












Spark-源码系列-SparkCore-Shuffle-外部排序器
一、概述Spark 中的外部排序器用于对 map 任务的输出数据在 map 端或 reduce 端进行排序。
二、实现Spark 中有两个外部排序器,分别是 ExternalSorter 和 ShuffleExternalSorter
2.1. ExternalSorterExternalSorter 是 SortShuffleManager 的底层组件,它提供了很多功能,包括将 map 任务的输出存储到 JVM 的堆中,如果指定了聚合函数,则还会对数据进行聚合;使用分区计算器首先将 Key 分组到各个分区中,然后使用自定义比较器对每个分区中的键进行可选的排序;可以将每个分区输出到单个文件的不同字节范围中,便于 reduce 端的 Shuffle 获取。https://www.zhihu.com/question/264364010/answer/2514170889?utm_id=0
2.1.1. 设计
属性
方法
map 端输出的缓存处理: $insertAll()$
map 任务在执行结束后会将数据写入磁盘,等待 reduce 任务获取。但在写入磁盘之前,Spark 可 ...
Spark-源码系列-SparkCore-Shuffle-排序
一、概述Spark 中的外部排序器用于对 map 任务的输出数据在 map 端或 reduce 端进行排序。
二、实现Spark 中有两个外部排序器,分别是 ExternalSorter 和 ShuffleExternalSorter
2.1. ExternalSorterExternalSorter 是 SortShuffleManager 的底层组件,它提供了很多功能,包括将 map 任务的输出存储到 JVM 的堆中,如果指定了聚合函数,则还会对数据进行聚合;使用分区计算器首先将 Key 分组到各个分区中,然后使用自定义比较器对每个分区中的键进行可选的排序;可以将每个分区输出到单个文件的不同字节范围中,便于 reduce 端的 Shuffle 获取。
2.1.1. 设计
属性
方法
map 端输出的缓存处理: $insertAll()$
map 任务在执行结束后会将数据写入磁盘,等待 reduce 任务获取。但在写入磁盘之前,Spark 可能会对 map 任务的输出在内存中进行一些排序和聚合。ExternalSorter 的 $insertAll()$ 方法是这一过程的入 ...
