












计算机基础-操作系统-操作系统-内存管理
操作系统作为系统资源的管理者,也需要对内存进行管理
1. 内存空间的分配与回收
操作系统如何记录哪些内存区域已经被分配出去哪些还空闲?
很多位置可以存放,应该存放在哪里?
进程运行结束之后,如何将进程占用的内存空间回收?
2. 内存空间的扩展操作系统需要提供某种技术从逻辑上对内存空间进行扩充
3. 地址转换为了使编程方便,程序员写程序时应该只需要关注指令、数据的逻辑地址。而逻辑地址到物理地址的转换应该由操作系统负责(这个过程称为重定位),这样就保证了程序员写程序时不需要关注物理内存的实际情况。
操作系统需要提供地址转换功能,负责程序的逻辑地址与物理地址的转换
4. 内存保护操作系统需要提供內存保护功能。保证各进程在各自存储空间内运行,互不干扰
内存保护可采取两种方法:
4.1. 上、下限寄存器在 CPU 中设置一对上、下限寄存器,存放进程的上、下限地址。进程的指令要访问某个地址时,CPU 检查是否越界。
4.2. 重定位寄存器和界地址寄存器采用重定位寄存器(又称基址寄存器)和界地址寄存器(又称限长寄存器)进行越界检查。重定位寄存器中存放的是进程的起始物理地址。 ...
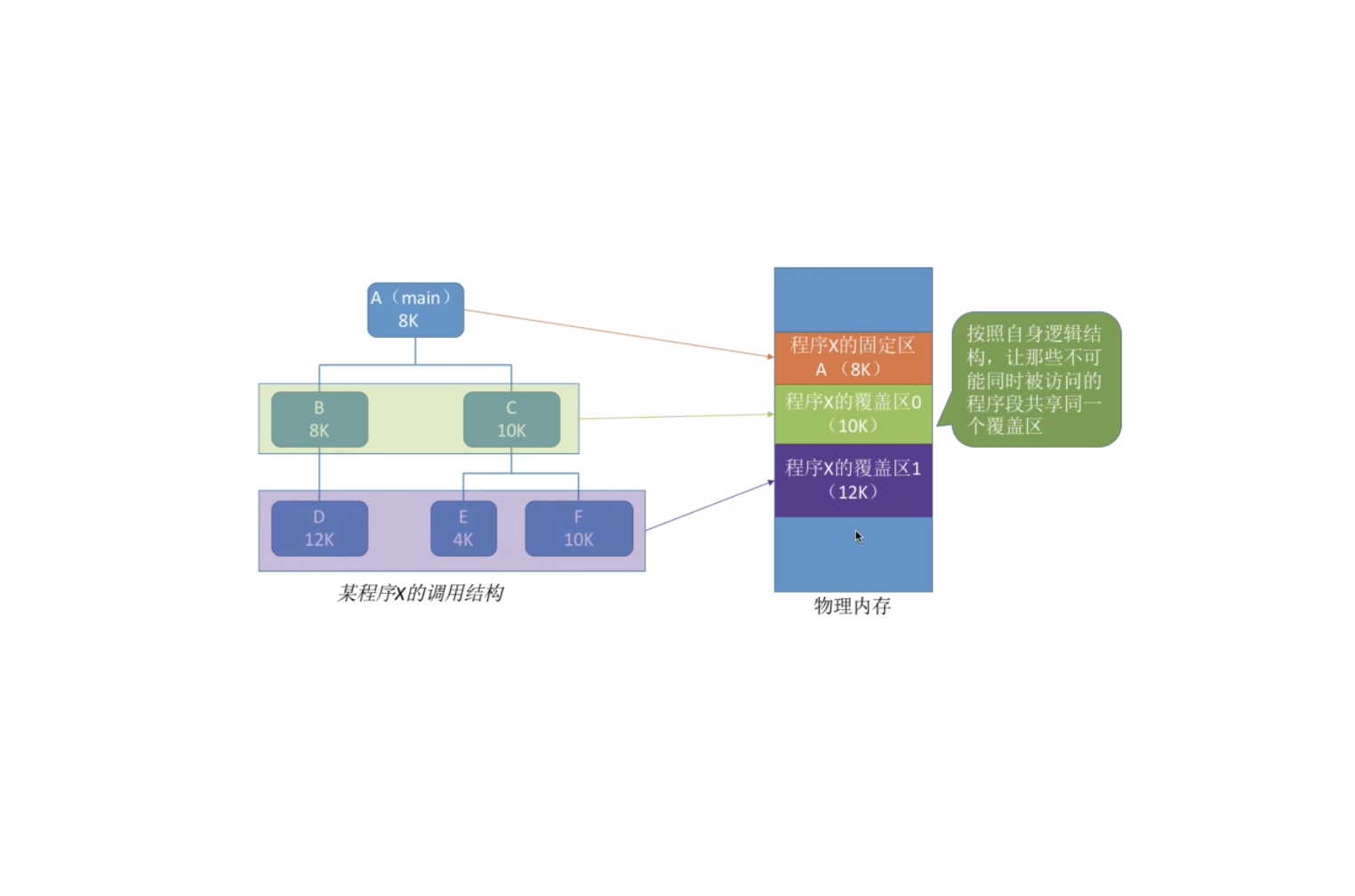
