











计算机基础-操作系统-请求分页存储管理方式
请求分页存储管理与基本分页存储管理的主要区别:
在程序执行过程中,当所访问的信息不在内存时,由操作系统负责将所需信息从外存调入内存,然后继续执行程序。
若内存空间不够,由操作系统负责将内存中暂时用不到的信息换出到外存。
为实现请求分页功能操作系统需要实现:
操作系统要提供请求调页功能,将缺失页面从外存调入内存
操作系统要提供页面置换的功能,将暂时用不到的页面换出外存
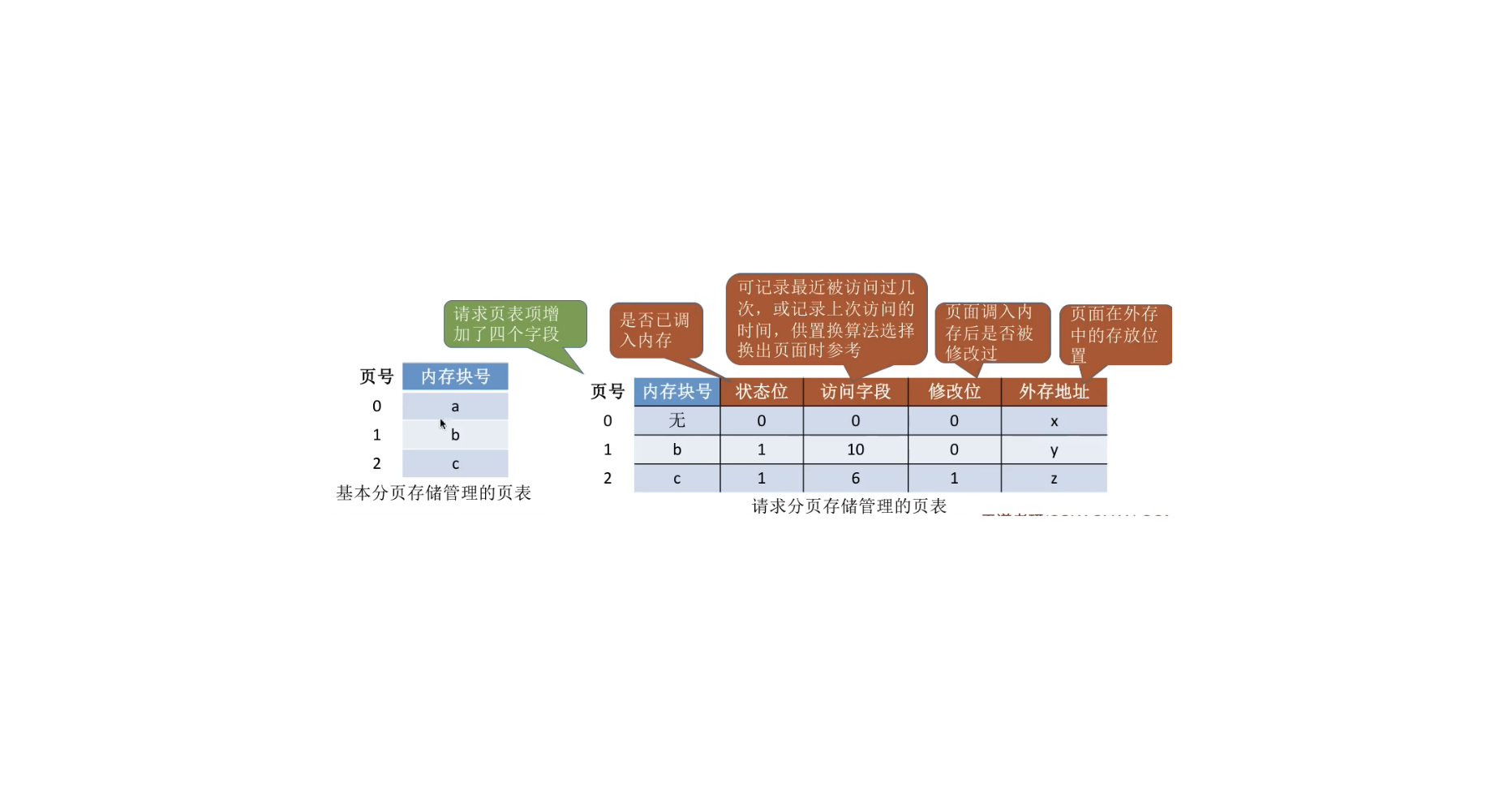
1. 页表机制与基本分页管理相比,请求分页管理中,为了实现“请求调页”,操作系统需要知道每个页面是否已经调入内存:如果还没调入,那么也需要知道该页面在外存中存放的位置。
当内存空间不够时,要实现“页面置换”,操作系统需要通过某些指标来决定到底换出哪个页面;有的页面没有被修改过,就不用再浪费时间写回外存。有的页面修改过,就需要将外存中的旧数据覆盖,因此,操作系统也需要记录各个页面是否被修改的信息。
请求分页存储管理的页表:
2. 缺页中断机构在请求分页系统中,每当要访问的页面不在内存时,便产生一个缺页中断,然后由操作系统的缺页中断处理程序处理中断。此时缺页的进程阻塞,放入阻塞队列,调页完成后再将其唤醒,放回 ...
