












Spark-理论笔记-共享变量
Spark 中所有 transformation 算子是通过分发到多个节点上的并行任务实现运行并行化的。当将一个自定义函数传递给 Spark 算子时(比如map或reduce),该函数所包含的变量会通过副本方式传播到远程节点上。但所有针对这些变量的写操作只会更新到本地,不会传递回驱动程序以及分布式更新,通常跨任务的读写变量是低效的。故而 Spark 提供了两种受限的共享变量:广播变量和共享变量。
广播变量 broadcast variable什么是广播变量广播变量是一种能够分发到集群各个节点上的只读变量,Driver 端将变量分发给各 Executor,Executor 只需保存该变量的一个副本,而不是每个 task 各分发一份,避免了 task 过多时候,Driver 的带宽成为系统瓶颈,以及 task 服务器上的资源消耗。Spark 实现了高效的广播算法保证广播变量得到高效的分发。
不使用广播变量
使用广播变量
广播变量创建和使用定义广播变量12val a = 3val broadcast = sc.broadcast(a)
使用广播变量1val data = bro ...

Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Planner 模块-Strategy-BasicOperators
一、概述所有的策略都继承自 GenericStrategy 类,其中定义了 planLater 和 apply 方法;SparkStrategy 继承自 GenericStrategy 类,对其中的 planLater 进行了实现,根据传入的 LogicalPlan 直接生成前述提到的 PlanLater 节点 。 此外,在 Spark SQL 中
Strategy 是 SparkStrategy 类的别名
1type Strategy = SparkStrategy
二、实现
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Planner 模块-Strategy-FileSourceStrategy
一、概述所有的策略都继承自 GenericStrategy 类,其中定义了 planLater 和 apply 方法;SparkStrategy 继承自 GenericStrategy 类,对其中的 planLater 进行了实现,根据传入的 LogicalPlan 直接生成前述提到的 PlanLater 节点 。 此外,在 Spark SQL 中
Strategy 是 SparkStrategy 类的别名
1type Strategy = SparkStrategy
二、实现
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Planner 模块-Strategy-JoinSelection
一、概述所有的策略都继承自 GenericStrategy 类,其中定义了 planLater 和 apply 方法;SparkStrategy 继承自 GenericStrategy 类,对其中的 planLater 进行了实现,根据传入的 LogicalPlan 直接生成前述提到的 PlanLater 节点 。 此外,在 Spark SQL 中
Strategy 是 SparkStrategy 类的别名
1type Strategy = SparkStrategy
二、实现
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Strategy 体系-QueryPlanner
一、概述SparkPlanner 继承自 SparkStrategies 类,而 SparkStrategies 类则继承自 QueryPlanner 基类,重要的 plan() 方法实现就在 QueryPlanner 类中 。 SparkStrategies 类本身不提供任何方法,而是在内部提供一 批 SparkPlanner 会用到的各种策略( Strate盯)实现。 最后 ,在 SparkPlanner 层面将这些策略整
合在一起,通过 plan()方法进行逐个应用 。
类似逻辑计划阶段的 Anaylzer 和 Optimizer,SparkPlanner 本身只是一个逻辑的驱动 ,各种策略的 apply 方法把逻辑执行计划算子映射成物理执行计划算子。
二、实现2.1. $plan$$plan$ 方法传入 LogicalPlan 作为参数,将 strategies 应用 到 LogicalPlan,生成物理计划候选集合(Candidates)。 如果该集合中存在 PlanLater 类型的 SparkPlan,则通过 placeholder 中间变量取 出对应的 Logi ...
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Strategy 体系
一、概述所有的策略都继承自 GenericStrategy 类,其中定义了 planLater 和 apply 方法;SparkStrategy 继承自 GenericStrategy 类,对其中的 planLater 进行了实现,根据传入的 LogicalPlan 直接生成前述提到的 PlanLater 节点 。 此外,在 Spark SQL 中
Strategy 是 SparkStrategy 类的别名
1type Strategy = SparkStrategy
在 Spark SQL中,当逻辑计划处理完毕后,会构造 SparkPlanner 并执行 $plan()$ 方法对 LogicalPlan 进行处理,得到对应的物理计划。一个逻辑计划可能会对应多个物理计划,因此,SparkPlanner 得到的是一个物理计划的列表(Iterator[SparkPlan])。SparkPlanner 继承自 SparkStrategies 类,而 SparkStrategies 类则继承自 QueryPlanner 基类,重要的 $plan()$ 方法实现就在 QueryPlan ...
