












Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Analyzer 模块
一、概述Parser 模块生成的 Unresolved LogicalPlan 仅仅是一种数据结构,不包含任何数据信息。Analyzer 模块使用事先定义好的规则(Rule)以及 Catalog 等信息对未解析的逻辑计划 Unresolved Logical Plan 进行补充和替换 logicalPlan 中的各个节点,让语法树包含元数据信息。
二、实现Analyzer 的父类是 RuleExecutor,所以,调用 Analyzer 的 $apply()$ 方法时,实际上会调用 RuleExecutor 的 $apply()$ 方法中,并传入一个 Unresolved LogicalPlan。
2.1. RuleExecutorAnalyzer 模块中 RuleExecutor 为 Analyzer,Analyzer 调用 $executeAndCheck$ 方法执行模块规则批次~
123456789101112131415def executeAndCheck(plan: LogicalPlan, tracker: QueryPlanningTracker): Logical ...
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-QueryExecution
一、概述从 SQL 语句的解析一直到提交之前,上述整个转换过程都在 Spark 集群的 Driver 端进行,不涉及分布式环境。SparkSession 类的 sql 方法调用 SessionState 中的各种对象,包括上述不同阶段对应的 SparkSqlParser 类、Analyzer 类、Optimizer 类和 SparkPlanner 类等,最后封装成一个 QueryExecution 对象。因此,在进行 Spark SQL 开发时,可以很方便地将每一步生成的计划单独剥离出来分析。
二、实现2.1. executedPlan经过 Analyzer 的处理,Unresolved LogicalPlan 解析为 Analyzed LogicalPlan。Analyzed LogicalPlan 中自底向上节$QueryExecution.executedPlan$~,