计算机基础-操作系统-内存空间扩充_覆盖&交换技术
早期的计算机内存很小,比如 IBM 推出的第一台 PC 机最大只支持 1MB 大小的内存。因此经常出现内存大小不够的情况。后来人们引入了覆盖技术,用来解决“程序大小超过物理内存总和”的问题。
1. 覆盖技术将程序分为多个段(多个模块),常用的段常驻内存,不常用的段在需要时调入内存。内存中分为一个“固定区”和若干个“覆盖区”。需要常驻内存的段放在“固定区”中,调入后就不再调出(除非运行结束)。不常用的段放在“覆盖区”,需要用到时调入内存,用不到时调出内存。
覆盖技术必须由程序员声明覆盖结构,操作系统完成自动覆盖。缺点是对用户不透明,增加了用户编程负担。所以覆盖技术只用于早期的操作系统中,现在已成为历史。
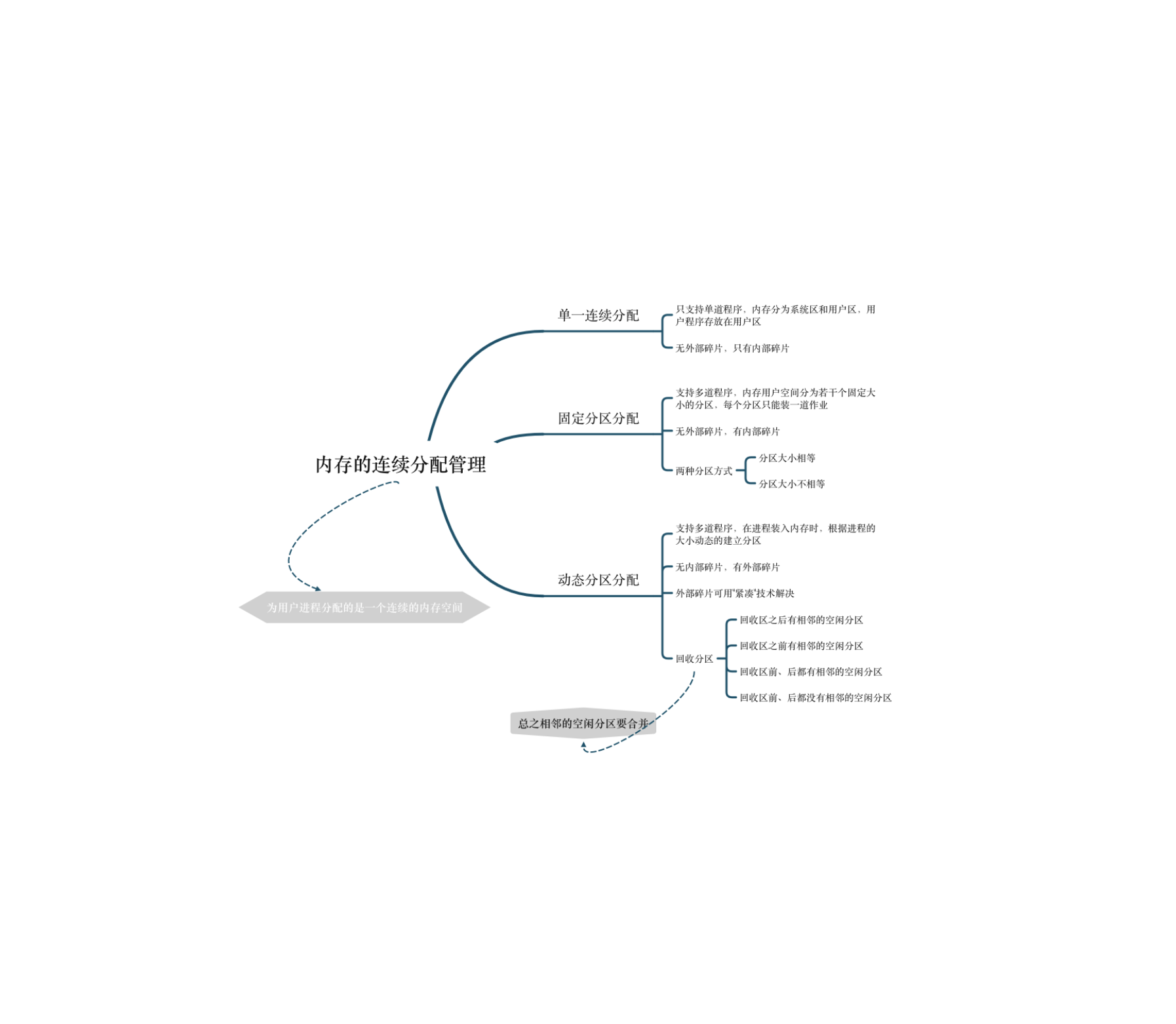
2. 交换技术内存空间紧张时,系统将内存中的某些进程暂时换出到外存,把外存中某些已具备运行条件的进程换入到内存(进程在内存和外存动态调度)。暂时换出到外存等待的进程状态为挂起状态(挂起态,suspend)。挂起态又可以进一步细分为就绪挂起、阻塞挂起两种状态。
2.1. 应该在外存的什么位置保存被换出的进程?具有交换换功能的操作系统中,通常把磁盘空间分为文件区和对换区两部分 ...