计算机基础-操作系统-动态分区分配算法
动态分区分配是一种连续分配方法,为各进程分配的空间必须是连续分配方式,为各进程分配的空间必须是连续的一整片区域
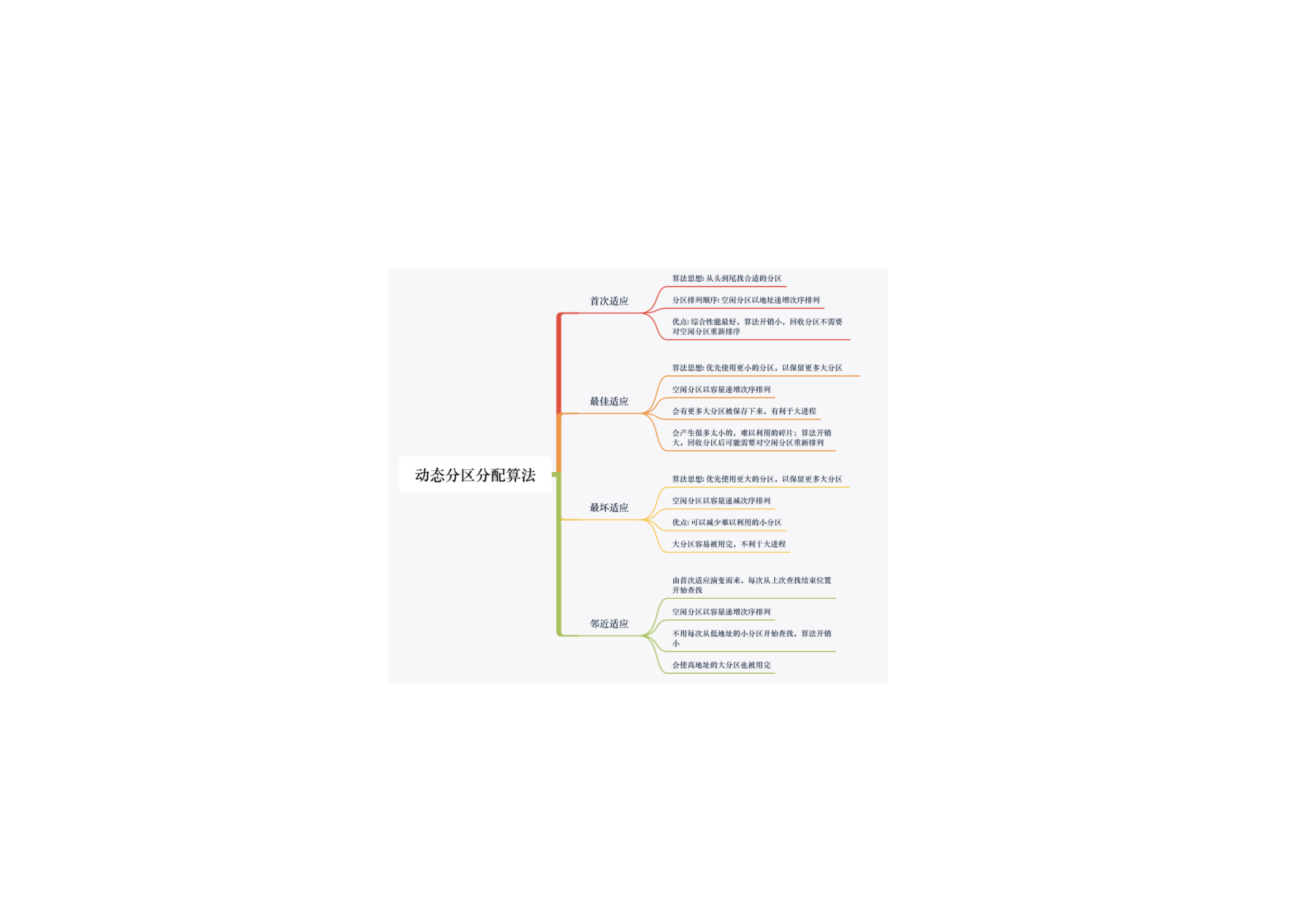
1. 首次适应算法每次都从低地址开始査找,找到第一个能满足大小的空闲分区。
空闲分区以地址递増的次序排列。每次分配内存时顺序查找空闲分区链(或空闲分区表),找到大小能满足要求的第一个空闲分区。
2. 最佳适应算法由于动态分区分配是一种连续分配方式,为各进程分配的空间必须是连续的一整片区域。因此为了保证当“大进程”到来时能有连续的大片空间,可以尽可能多地留下大片的空闲区,即,优先使用更小的空闲区。
空闲分区按容量递增次序链接。每次分配内存时顺序査找空闲分区链(或空闲分区表),找到大小能满足要求的第一个空闲分区
3. 最坏适应算法为了解决最佳适应算法的问题一一即留下太多难以利用的小碎片,可以在每次分配时优先使用最大的连续空闲区,这样分配后剩余的空闲区就不会太小,更方便使用。
空闲分区按容量递减次序链接。每次分配内存时顺序査找空闲分区链(或空闲分区表),找到大小能满足要求的第一个空闲分区。