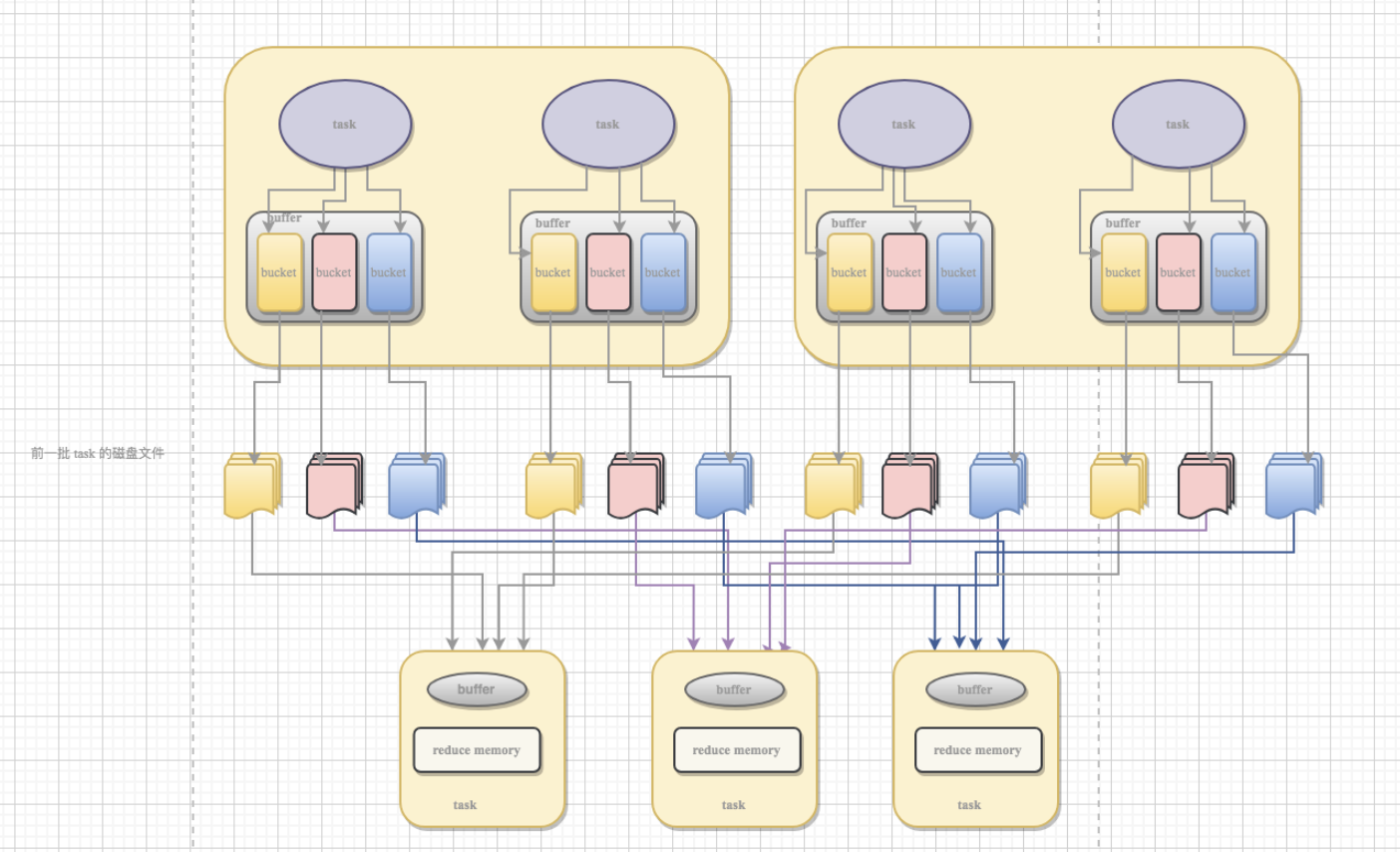
Spark-理论笔记-Shuffle 概述
一、概述Shuffle 描述着数据从 map task 输出到 reduce task 输入的这段过程。是连接 Map 和 Reduce 之间的桥梁, Map 的输出要用到 Reduce 中必须经过 shuffle 这个环节.
shuffle 的性能高低直接影响了整个程序的性能和吞吐量。因为在分布式情况下,reduce task 需要跨节点去拉取其它节点上的 map task 结果。这一过程将会产生网络资源消耗和内存,磁盘 IO 的消耗。
1.1. 导致 Shuffle 操作算子1.1.1. 重分区类的操作重分区类算子一般会 shuffle,因为需要在整个集群中对之前所有的分区的数据进行随机,均匀的打乱,然后把数据放入下游新的指定数量的分区内。
比如 repartition、repartitionAndSortWithinPartitions 等
1.1.2. byKey 类的操作比如 reduceByKey、groupByKey、sortByKey 等,对一个 key 进行聚合操作时要保证集群中,所有节点上相同的 key 分配到同一个节点上进行处理
1.1.3. Join 类的操 ...
Spark-理论笔记-数据倾斜
Spark 中的数据倾斜问题主要指 shuffle 过程中由于不同的 key 对应的数据量不同导致的不同 task 所处理的数据量不同的问题。
1. 表现
Spark 作业的大部分 task 都执行迅速,只有有限的几个 task 执行的非常慢,此时可能出现了数据倾斜,作业可以运行,但是运行的非常慢。
原本能够正常执行的 Spark 作业,突然出现 OOM [内存溢出] 异常
2. 定位数据倾斜在 Spark 中,同一个 Stage 的不同 Partition 可以并行处理,而具有依赖关系的不同 Stage 之间是串行处理的。一个 Stage 所耗费的时间,主要由最慢的那个 Task 决定。由于同一个 Stage 内的所有 Task 执行相同的计算,在排除不同计算节点计算能力差异的前提下,不同 Task 之间耗时的差异主要由该 Task 所处理的数据量决定。Stage 的数据来源主要分为如下两类
从数据源直接读取。如读取 HDFS,Kafka
读取上一个 Stage 的 Shuffle 数据
常用并且可能会触发 shuffle 操作的算子有:distinct,groupByKe ...