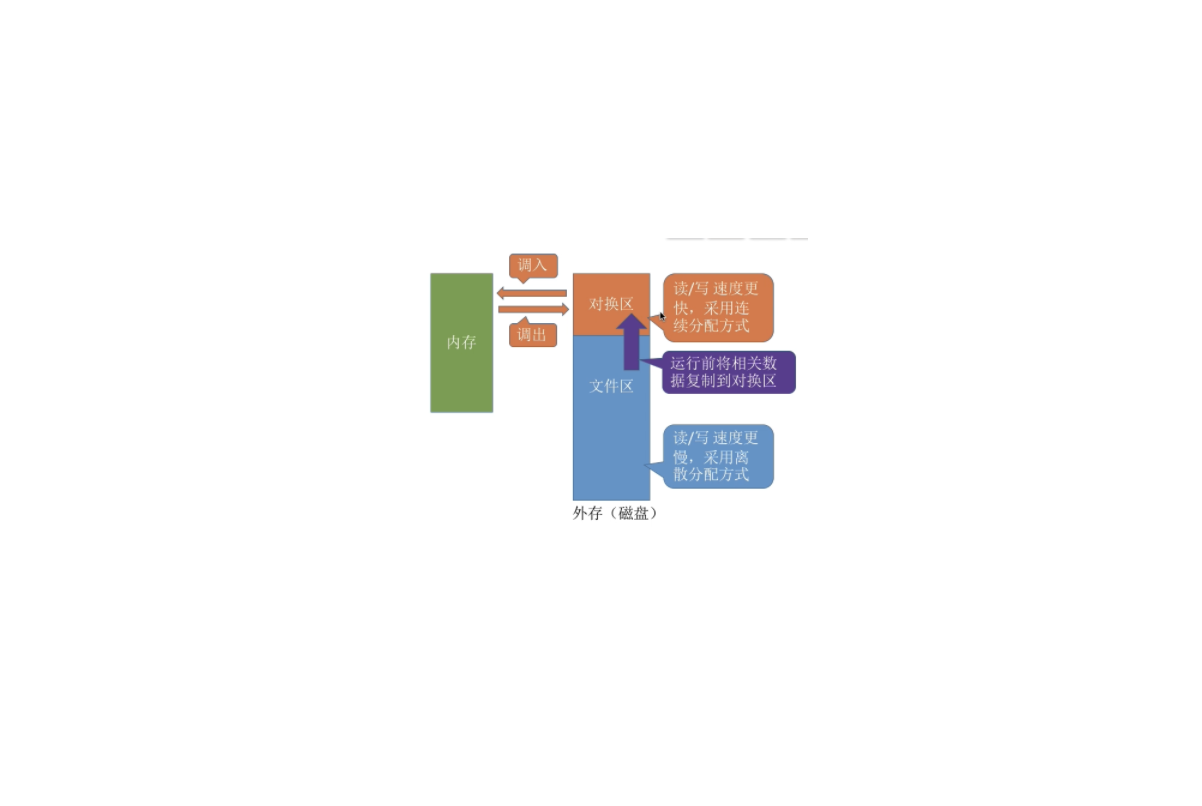
计算机基础-操作系统-操作系统-内存的分配
在单一连续分配方式中,内存被分为系统区和用户区。
1. 内存空间的分配1.1. 连续分配管理1.1.1. 单一连续分配系统区通常位于内存的低地址部分,用于存放操作系统相关数据;用户区用于存放用户进程相关数据。内存中只能有一道用户程序,用户程序独占整个用户区空间。
优点
实现简单
无外部碎片
可以采用覆盖技术扩充内存
不一定需要采取内存保护
缺点
只能用于单用户、单任务的操作系统中
有内部碎片
存储器利用率极低。
1.1.2. 固定分区分配20世纪60年代出现了支持多道程序的系统,为了能在内存中装入多道程序,且这些程序之间又不会相互干扰,于是将整个用户空间划分为若干个固定大小的分区,在每个分区中只装入一道作业,这样就形成了最早的、最简单的一种可运行多道程序的内存管理方式。
分区大小相等缺乏灵活性,但是很适合用于用一台计算机控制多个相同对象的场合
分区大小不相等增加了灵活性,可以满足不同大小的进程需求。根据常在系统中运行的作业大小情况进行划分(比如:划分多个小分区、适量中等分区、少量大分区)
固定分区分配中操作系统需要建立一个数据结构一一分区说 ...
计算机基础-操作系统-页面分配策略
请求分页存储管理中给进程分配的物理块的集合。在采用了虚拟存储技术的系统中,驻留集大小一般小于进程的总大小。若驻留集太小,会导致缺页频繁,系统要花大量的时间来处理缺页,实际用于进程推进的时间很少。驻留集太大,又会导致多道程序并发度下降,资源利用率降低。所以应该选择一个合适的驻留集大小。
1. 页面分配、置换策略1.1. 相关概念1.1.1. 驻留集请求分页存储管理中给进程分配的物理块的集合。在采用了虚拟存储技术的系统中,驻留集大小一般小于进程的总大小。
若驻留集太小,会导致缺页频繁,系统要花大量的时间来处理缺页,实际用于进程推进的时间很少。
驻留集太大,又会导致多道程序并发度下降,资源利用率降低。
所以应该选择一个合适的驻留集大小。
1.1.2. 固定分配&可变分配固定分配
操作系统为每个进程分配一组固定数目的物理块,在进程运行期间不再改变。即,驻留集大小不变
可变分配
先为每个进程分配一定数目的物理块,在进程运行期间,可根据情况做适当的增加或减少。即,驻留集大小可变
1.1.3. 局部置换&全局置换局部置换
发生缺页时只能选进程自己的物理块进行置换。
...