每次都选最大的分区进行分配,虽然可以让分配后留下的空闲区更大,更可用,但是这种方 ...
计算机基础-操作系统-虚拟内存
传统存储管理暂时用不到的数据也会长期占用内存,导致内存利用率不高
传统存储管理特点:
一次性
作业必须一次性全部装入内存后才能开始运行,这会造成两个问题:
作业很大时,不能全部装入内存,导致大作业无法运行
当大量作业要求运行时,由于内存无法容纳所有作业,因此只有少量作业能运行,导致多道程序并发度下降。
驻留性
一旦作业被装入内存,就会一直驻留在内存中,直至作业运行结束。事实上,在一个时间段内,只需要访问作业的一小部分数据即可正常运行,这就导致了内存中会驻留大量的、暂时用不到的数据,浪费了宝贵的内存资源。
可用虚拟存储技术解决问题
1. 局部性原理1.1. 时间局部性如果执行了程序中的某条指令,那么不久后这条指令很有可能再次执行;如果某个数据被访问过,不久之后该数据很可能再次被访问。(因为程序中存在大量的循环)
1.2. 空间局部性一旦程序访问了某个存储单元,在不久之后,其附近的存储单元也很有可能被访问。(因为很多数据在内存中都是连续存放的,并且程序的指令也是顺序地在内存中存放的)
高速缓冲技术的思想: 将近期会频繁访问到的数据放到更高速的存储器中,暂时用不到的数据 ...