123456lazy val executedPlan: SparkPlan = { assertOptimized() // 逻辑优化 executePhase(QueryPlanningTrac ...
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-数据结构-InternalRow
一、概述数据处理首先需要考虑如何表示数据。对于关系表来讲,通常操作的数据都是以 “行” 为单位的。在 SparkSQL 内部实现中, InternalRow 就是用来表示一行行数据的类。此外,InternalRow 中的每一列都 是 Catalyst 内部定义的数据类型。
二、结构从类的定义来看,InternalRow 作为一个抽象类,包含 $numFields()$ 和 $update$ 方法,以及各列数据对应的 $get$ 与 $set$ 方法,但具体的实现逻辑体现在不同的子类中。
需要注意的是, InternalRow 中都是根据下标来访问和操作列元素的。
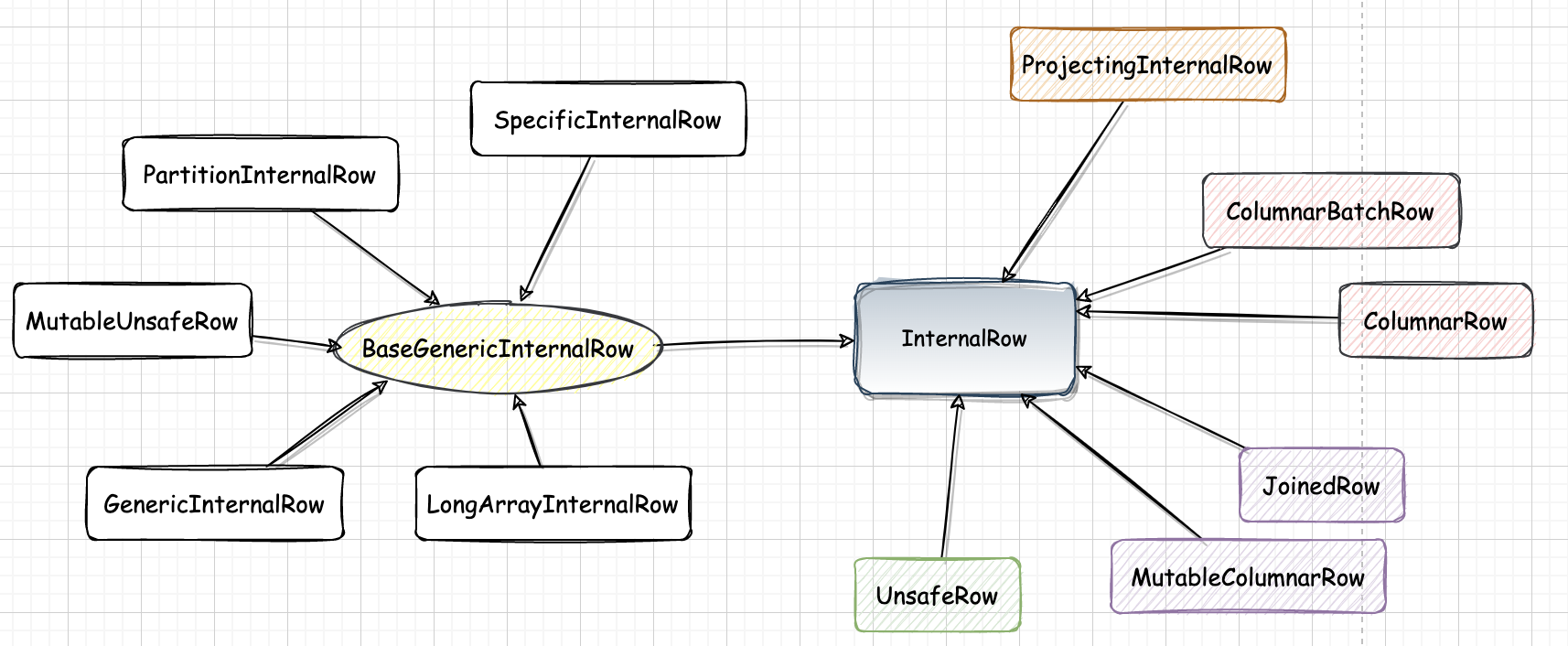
三、InternalRow 继承体系
3.1. BaseGenericInternalRow同样是一个抽象类,实现了 InternalRow 中定义的所有 get 类型方法,这些方法的实现都通过调用类中定义的 genericGet 虚函数进行
3.1.1. GenericInternalRow使用数组作为底层存储的 InternalRow 实现。
1def this(size: Int) = th ...
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-数据结构-TreeNode-Expression
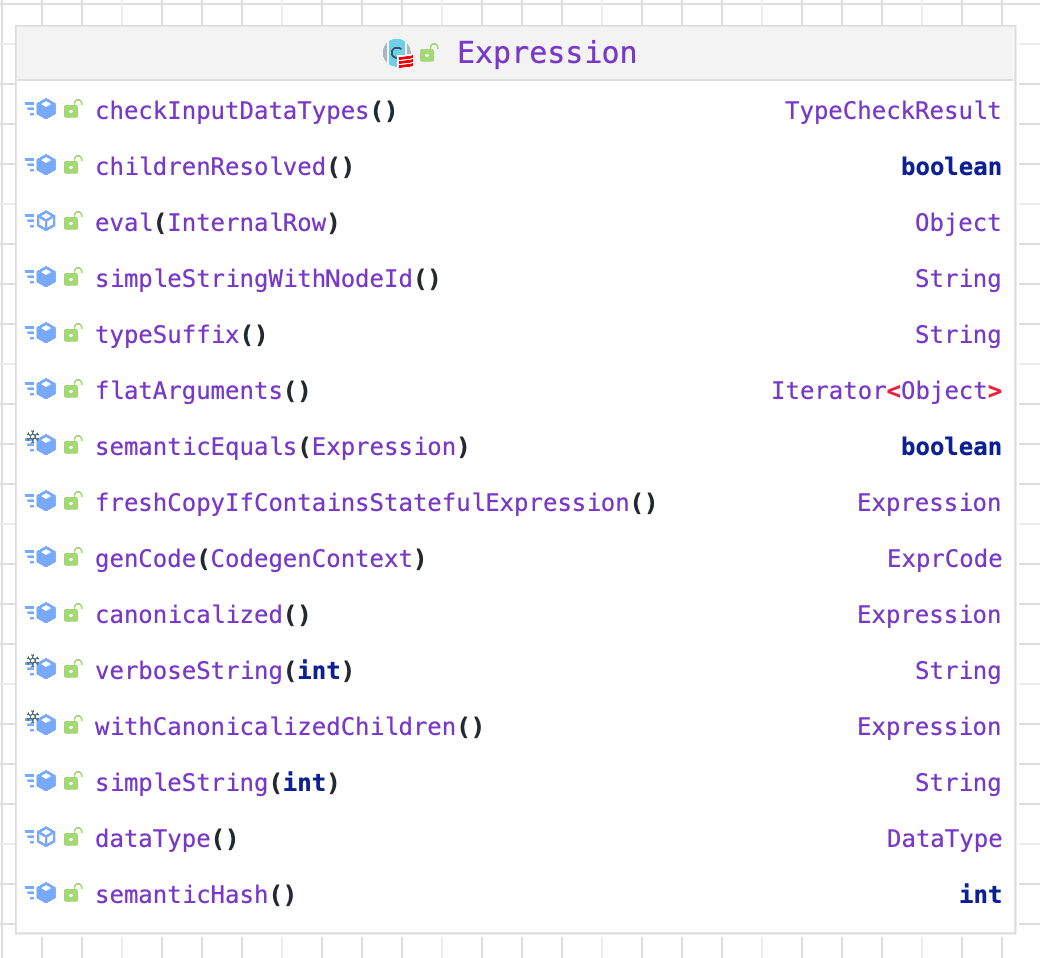
一、概述Expression 是 Catalyst 中的表达式体系。
二、实现在 Expression 类中,主要定义了包括基本属性、核心操作、输入输出、字符串表示和等价性判断