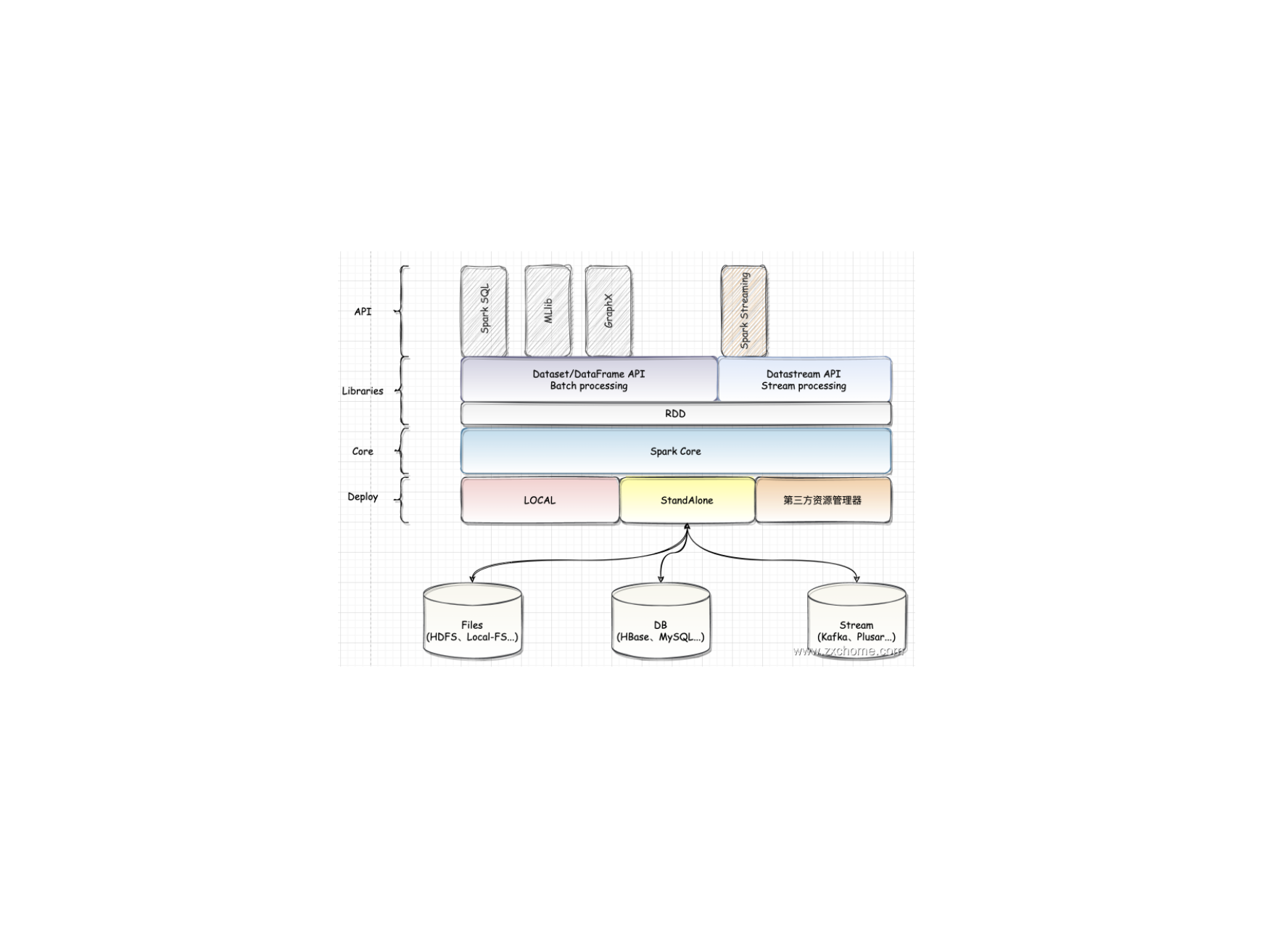
Spark-理论笔记-架构设计
一、概述Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark 是 UC Berkeley AMP lab(加州大学伯克利分校的 AMP 实验室)所开源的类 Hadoop MapReduce 的通用并行框架。
二、模块设计Spark 是一个功能丰富的大数据计算平台,与所有的大型系统一样,Spark 从设计到开发,也根据功能的不同进行模块的拆分。Spark 包含很多子模块,模块按照重要程度可分为核心功能和扩展功能。核心功能是 Spark 设计理念的核心实现,也是 Spark 陆续加入新功能的基础。在核心功能之上,通过不断地将丰富的扩展功能持续集成到 Spark。
2.1. Spark CoreSpark Core 提供了 Spark 最基础与最核心的功能。
2.1.1. 基础服务设施在 Spark 中有很多基础设施,被 Spark 中的各种组件广泛使用。这些基础设施包括 Spark 配置、通信设施、事件总线、度量系统等。
通信服务 RpcEnv
安全服务
对于 Spark 来说,我们需要考虑的三个方面的安全问题
权限管理
保证相应的用户不能做 ...