计算机基础-操作系统-文件保护
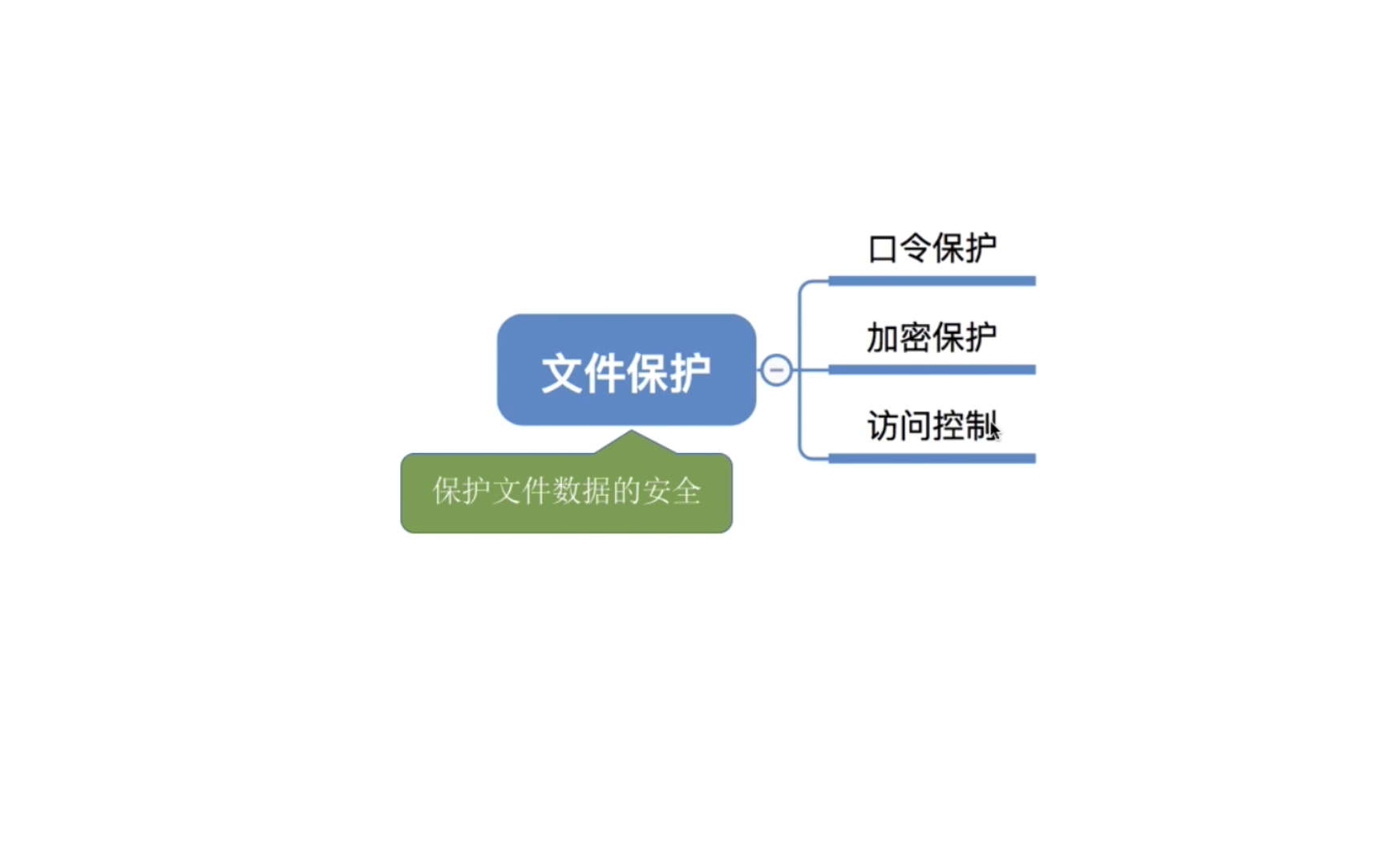
为了防止文件共享可能会导致文件被破坏或未经核准的用户修改文件,文件系统必须控制用户对文件的存取,即解决对文件的读、写、执行的许可问题。为此,必须在文件系统中建立相应的文件保护机制。
文件保护通过口令保护、加密保护和访问控制等方式实现。其中,口令保护和加密保护是为了防止用户文件被他人存取或窃取,而访问控制则用于控制用户对文件的访问方式。
1. 口令保护为文件设置一个 “口令” (如: abc112233), 用户请求访问该文件时必须提供 “口令”
口令一般存放在文件对应的 FCB 或索引结点中。用户访问文件前需要先输入 “口令”,操作系统会将用户提供的口令与 FCB 中存储的口令进行对比,如果正确,则允许该用户访问文件
优点: 保存口令的空间开销不多,验证口令的时间开销也很小
缺点: 正确的 “口令” 存放在系统内部,不够安全
2. 加密保护使用某个 密码 对文件进行加密,在访问文件时需要提供正确的 密码 才能对文件进行正确的解密
举例简单的加密算法: 异或加密,密码 “01001”
文件解密
优点:
保密性强,不需要在系统中存储“密码”
缺点:
编码/译 ...