核心操作 $eval$ 函数实现了表达式对应的处理逻辑,也是其他模块调用该表达式的主要接口,而 $genCode$ 和 $doGenCode$ 用于生成表达式对应的 Java 代码。字符串表示用于查看该 Expression 的具体内容,如表达式名和输入参数等。
2.1. 属性2.1.1. deterministic标记表达式是否为确定性的,即每次执行 $eval$ 函数的输出是否都相同。如果在固定输入值的情况下返回值相同,该标记为true;如果在固定输入值的情况下返回值是不确定的,则说明该 expression 是不确定的,deterministic 参数应该为 false。
1lazy val deterministic: Boolean = children.forall(_.deterministic)
2.1.2. _references表示该 Expression 中会涉及的属性值 ...
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-数据结构-TreeNode-QueryPlan-LogicalPlan
一、概述Spark SQL 逻辑计划在实现层面被定义为 LogicalPlan 类。LogicalPlan 作为数据结构记录了对应逻辑算子树节点的基本信息和基本操作,包括输入输出和各种处理逻辑等。
二、实现LogicalPlan 属于 TreeNode 体系,继承自 QueryPlan 父类。
2.1. 结构LogicalPlan 继承自 QueryPlan,包含了两个成员变量和多个方法。
2.1.1. 成员变量
resolved,用来标记该 LogicalPlan 是否为经过了解析
canonicalized,重载了 QueryPlan 中的对应赋值,默认实现消除了子查询别名之后的 LogicalPlan。
三、继承体系LogicalPlan 仍然是抽象类,根据子节点数目,绝大部分的 LogicalPlan 可以分为 3 类,即叶子节点 LeafNode 类型(不存在子节点)、一元节点 UnaryNode 类型(仅包含一个子节点)和二元节点 BinaryNode 类型(包含两个子节点)。此外,还有几个子类直接继承自 LogicalPlan,不属于这 3 种类型。
3.1. ...