计算机基础-操作系统-操作系统-进程概述
引入多道程序技术之后为了方便操作系统管理,完成各程序并发执行,引入了进程、进程实体(PCB、程序段、数据段三部分构成了进程实体(进程映像))的概念
1. 进程的定义程序段、数据段、PCB 三部分组成了进程实体(进程映像)。一般情况下,把进程实体就简称为进程,创建进程,实质上是创建进程实体中的 PCB;而撤销进程,实质上是撤销进程实体中的 PCB。注意: PCB 是进程存在的唯一标志!
从不同的角度, 进程可以有不同的定义, 比较传统典型的定义有
进程是程序的一次执行过程
进程是一个程序及其数据在处理机上顺序执行时所发生的活动。
进程是具有独立功能的程序在数据集合上运行的过程(强调动态性!),它是系统进行资源分配和调度的一个独立单位
引入进程实体的概念后,可把进程定义为: 进程是进程实体的运行过程,是系统进行资源分配和调度的一个独立单位。
注: 严格来说,进程实体和进程并不一样,进程实体是静态的,进程则是动态的。
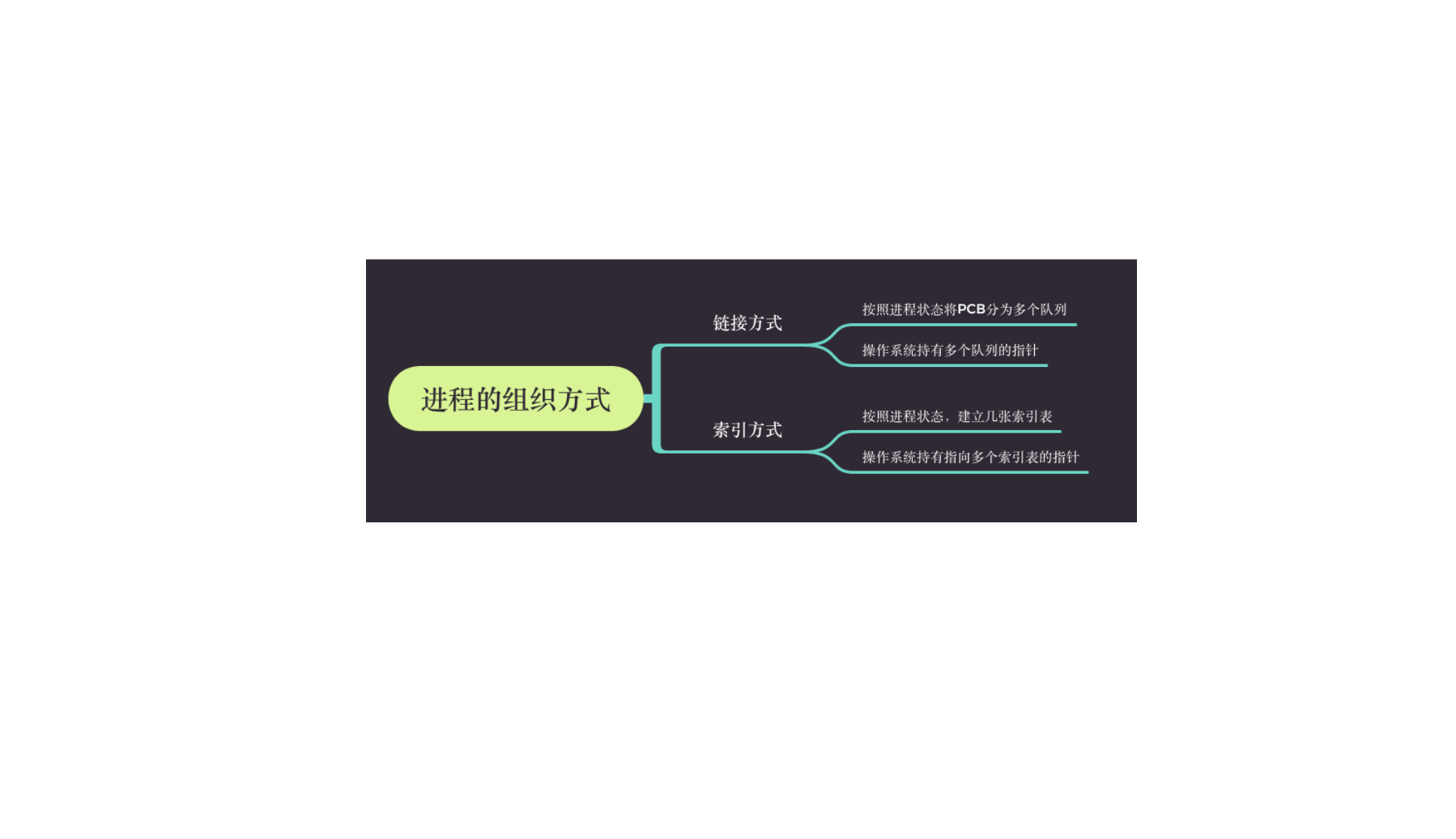
2. 进程的组成3. 进程的组织在一个系统中,通常有数十、数百乃至数千个PCB。为了能对他们加以有效的管理,应该用适当的方式把这些 PCB 组织起来
进程的组成讨论的 ...