计算机基础-操作系统-操作系统-段页式管理方式
1. 分页&分段
优点
缺点
分页管理
内存空间利用率高,不会产生外部碎片,只会有少量的页内碎片
不方便按照逻辑模块实现信息的共享和保护
分段管理
很方便按照逻辑模块实现信息的共享和保护
如果段长过大,为其分配很大的连续空间会很不方便。另外,段式管理会产生外部碎片
分段管理中产生的外部碎片也可以用“紧凑”来解决,只是需要付出较大的时间代价
2. 段页式管理基于分段管理和分页管理的优缺点,提出了分页和分段管理的结合,产生了段页式管理
将进程按逻辑模块分段,再将各段分页(如每个页面4KB)再将内存空间分为大小相同的内存块/页框/页帧/物理块进程前将各页面分别装入各内存块中
3. 逻辑地址结构段页式系统的逻辑地址结构由段号、页号、页内地址(页内偏移量)组成。如:
31 $\cdots\cdots$ 16
15 $\cdots\cdots$ 12
11 $\cdots\cdots$ 0
段号
页号
页内偏移量
段号的位数决定了每个进程最多可以分几个段
页号位数决定了每个段最大有多少页
页内偏移量决定了页面大小、内存块大小是多少
“ ...
计算机基础-操作系统-操作系统-内存基本知识-进程运行的基本原理
