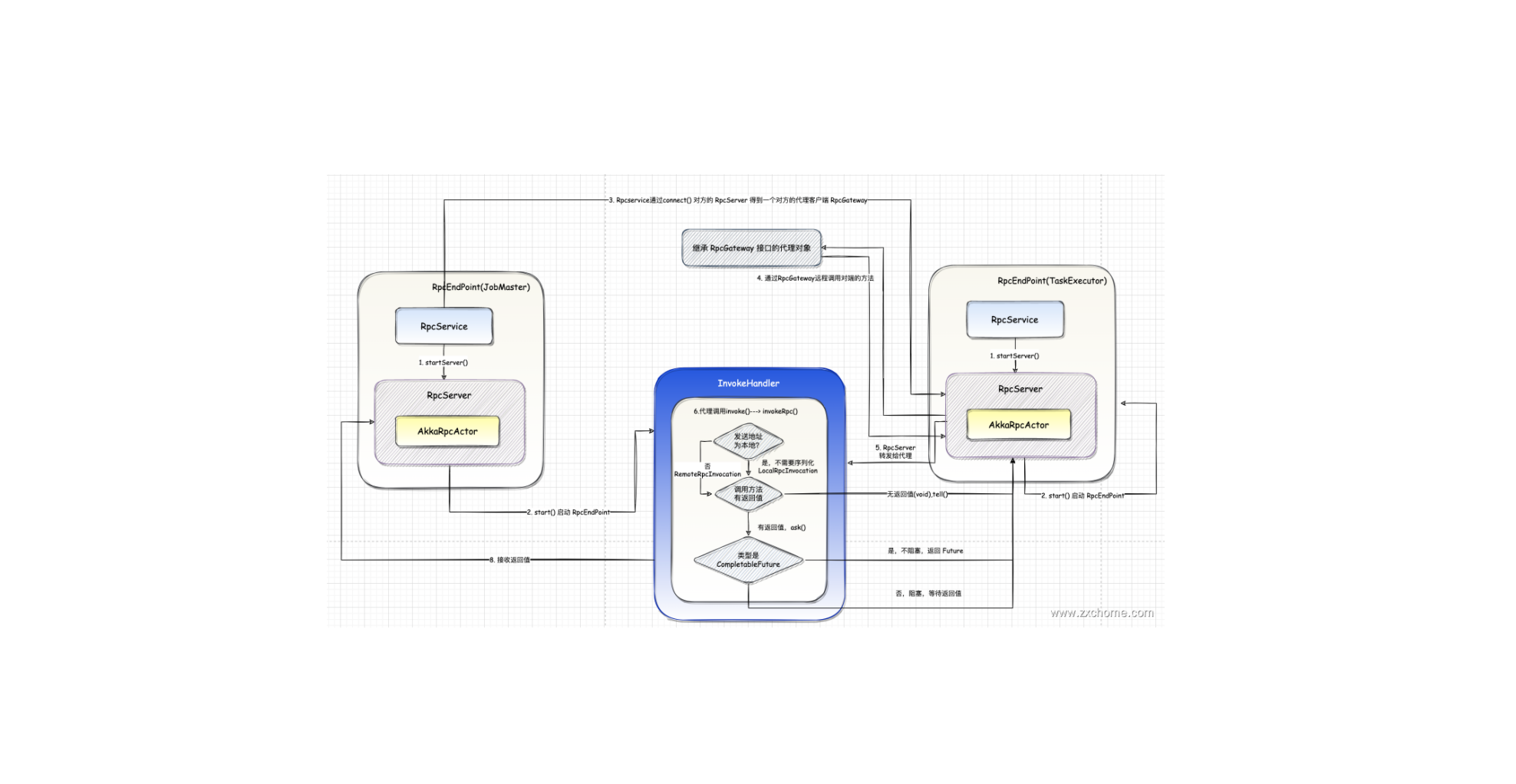
Flink-源码学习-通信服务-Flink RPC 设计-通信环境 RPCService 设计
一、概述RpcService 是 RpcEndpoint 的运行时环境,是 Akka 中 ActorSystem 的封装。Flink 中 RpcService 也有多套,
JobManager 和 TaskManager 进程中都有两套 RpcService。
二、结构设计2.1. 属性AkkaRpcService 是 RpcService 的唯一实现类。它除了持有 AkkaSystem (akkaSystem) 的引用外,还维护所有注册了的 RpcEndpoint的引用,为每个 RpcEndpoint 分配一个 ActerRef 并保存他们的对应关系 (actors)。
2.2. 方法RpcService 主要包含如下两个重要方法:
2.2.1. startServer()startServer() 方法用于启动 RpcEndpoint 中的 RpcServer。启动完成后,RpcEndpoint 中的 RpcServer 就能够对外提供服务了。
2.2.2. connect()connect()方法用于连接远端 RpcEndpoint 并返回给调用方实现了 Rpc ...