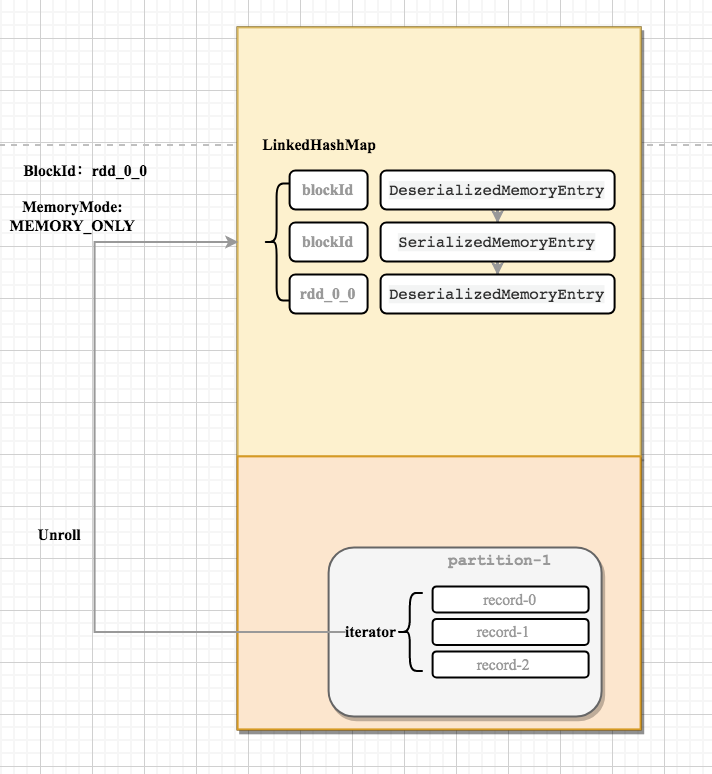
Spark-源码学习-SparkCore-存储服务-架构设计-存储内存
Task 在启动之初读取一个分区时,会先判断这个分区是否已经被持久化,如果没有则需要检查 Checkpoint 或按照血统重新计算。所以如果一个 RDD 要执行多次 action 操作, 可以在第一次 action 操作中使用 persist 或 cache 方法,在内存或磁盘中持久化或缓存这个 RDD,从而在后面的行动时提升计算速度。
弹性分布式数据集 RDD 作为 Spark 最根本的数据抽象,是只读的分区记录的集合,基于在稳定物理存储中的数据集上创建,或者在其他已有的 RDD 上执行转换 [Transformation] 操作产生一个新的 RDD。转换后的 RDD 与 原始的 RDD 之间产生的依赖关系构成了血统[Lineag]。凭借血统,Spark 保证了每一个 RDD 都可以被重新恢复。
其中 cache 这个方法是个 Tranformation ,当第一次遇到 action 算子的时才会进行持久化
cache 内部调用了 persist(StorageLevel.MEMORY_ONLY)方法,所以执行 cache 算子其实就是执行了 persist 算子且持久化级别为 ...