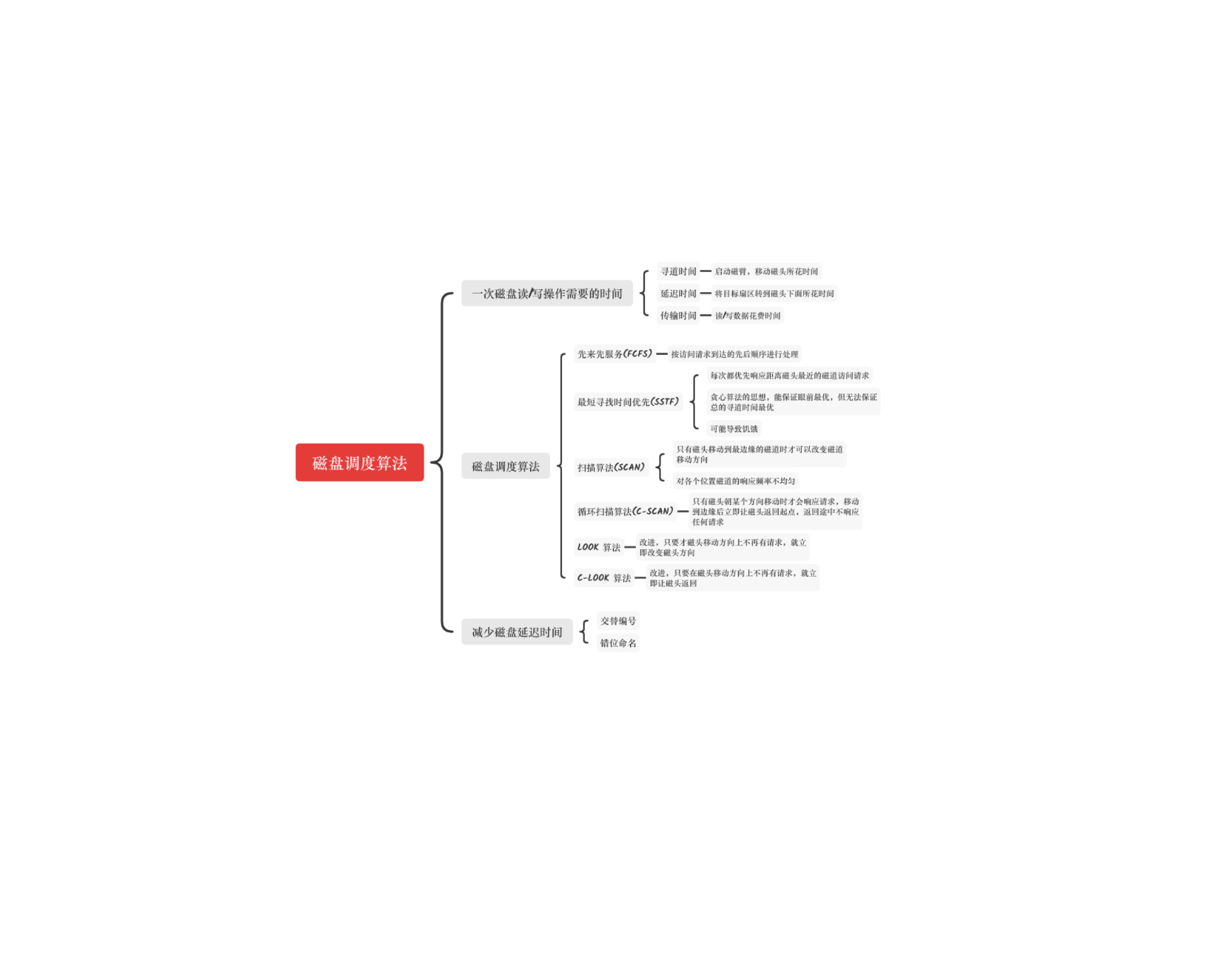
计算机基础-操作系统-磁盘调度算法
磁盘一次读或写操作总的存取时间=寻道时间+延迟时间+传输时间,但是由于延迟时间和传输时间都与硬盘的转速有关,转速越大,时间越短,因此系统需要优化的是寻道时间,以下所讲的磁盘调度算法都是服务于寻道时间
1. 一次磁盘读/写操作需要的时间
寻道时间
在读写前,将磁头移动到指定磁道所花的时间。其实启动磁头臂也是需要时间的,这里把它记为 s.移动磁头时,每跨越一个磁道耗时m,总共假设跨越n个磁道。所以寻道时间 T=mn+s;
延迟时间
通过旋转磁盘,是磁头到达目标扇区所需要的时间。转速设为r.所以平均所需的延迟时间 Tr=(1/2)*(1/r)=1/2r
传输时间
从磁盘读出或向磁盘写入数据所经历的时间,假设磁盘转速是r,读写字节为b,每个磁道上的字节数是N,则:Tt=(1/r)*(b/N)=b/(rN)
2.1. 先来先服务算法根据进程请求访问磁盘的先后顺序进行调度
假设磁头的初始位置是 100 号磁道,有多个进程先后陆续的请求访问 55, 58, 39, 18, 90, 160, 150, 38, 184
磁头总共移动了 45 + 3 + 19 + 21 + 72 + ...