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-数据结构-TreeNode 体系
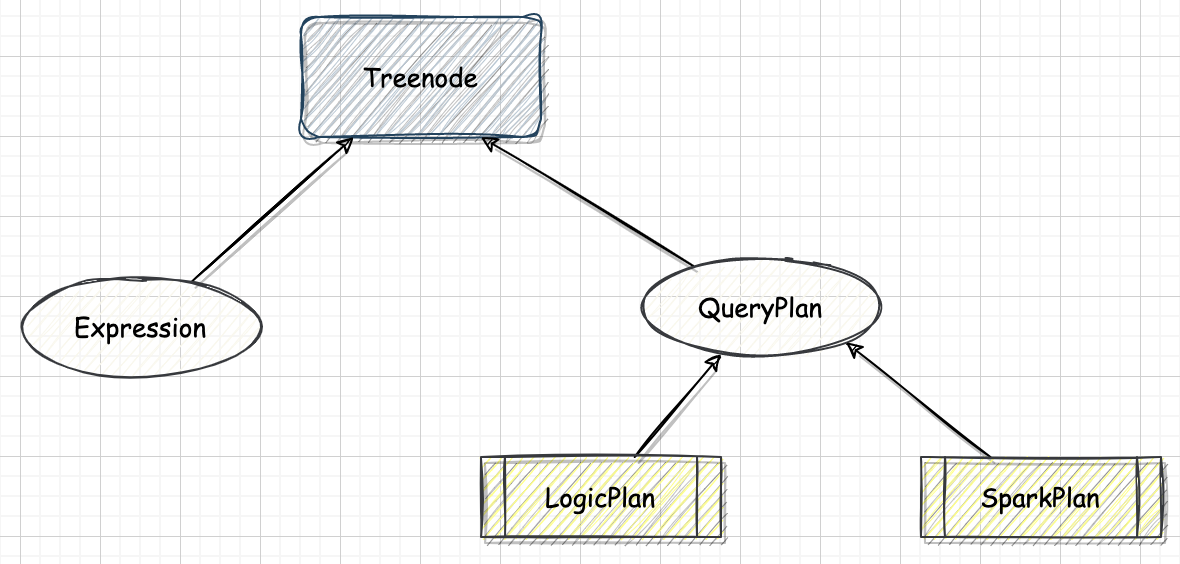
一、概述无论是逻辑计划还是物理计划,都离不开中间数据结构。在 Catalyst 中,对应的是 TreeNode 体系。TreeNode 类是 SparkSQL 中所有树结构的基类,定义了一系列通用的集合操作和树遍历操作接口。
二、实现2.1. 属性TreeNode 内部包含一个 Seq[BaseType] 类型的变量 children 来表示孩子节点。TreeNode 定义了 foreach、 map、collect 等针对节点操作的方法,以及 transformUp 和 transformDown 等遍历节点并对匹配节点进行相应转换的方法。TreeNode 本身是 scala.Product 类型,因此可以通过 productElement 函数或 productlterator 迭代器对 Case Class 参数信息进行素引和遍历。
TreeNode 一直在内存里维护,不会 dump 到磁盘以文件形式存储,且无论在映射逻辑执行计划阶段,还是优化逻辑执行计划阶段,树的修改都是以替换己有节点的方式进行的。
作为基础类,TreeNode 本身仅提供了最简单和最基本的操作。 Tr ...
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Parser 模块-AstBuilder-QueryContext
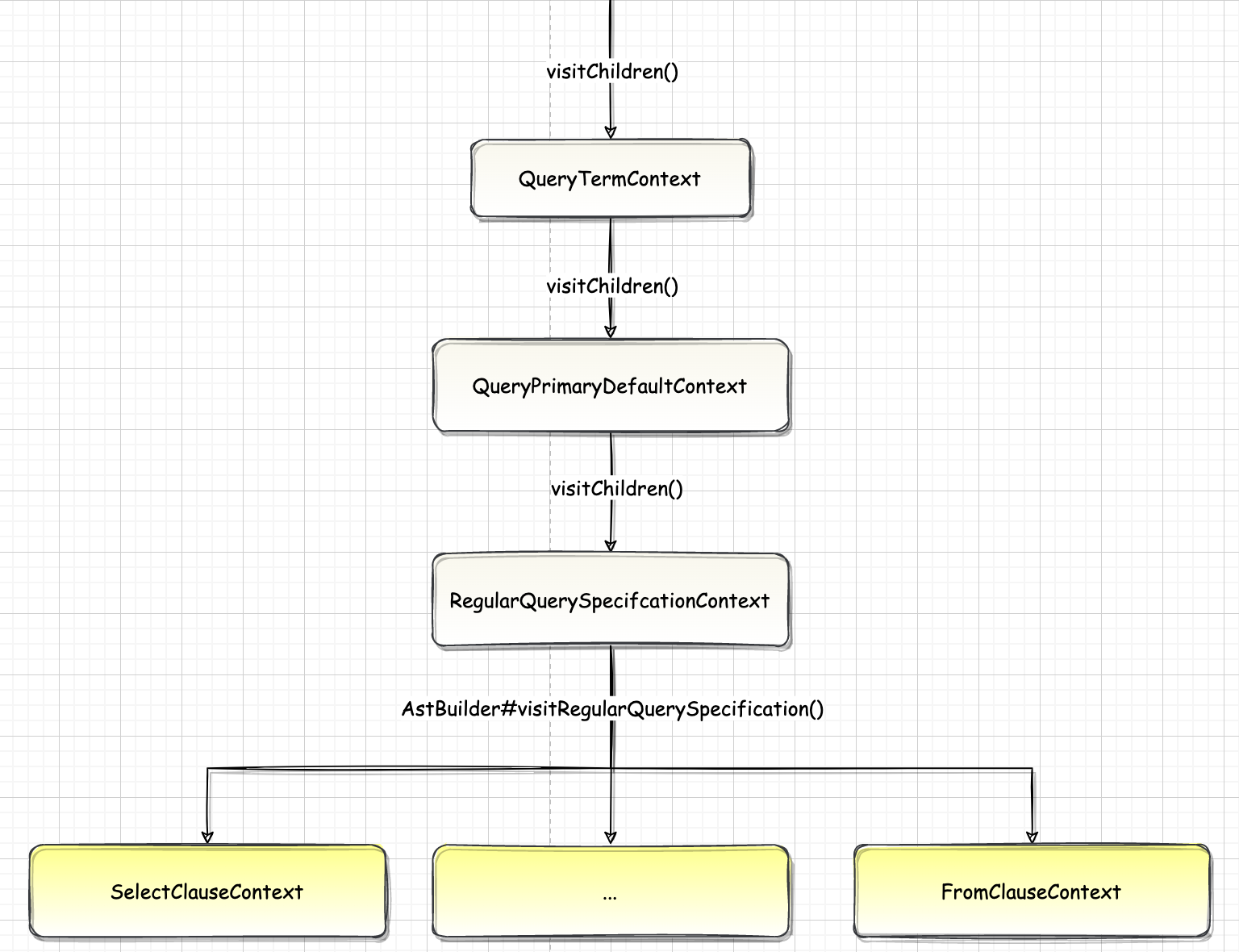
一、概述QueryContext 可以视为 query 语句的根结点~
二、源码12345override def visitQuery(ctx: QueryContext): LogicalPlan = withOrigin(ctx) { val query = plan(ctx.queryTerm).optionalMap(ctx.queryOrganization)(withQueryResultClauses) // Apply CTEs query.optionalMap(ctx.ctes)(withCTE)}
2.1. Query1val query = plan(ctx.queryTerm).optionalMap(ctx.queryOrganization)(withQueryResultClauses)
2.1.1. ctx.queryTerm在 QueryContext 的子节点中查找第一个是 QueryTermContext 类型的节点。AstBuilder 的 $plan$ 方法继续调用 QueryTermCont ...