Spark-理论笔记-Join 策略
数据关联总共有 3 种 Join 实现方式。按照出现的时间顺序,分别是嵌套循环连接(NLJ,Nested Loop Join)、排序归并连接(SMJ,Shuffle Sort Merge Join) 和哈希连接(HJ,Hash Join)
1. Join 的实现方式现在有事实表 orders 和维度表 users。其中,users 表存储用户属性信息,orders 记录着用户的每一笔交易。两张表的 Schema 如下:
12345678910// 订单表orders关键字段userId, IntitemId, Intprice, Floatquantity, Int// 用户表users关键字段id, Intname, Stringtype, String //枚举值,分为头部用户和长尾用户
基于两张表做内关联(Inner Join),同时把用户名、单价、交易额等字段投影出来。
123// SQL 查询语句select orders.quantity, orders.price, orders.userId, users.id, users.namefrom orders inn ...
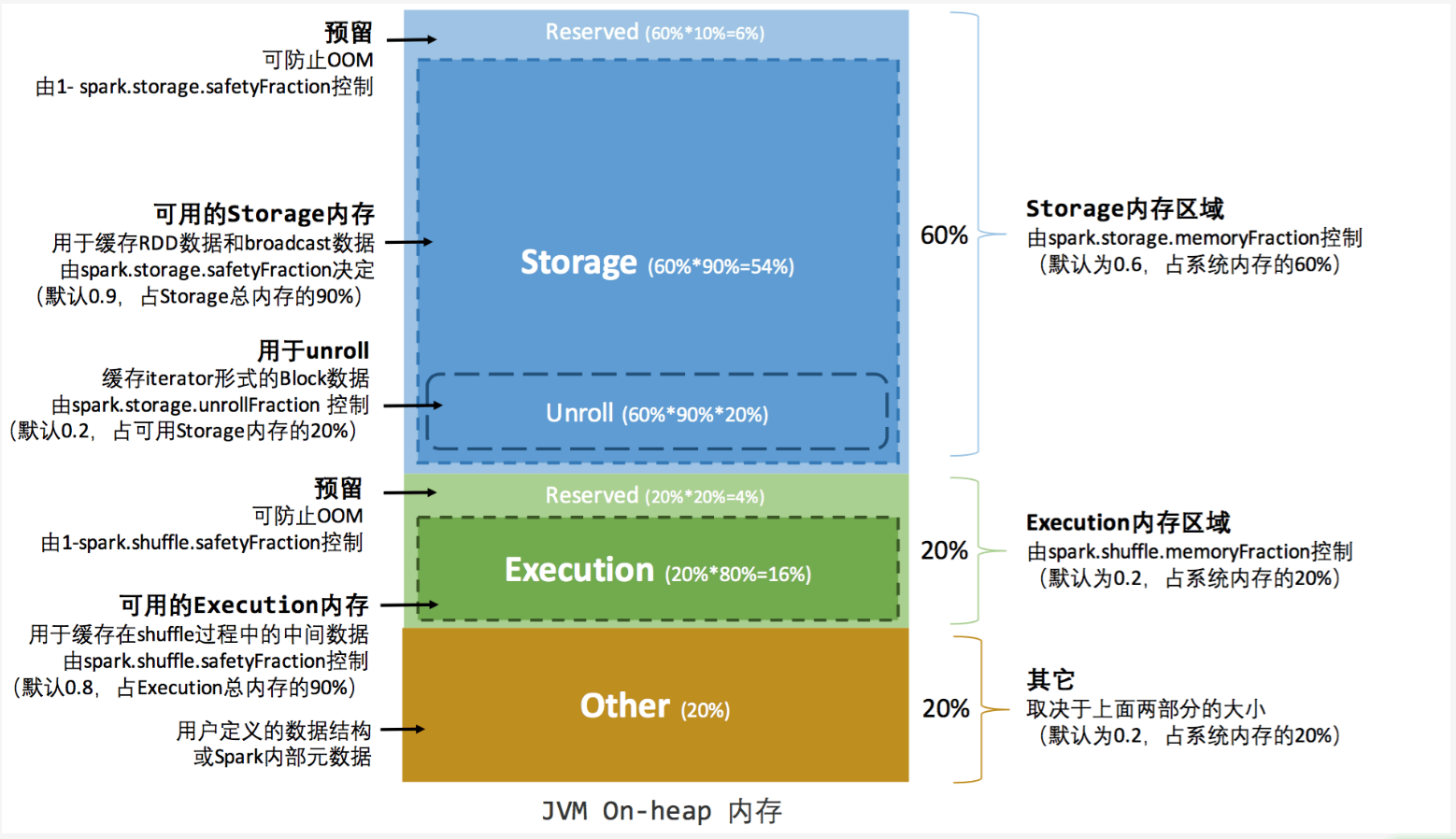
Spark-理论笔记-内存模型
在执行 Spark 的应用程序时,Spark 集群会启动 Driver 和 Executor 两种 JVM 进程,前者为主控进程,负责创建 Spark 上下文,提交 Spark 作业[Job],并将作业转化为计算任务[Task],在各个 Executor 进程间协调任务的调度;后者负责在工作节点上执行具体的计算任务,并将结果返回给 Driver, 同时为需要持久化的 RDD 提供存储功能。
1. Execuor 内存模型1.1. 堆内和堆外内存作为一个 JVM 进程,Executor 的内存管理建立在 JVM 的内存管理之上,Spark 对 JVM 的堆内 [On-heap]空间进行了更为详细的分配,以充分利用内存。
同时,Spark 引入了堆外[Off-heap]内存,使之可以直接在工作节点的系统内存中开辟空间,进一步优化了内存的使用。
堆内内存受到 JVM 统一管理,堆外内存是直接向操作系统进行内存的申请和释放。
1.1.1. 堆内内存堆内内存的大小,由 Spark 应用程序启动时的 –executor-memory 或 spark.executor.memory 参数配置。 ...
Spark-理论笔记-执行内存管理