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Planner 模块
一、概述物理计划阶段是 Spark SQL 整个查询处理流程的最后一步。不同于逻辑计划(LogicalPlan)的平台无关性,物理计划(PhysicalPlan) 是与底层平台紧密相关的。在此阶段,Spark SQL 会对生成的逻辑算子树进行进一步处理,得到物理算子树,并将 LogicalPlan 节点及其所包含的各种信息映射成 Spark Core 计算模型的元素,如 RDD、 Transformation 和 Action 等,以支持其提交执行。
在 SparkSQL 中,物理计划用 SparkPlan 表示,Spark SQL,最终将 SQL 语句经过逻辑算子树转换成物理算子树。在物理算子树中,叶子类型的 SparkPlan 节点负责 “从无到有” 地创建 RDD,每个非叶子类型的 SparkPlan 节点等价于在 RDD 上进行一次 Transformation,即通过调用 $execute$ 函数转换成新的 RDD,最终执行 $collect$ 操作触发计算,返回结果给用户。
二、架构设计Plan 模块主要经过 3 个阶段:
由 SparkPlanner 将各种物理计划 ...
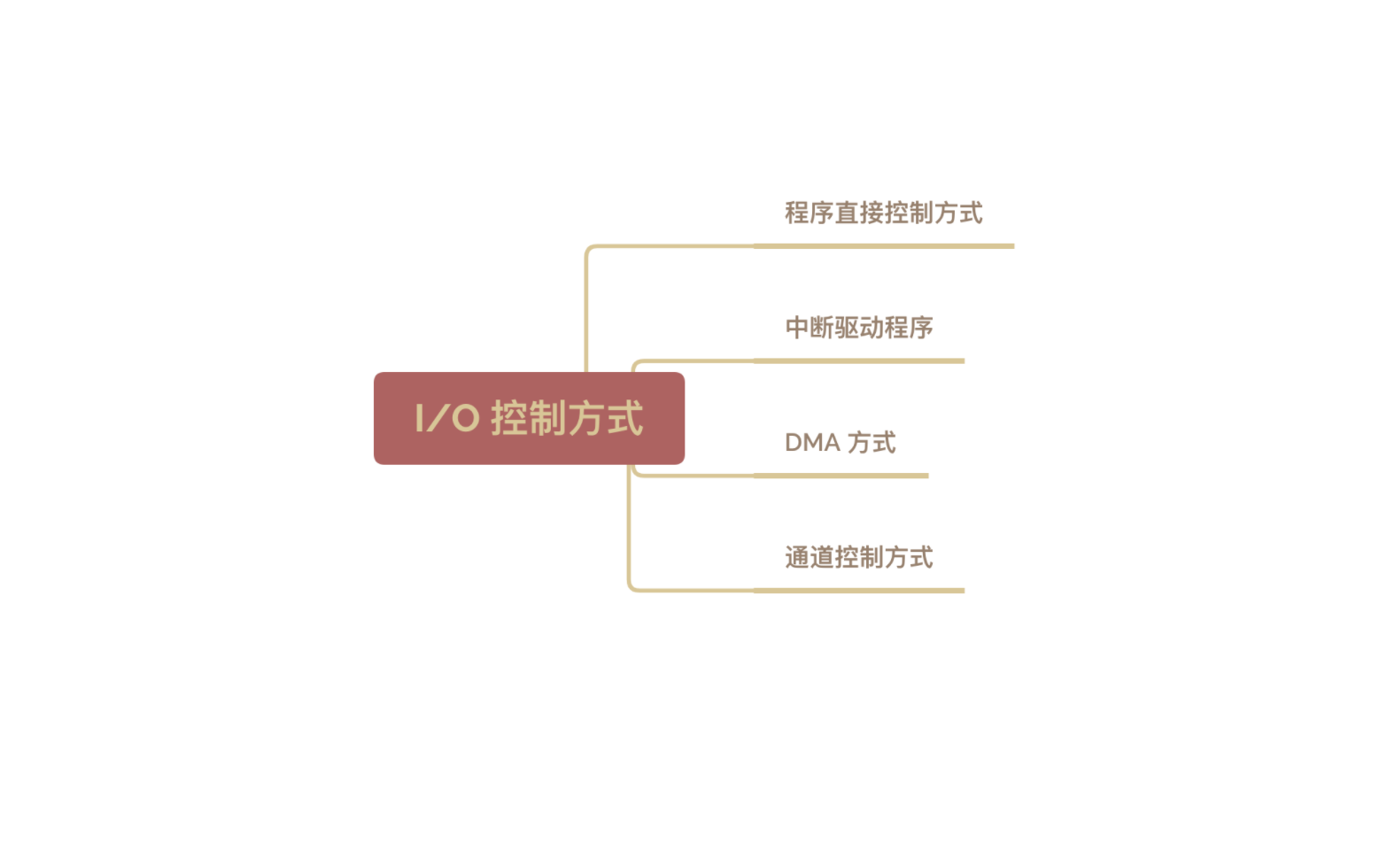
计算机基础-操作系统-IO-控制方式
需要注意的问题:
完成一次读/写操作的流程
CPU 干预的频率
数据传送的单位
数据的流向
主要缺点和优点
1. 程序直接控制
CPU 向控制器发出读指令。于是设备启动,并且状态寄存器设为1(未就绪)
轮询检查控制器的状态(其实就是在不断地执行程序的循环,若状态位一直是1,说明设备还没准备好要输入的数据,于是 CPU会不断地轮询)
输入设备准备好数据后将数据传给控制器,并报告自身状态
控制器将输入的数据放到数据寄存器中,并将状态改为0(已就绪)
CPU 发现设备已就绪,即可将数据寄存器中的内容读入 CPU 的寄存器中,再把 CPU 寄存器中的内容放入内存
1.1. CPU 干预的频率很频繁,I/O 操作开始之前、完成之后需要 CPU 介入,并且在等待 I/O 完成的过程中 CPU 需要不断地轮询检查。
1.2. 数据传送的单位每次读/写一个字
1.3. 数据的流向
读操作(数据输入): I/O设备→CPU(指的是 CPU 寄存器)→内存
写操作(数据输出): 内存→CPU(指的是 CPU 寄存器)→I/O设备
每个字的读/写都需要 CPU 的帮助
1.4. 主要缺点和 ...
