











Spark-源码系列-SparkCore-UI
一、概述Spark 任务在运行时,可以借助 SparkUI 对应用程序的 Job、Stage 以及 Executor 等的信息,从而了解整体任务的运行状态。
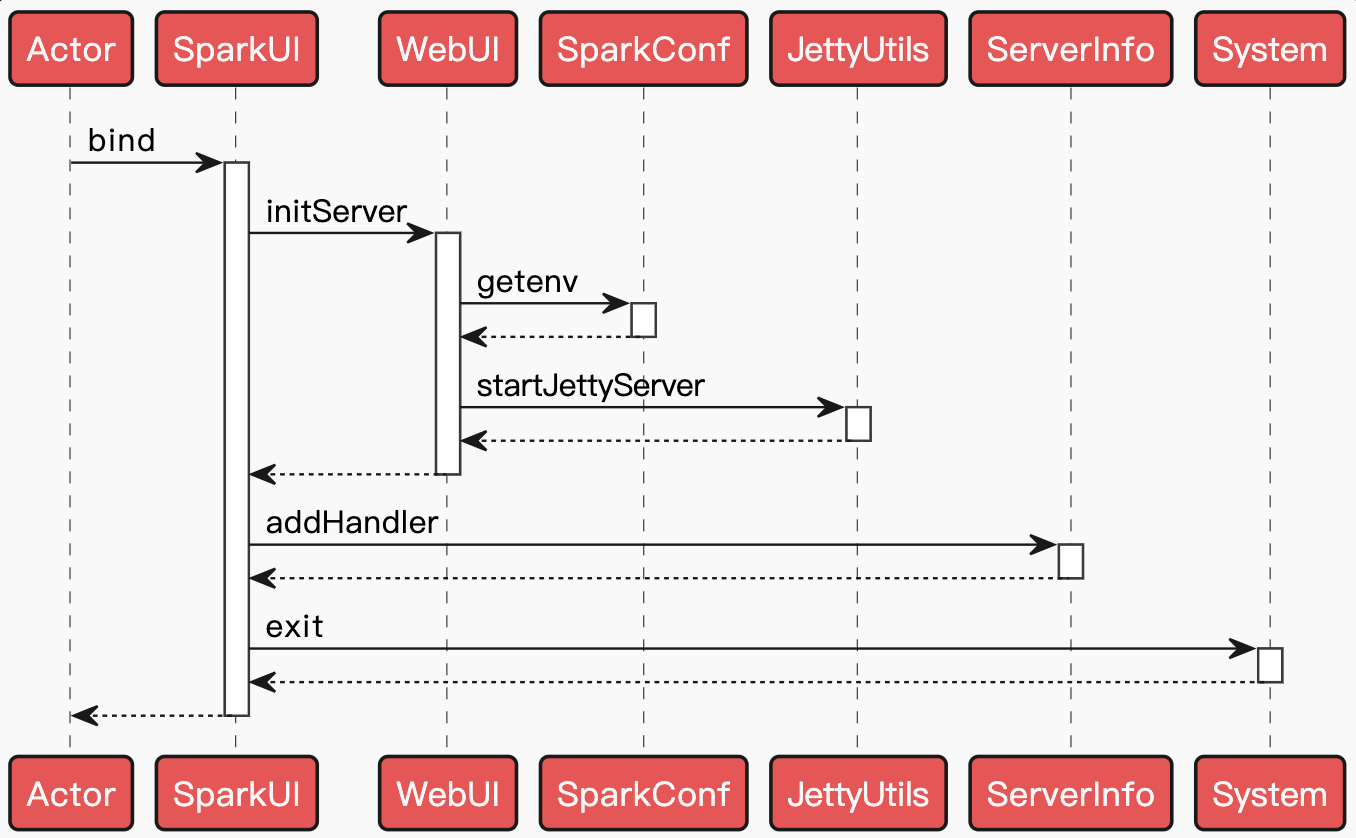
二、实现Spark 提供了 Web 页面来浏览监控数据,而且 Master、Worker、Driver 根据自身功能提供了不同内容的 Web 监控页面。无论是 Master、Worker,还是 Driver,它们都使用了统一的 Web 框架 WebUI。Master、Worker 及 Driver 分别使用 MasterWebUI、WorkerWebUI 及 SparkUI 提供的 Web 界面服务,后三者都继承自 WebUI,并增加了个性化的功能。此外,在 YARN 或 Mesos 模式下还有 WebUI 的另一个扩展实现 HistoryServer。HistoryServer 将会展现已经运行完成的应用程序信息。