文件管理,由于系统的内存有限并且不能长期保存,故平时总是把它们以文件的形式存放在外存中,需要时再将它们调入内存。如何高效的对文件进行管理是操作系统实现的目标。
1. 什么是内存内存是用于存放数据的硬件。程序执行前需要先放到内存中才能被 CPU 处理。
思考: 在多道程序环境下,系统中会有多个程序并发执行,也就是说会有多个程序的数据需要同时放到内存中。那么,如何区分各个程序的数据是放在什么地方的呢?
[给内存的存储单元编地址]
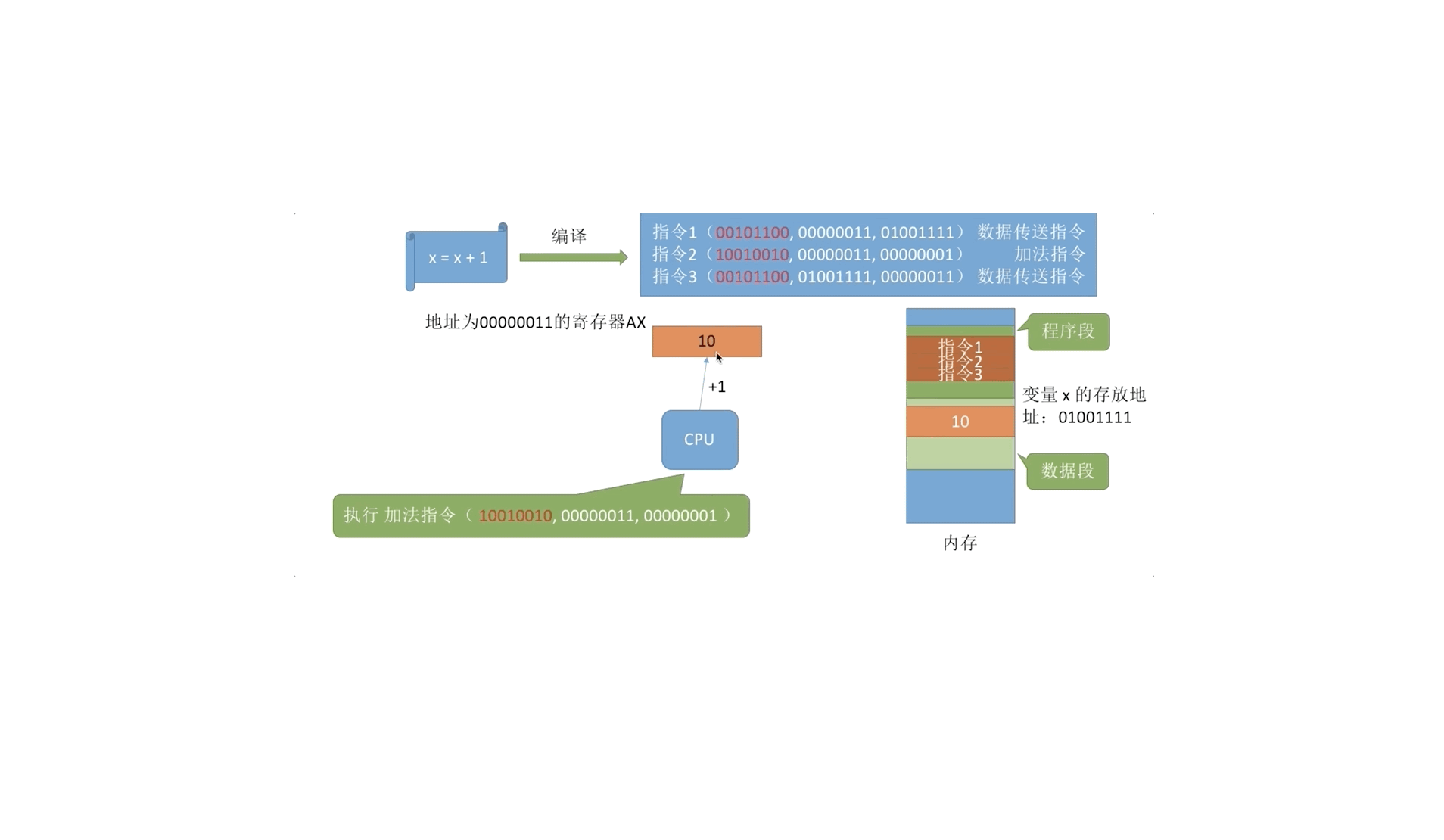
2. 进程运行的基本原理2.1. 指令的工作原理写的代码要翻译成 CPU 能识别的指令。这些指令会告诉 CPU 应该去内存的哪个地址存/取数据,这个数据应该做什么样的处理。
上面指令中直接给出了变量 x 的实际存放地址(物理地址)。但实际在生成机器指令的时候并不知道该进程的数据会被放到什么位置。所以编译生成的指令中一般是使用逻辑地址(相对地址)
2.2. 逻辑地址&物理地址宿舍四个人一起出去旅行,四个人的学号尾号分别是0、1、2、3。住酒店时酒店给你们安排了 4 个房号相连的房间。四个人按学号递增次序入住房间。比如 0、1、2、3 号同学 ...