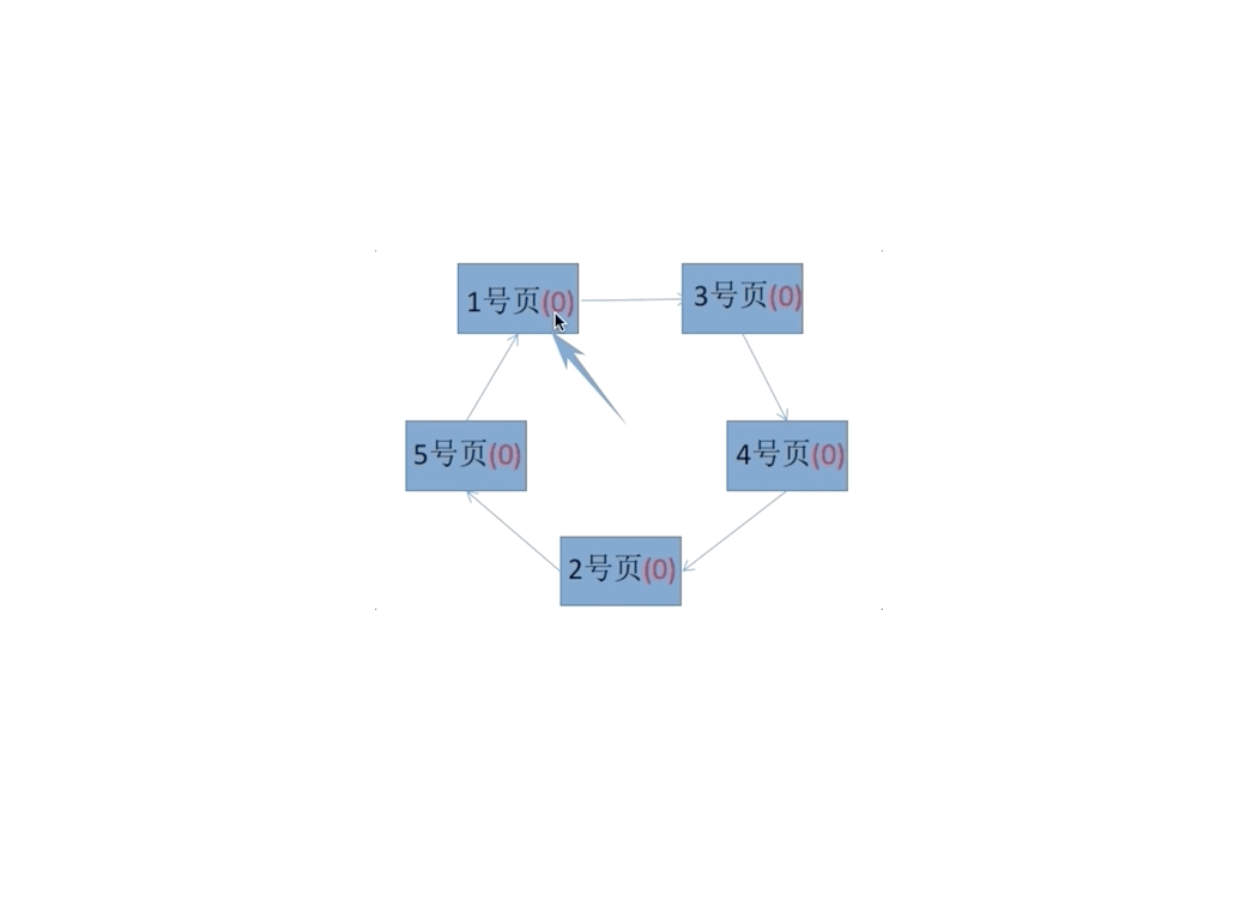
计算机基础-操作系统-页面置换算法
地址映射过程中,若在页面中发现所要访问的页面不在内存中,则产生缺页中断。当发生缺页中断时,如果操作系统内存中没有空闲页面,则操作系统必须在内存选择一个页面将其移出内存,以便为即将调入的页面让出空间。而用来选择淘汰哪一页的规则叫做页面置换算法。
1. 最佳置换算法(OPT)最佳置换算法(OPT, Optimal):每次选择淘汰的页面将是以后永不使用,或者在最长时间内不再被访问的页面,这样可以保证最低的缺页率。
最佳置换算法可以保证最低的缺页率,但实际上,只有在进程执行的过程中才能知道接下来会访问到的是哪个页面。操作系统无法提前预判页面访问序列。因此,最佳置换算法是无法实现的。
2. FIFO先进先出置换算法(FIFO):每次选择淘汰的页面是最早进入内存的页面
实现方法:把调入内存的页面根据调入的先后顺序排成一个队列,需要换出页面时选择队头页面即可。队列的最大长度取决于系统为进程分配了多少个内存块。
$系统为某进程分配了四个内存块,考虑到以下页面号引用串3, 2, 1, 0, 3, 2, 4 ,3, 2, 1, 0, 4
Belady 异常一一当为进程分配的物理块数增大时,缺页 ...