Spark-源码学习-SparkSQL-架构设计-Parser 模块-AstBuilder-RegularQuerySpecificationContext
一、概述当整个解析过程访问到 RegularQuerySpecification 节点时,执行逻辑可以看作两部分: 首先访问 FromClauseContext 子树, 生成名为 from 的 LogicalPlan; 接下来,调用 withQuerySpecification 方法在 from 的基础上完成后续扩展。
12345678910111213141516override def visitRegularQuerySpecification( ctx: RegularQuerySpecificationContext): LogicalPlan = withOrigin(ctx) { val from = OneRowRelation().optional(ctx.fromClause) { visitFromClause(ctx.fromClause) } withSelectQuerySpecification( ctx, ctx.selectClause, ctx.la ...
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Parser 模块-ParserDriver
二、实现2.1. $parsePlan$调用 $sqlParser.parsePlan$ 执行 parse,SparkSqlParser 类中没有实现 $parsePlan$ 函数,调用父类 $AbstractSqlParser.parsePlan$:
12345678override def parsePlan(sqlText: String): LogicalPlan = parse(sqlText) { parser => astBuilder.visitSingleStatement(parser.singleStatement()) match { case plan: LogicalPlan => plan case _ => val position = Origin(None, None) throw QueryParsingErrors.sqlStatementUnsupportedError(sqlText, position) }}
$parsePlan$ 函 ...
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.