计算机基础-操作系统-操作系统-基本分段存储管理方式
进程的地址空间按照程序自身的逻辑关系划分为若干个段,每个段都有一个段名(在低级语言中,程序员使用段名来编程),每段从0开始编址。以段为单位进行分配,每个段在内存中占据连续空间,但各段之间可以不相邻,与 “分页” 最大的区别就是离散分配时所分配地址空间的基本单位不同
由于是按逻辑功能模块划分,用户编程更方便,程序的可读性更高
1. 逻辑地址结构分段系统的逻辑地址结构由段号(段名)和段内地址(段肉偏移量)所组成。如:
31 $\cdots\cdots$ 16
15 $\cdots\cdots$ 0
段号
段内地址
段号的位数决定了每个进程最多可以分几个段,段内地址位数决定了每个段的最大长度是多少
若系统是按字节寻址的,段号占16位,因此在该系统中,每个进程最多有 $2^{16}=64K$个段,段内地址占16位,因此每个段的最大长度是 $2^{16}=64KB$。
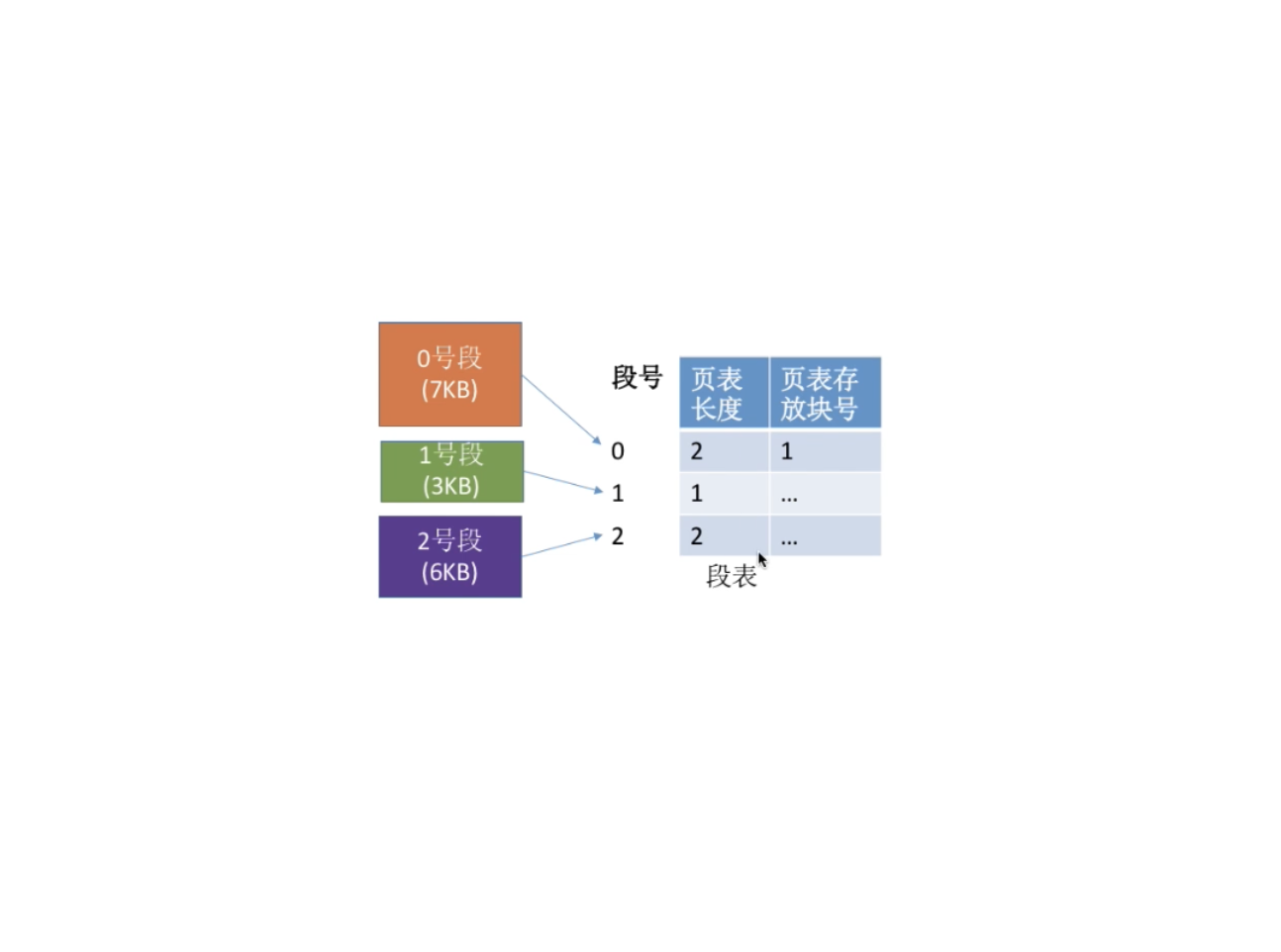
2. 段表程序分多个段,各段离散地装入内存,为了保证程序能正常运行,就必须能从物理内存中找到各个逻辑段的存放位置。为此,需为每个进程建立一张段映射表,简称 “段表”。
每个段对应一个段表项,其 ...