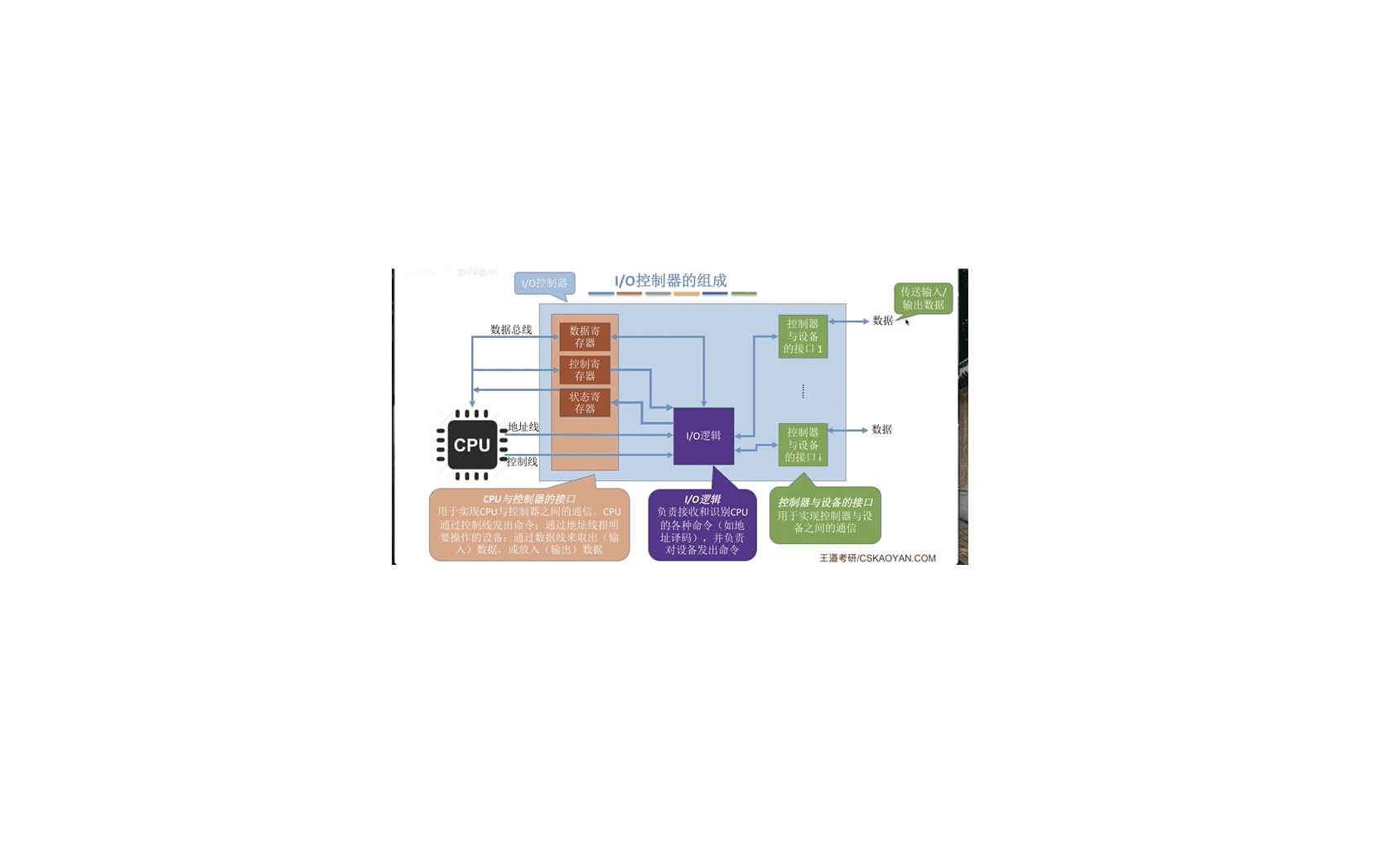
计算机基础-操作系统-IO-控制器
CPU 无法直接控制 IO 设备的机械部件,因此 IO 设备还要有个电子部件作为 CPU 和 IO 设备机械部件之间的”中介”,用于实现 CPU 对设备的控制。这个电子部件就是 IO 控制器,又称为设备控制器。CPU 可控制 IO 控制器,IO 控制器来控制设备的机械部件。
1. IO 控制器功能
接收和识别设备 CPU 指令
CPU 的读写指令和参数存储在控制寄存器中
如 CPU 发来的 read/write 命令,I/O 控制器中会有相应的控制寄存器来存放命令和参数
向 CPU 报告设备的状态
IO 控制器中会有相应的状态寄存器,用于记录 IO 设备的当前状态。(比如 1 代表设备忙碌,0 代表设备就绪)
数据交换
数据寄存器,输出时数据寄存器用来寄存 CPU 发来的数据,之后再由控制器传送设备。输入时,数据寄存器用于暂存设备发来的数据,之后 CPU 从数据寄存器取走数据
地址识别
类似于内存的地址,为了区分设备控制器中的各个寄存器,需要给各个寄存器设置一个特定的地址。IO 控制器通过CPU 提供的地址来判断 CPU 要读写的是哪个寄存器。
2. IO ...
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.