2.1. WebUISparkUI 构建在 WebUI 的框架体系之上,凡是需要页面展现的地方都可以继承它来完成。
2.1.1. WebUIPageWeb 界面由多个页面组成,每个页面都将提供不同的内容展示。We ...
Flink-源码学习-FlinkSQL&Table-Table 体系-架构设计
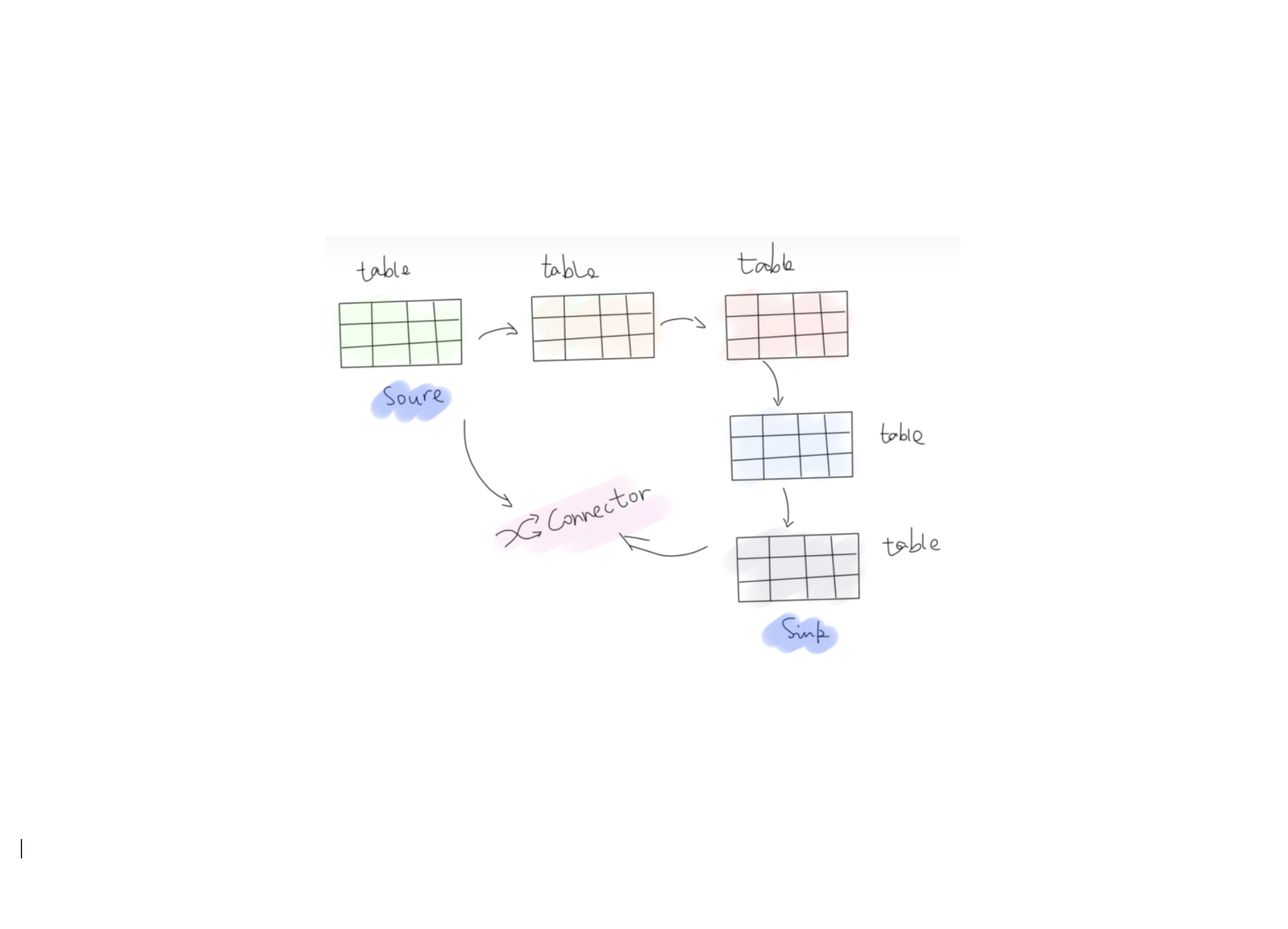
一、概述Table 是 Flink Table API 的核心操作对象,提供了流批统一的数据操作行为定义。对于批处理 Table 是静态表,对于流计算 Table 是动态表。动态表在 Flink 中抽象为 Table 接口。与表示批处理数据的静态表相比,动态表随时间而变化。将 SQL 查询作用于动态表,查询会持续执行而不会终止,叫作连续查询。
以 $Count$ 运算为例,对于静态表而言,$Count$ 是一个确定的值,而连续查询则会随着数据持续进入动态表,持续不断地更新 $Count$ 结果。从这个角度来说,流上的 SQL 实际上给出的总是中间结果。
二、Table SourceTableSource 提供了从外部系统(消息队列,KV 存储,数据库,文件系统等)接入数据,之后洼册到 TableEnvironment 中,然后可以通过 Table API 或者 SQL 进行查询。