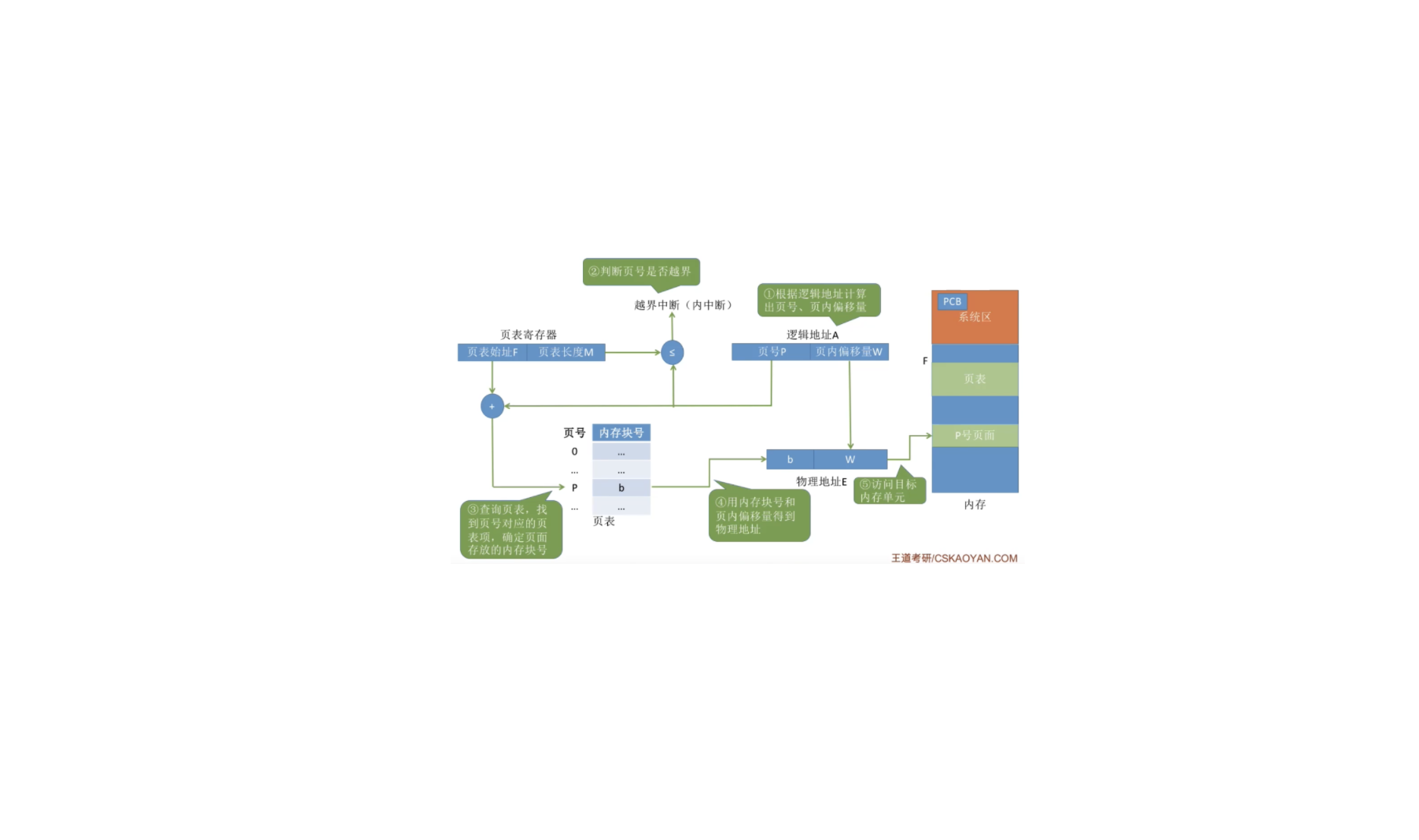
计算机基础-操作系统-地址变换机构
地址变换机构用于实现逻辑地址到物理地址转换的一组硬件机构
1. 基本地址变换机构基本地址变换机构可以借助进程的页表将逻辑地址转换为物理地址。通常会在系统中设置一个页表寄存器(PTR),存放页表在内存中的起始地址F和页表长度M。进程未执行时,页表的始址和页表长度放在进程控制块(PCB)中,当进程被调度时,操作系统内核会把它们放到页表寄存器中。
设页面大小为 L,逻辑地址 A 到物理地址 E 的变换过程如下:
根据逻辑地址计算出页号、页内偏移量
判断页号是否越界:页表长度就是页表中页表项的个数,有多少个页表项就有多少个页面。如果页号P >= 页表长度 M,则抛出越界中断。否则,进入 (3)
查询页表,找到页号对应的页表项,确定页面存放的内存块号: 根据页号 P 和页表起始地址F得到该页号对应的页表项在内存块中的地址=页号P * 页表项大小 + 页表起始地址 F。通过页表项在内存块中的地址,找到这个页表项之后,便可以得到页表项中的内存块号,然后进入(4)
用内存块号和页内偏移量得到物理地址: b号内存块号(即 P 号页面)在内存中的起始地址=b*每个内存块的大小。然后得到物 ...