Flink-源码学习-通信服务-Flink RPC 设计
一、概述Flink 内部组件之间的通信是用 Akka,比如 JobManager 和 TaskManager 之间的通信。而 Operator 之间的数据传输则利用 Netty 为不同的应用层通信协议 (RPC, FTP, HTTP 等) 提供支持。
1.1. Akka 概述Akka 是一套开源库,用于设计跨处理器和跨网络的可扩展弹性系统,借助 Akka 可以专注于满足业务需求,而不是编写底层代码来提供可靠的行为、容错和高性能。
引用本站文章
Akka 概述
Joker
二、Flink RPC 架构Flink 集群内部通信框架的最底层依赖于 Akka,定义了不同类型的消息,并且设计了通用的 RPC 通信组件,Flink 的所有提供 RPC 请求的集群组件(如 JobMaster、 TaskManager、 ResourceManager、 Di ...
Flink-源码学习-任务提交-架构设计
一、概述用户通过 DataStream API 构建 Flink 应用程序之后,下一步就是将构建好的 jar 包提交到集群中运行,整个过程涉及客户端和集群运行时之间的交互。Flink 的作业提交方式主要分为两种类型:
直接运行在本地 JVM 的伪分布式模式,即通过在JVM 进程内构建 Mini 版的分布式集群运行环境,直接将作业代码提交到 MiniCluster 中运行
将作业通过独立的客户端提交到分布式集群运行时运行。
主要包含 CLI 命令行、Scala Shell客户端、WebRestful API、 Python API 等方式。基于独立客户端实现的不同提交方式底层都是在 flink-client 模块之上进行封装。
二、基于 CLI 命令行基于 CLI 命令行方式提交作业的整体流程:
1${FLINK_HOME}/bin/flink run application.jar
2.1. 流程概述
用户编写和生成 Application.jar 应用程序。
执行 bin/flink run 命令,启动和初始化 CLIFrontend 客户端的 ma ...
Flink-源码学习-数据传输服务-架构设计
正在总结中,等我😭~~~
Flink-源码学习-通信服务-Flink RPC 设计-客户端
一、概述
二、请求程序三、Stub 程序3.1. 协议层Flink rpc message 包定义了使用的协议类。
在 AkkaRpcActor 中主要创建了 RemoteHandshakeMessage(主要用于进行正式RPC通信之前的网络连接检测,保障 RPC 通信正常)、ControlMessages(用于控制 Akka系统,例如启动和停业Akka Actor等控制消息)等消息对应的处理器,此外还有集群运行时中 RPC 组件通信使用的 Message 类型。
3.2. 代理层3.2.1. RpcGateway 实现RpcGateway 又叫作远程调用网关,是对外提供可调用的接口,所有实现 RPC 的组件都实现了此接口。
JobMasterGateway 接口是 JobMaster 提供的对外服务接口
TaskExecutorGateway 是 TaskManager(其实现类是TaskExecutor)提供的对外服务接口
ResourceManagerGateway 是 ResourceManager 资源管理器提供的对外服务接口
DispatcherGateway ...
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.