计算机基础-操作系统-操作系统-基本分页存储管理方式
基本分页存储管理的思想:把内存分为一个个相等的小分区,再按照分区大小把进程拆分成一个个小部分
1. 分页思想将内存空间分为一个个大小相等的分区(比如: 每个分区 4 KB),每个分区就是一个 “页框”,每个页框有一个编号,即 “页框号”,页框号从 0 开始。
将用户进程的地址空间也分为与页框大小相等的一个个区域,称为 “页” 或 “页面” 。每个页面也有一个编号,即“页号”,页号也是从 0 开始。
注: 进程的最后一个页面可能没有一个页框那么大。因此,页框不能太大,否则可能产生过大的内部碎片
操作系统以页框为单位为各个进程分配内存空间。进程的每个页面分别放入一个页框中。也就是说,进程的页面与内存的页框有一一对应的关系。
各个页面不必连续存放,世不必按先后顺序来,可以放到不相邻的各个页框中。
2. 地址转换逻辑地址为80 的内存单元: 应该在1号页,该页在内存中的起始位置为 450,逻辑地址为 80 的内存单元相对于该页的起始地址而言,”偏移量” 应该是 30。实际物理地址 = 450 + 30 = 480
要算出逻辑地址对应的页号
页号=逻辑地址/页面长度 ...

计算机基础-操作系统-处理机调度概述
在多道程序系统中,进程的数量往往是多于处理机的个数的,这样不可能同时并行地处理各个进程。处理机调度,就是从就绪队列中按照一定的算法选择一个进程并将处理机分配给它运行,以实现进程的并发执行。
当有一堆任务要处理,但由于资源有限,这些事情没法同时处理。这就需要确定某种规则来决定处理这些任务的顺序
1. 高级调度(作业调度)由于内存空间有限,有时无法将用户提交的作业全部放入内存,因此就需要确定某种规则来决定将作业调入内存的顺序。
高级调度(作业调度)。按一定的原则从外存上处于后备队列的作业中挑选一个(或多个)作业,给他们分配内存等必要资源,并建立相应的进程(建立PCB),以使它(们)获得竞争处理机的权利。
高级调度是辅存(外存)与内存之间的调度。每个作业只调入一次,调出一次。作业调入时会建立相应的PCB,作业调出时才撤销PCB。高级调度主要是指调入的问题,因为只有调入的时机需要操作系统来确定,但调岀的时机必然是作业运行结束才调出
2. 中级调度(内存调度)引入了虚拟存储技术之后,可将暂时不能运行的进程调至外存等待。等它重新具备了运行条件且内存又稍有空闲时,再重新调入内存。
这 ...

计算机基础-操作系统-操作系统-假脱机技术
CPU 无法直接控制 IO 设备的机械部件,因此 IO 设备还要有个电子部件作为 CPU 和 IO 设备机械部件之间的”中介”,用于实现 CPU 对设备的控制。这个电子部件就是 IO 控制器,又称为设备控制器。CPU 可控制 IO 控制器,IO 控制器来控制设备的机械部件。
1. 脱机技术手工操作阶段:主机直接从 I/O 设备获得数据,由于设备速度慢,主机速度很快。人机速度矛盾明显,主机要浪费很多时间来等待设备
批处理阶段引入了脱机输入/输出技术了用磁带完成):
引入脱机技术后,缓解了 CPU 与慢速 I/O 设备的速度矛盾。另一方面,即使 CPU 在忙碌,也可以提前将数据输入到磁带:即使慢速的输出设备正在忙碌,也可以提前将数据输出到磁带。
为什么称为“脱机”? 一一脱离主机的控制进行的输入/输出操作。
2. SPOOLing“假脱机技术”,又称 “SPOOLing 技术” 是用软件的方式模拟脱机技术。SPOOLing 系统的组成如下:
在磁盘上开辟出两个存储区域一一”输入井”和”输出井”
2.1.输入井输入井模拟脱机输入时的磁带,用于收容 I/O 设备输入 ...
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.