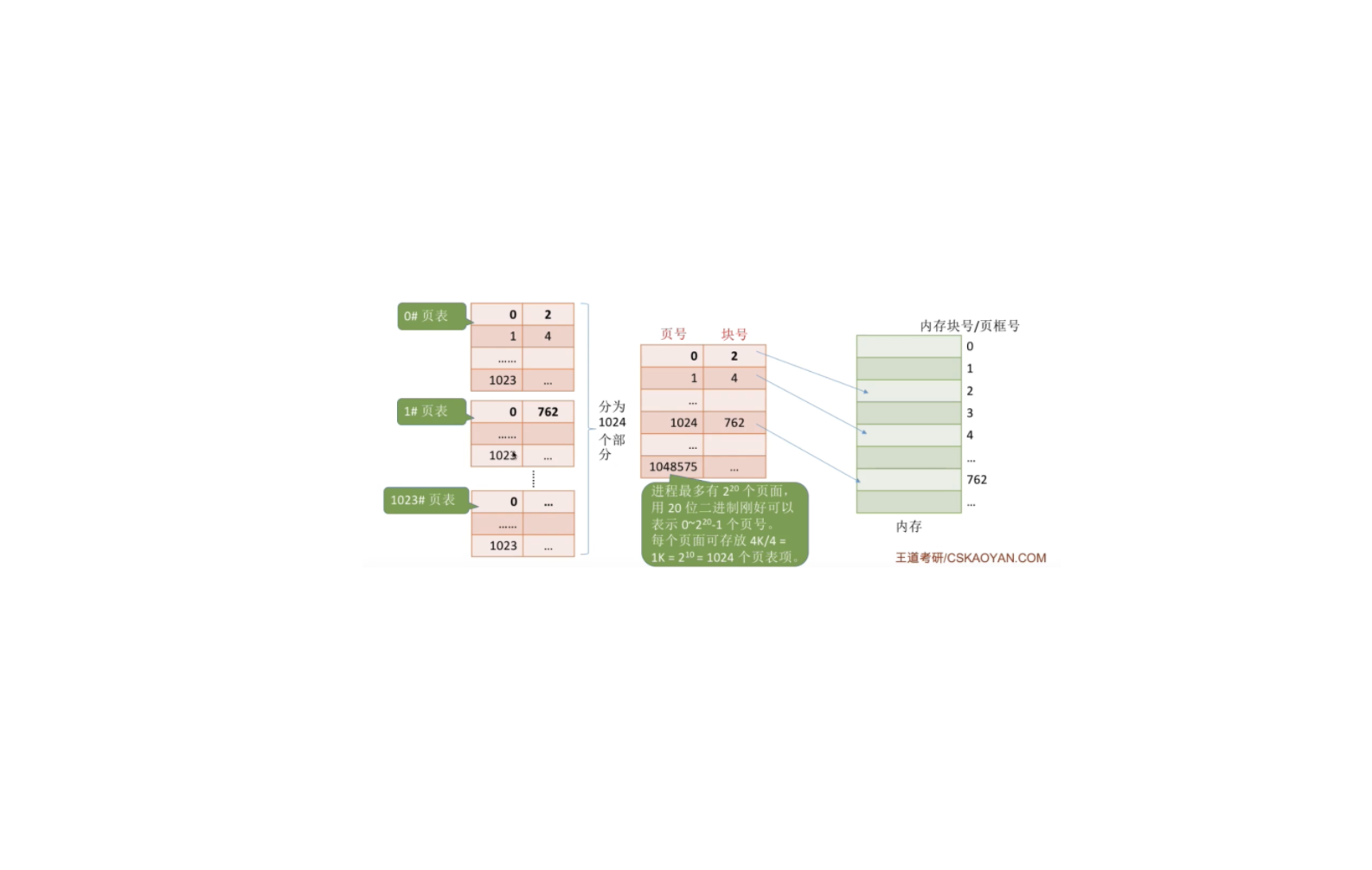
计算机基础-操作系统-操作系统-两级页表
页表必须连续存放,因此当页表很大时,需要占用很多个连续的页框
将长长的页表进行分组,使每个内存块刚好可以放入一个分组
比如页面大小 4KB ,每个页表项 4B ,每个页面可存放 1K 个页表项,因此每 1K 个连续的页表项为一组,每组刚好占一个内存块,再将各组离散地放到各个内存块中
另外,要为离散分配的页表再建立一张页表,称为页目录表,或称外层页表,或称顶层页表
1. 两级页表原理单级页表的逻辑地址结构: 32 位逻辑地址空间,页表项大小为 4B,页面大小为 4KB,则页内地址占 12 位
31 $\cdots\cdots$ 12
11 $\cdots\cdots$ 0
页号
页内偏移量
二级页表的逻辑地址结构:
31 $ \cdots\cdots $ 22
21 $\cdots\cdots$ 12
11 $\cdots\cdots$ 0
一级页号
二级页号
页内偏移量
2.地址变换例: 将逻辑地址(0000000000,0000006004,111111121112)转换为物理地址(用十进制表示)
按照地址结构将逻辑地址拆分成三部分 ...

计算机基础-操作系统-磁盘结构
磁盘的结构一般由磁头(磁盘最昂贵的部分),盘面,磁道,扇区组成。一个盘有正反两面,磁道与磁道之间隔有一定距离。一个硬盘有多个磁盘,磁盘之间有两个磁头。
1. 磁盘结构传统的硬盘盘结构有一个或多个盘片,用于存储数据。中间有一个主轴,所有的盘片都绕着这个主轴转动。一个组合臂上面有多个磁头臂,每个磁头臂上面都有一个磁头,负责读写数据。
1.1. 盘面磁盘一般有一个或多个盘片。每个盘片可以有两面,即第一个盘片的正面为0面,反面为 1 面;第二个盘片的正面为 2 面…依次类推。磁头的编号也和盘面的编号是一样的,因此有多少个盘面就有多少个磁头。
盘面正视图如下图,磁头的传动臂只能在盘片的内外磁道之间移动。因此不管开机还是关机,磁头总是在盘片上面。关机时,磁头停在盘片上面,抖动容易划伤盘面造成数据损失,为了避免这样的情况,所以磁头都是停留在起停区的,起停区是没有数据的。
1.2. 磁道每个盘片的盘面被划分成多个狭窄的同心圆环,数据就存储在这样的同心圆环上面,我们将这样的圆环称为**磁道 (Track)**。每个盘面可以划分多个磁道,最外圈的磁道是0号磁道,向圆心增长依次为1磁道、2磁道…磁盘 ...
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.