执行内存主要用来存储任务在执行 Shuffle 时占用的内存,Shuffle 是按照一定规则对 RDD 数据重新分区的过程, Shuffle 的 Write 和 Read 两阶段对执行内存的使用.
执行内存主要用来存储任务在执行 Shuffle 时占用的内存,Shuffle 是按照一定规则对 RDD 数据重新分区的过程, Shuffle 的 Write 和 Read 两阶段对执行内存的使用.
1. ShuffleShuffle Write在 map 端会采用 ExternalSorter 进行外排,在内存中存储数据时主要占用堆内执行空间。
Shuffle Read在 ExternalSorter 和 Aggregator 中, Spark 会使用一种叫 AppendOnlyMap 的哈希表在堆内执行内存中存储数据 但在 Shuffle 过程中所有数据并不能都保存到该哈希表中, 当这个哈希表占用的内存会进行周期性地采样估算,当其大到一定程度, 无法再从 MemoryManager 申请到新的执行内存时, Spark 就会将其全部内容存储到磁盘文件中,这个过程被称为溢存 [Spill] ...
Spark-理论笔记-RDD
RDD(Resilient Distributed Dataset) 叫着 弹性分布式数据集 ,是Spark 中最基本的抽象,它代表一个不可变、可分区、里面元素可以并行计算的集合。
特性
A list of partitions一个分区(Partition)列表,组成了该 RDD 的数据。
这里表示一个 RDD 有很多分区,每一个分区内部是包含了该 RDD 的部分数据,spark 中任务是以 task 线程的方式运行, 一个分区就对应一个 task 线程。
用户可以在创建 RDD 时指定 RDD 的分区个数,如果没有指定,那么就会采用默认值。(比如: 读取HDFS上数据文件产生的RDD分区数跟block的个数相等)
A function for computing each splitSpark 中 RDD 的计算是以分区为单位的,RDD 的每个 partition 上面都会有计算函数
A list of dependencies on other RDDs一个 RDD 会依赖于其他多个 RDD
RDD 与 RDD 之间的依赖关系,spark 任务的容错机制就是根据这个特性而 ...
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.