引用本站文章
Flink-源码学习-FlinkSQL&Table-Table ...
Spark-源码系列-SparkCore-事件机制
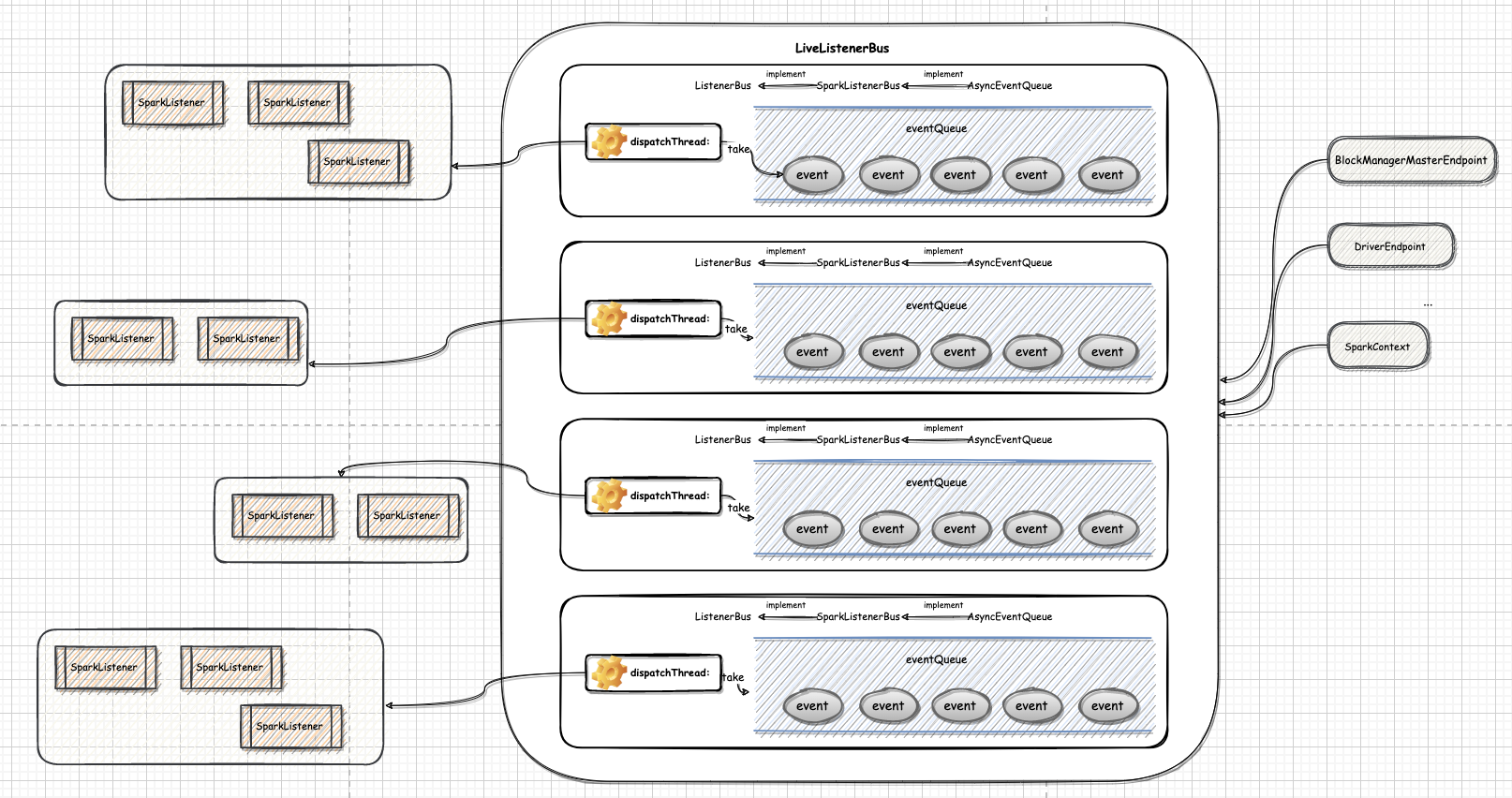
一、概述Spark Core 内部的事件框架实现了基于事件的异步化编程模式。它的最大好处是可以提升应用程序对物理资源的充分利用,能最大限度的压榨物理资源,提升应用程序的处理效率。缺点比较明显,降低了应用程序的可读性。Spark 的基于事件的异步化编程框架由事件框架和异步执行线程池組成,应用程序产生的 Event 发送给 ListenerBus, ListenerBus 再把消息广播给所有的 Listener,每个 Listener 收到 Event 判断是否自己感兴趣的 Event, 若是,会在 Listener 独享的线程池中执行 Event 所对应的逻辑程序。
二、实现Spark 中的事件总线采用监听器模式设计。
2.1. SparkListenerEvent在 Spark 任务运行期间会产生大量包含运行信息的 SparkListenerEvent,例如 ApplicationStart/StageCompleted/MetricsUpdate 等等,都有对应的 SparkListenerEvent 实现。所有的 event 会发送到 ListenerBus 中,被注册在 Li ...

Spark-理论笔记-任务调度机制
在生产环境下, Spark 集群的部署方式一般为 YARN-Cluster 模式,因此本文基于 YARN-Cluster 模式
一、前言1.1. 基本概念首先说明下 Spark 里的几个概念:
一个 Spark 应用程序包括 Job、Stage 以及 Task 三个概念:
Job 是以 Action 方法为界,遇到一个 Action 方法则触发一个 Job
Stage 是 Job 的子集,以宽依赖为界。遇到 Shuffle 做一次划分
Task 是 Stage 的子集,以并行度(分区数)来衡量,分区数是多少,则有多少个 task
二、Spark 调度概述Spark 的任务调度总体来说分两路进行,一路是 Stage 级的调度, 一路是 Task 级的调度,总体调度流程如下图所示:
2.1. Stage 级调度DAGScheduler 负责 Stage 级的调度,将 Job 以宽依赖为界切分成若干 Stages,并将每个 Stage 打包成 TaskSet 交给 TaskScheduler 调度。
DAGScheduler 做的事情较为简单,在 Stage 层面上划分 DAG, ...
Spark-源码系列-SparkCore-Shuffle 设计
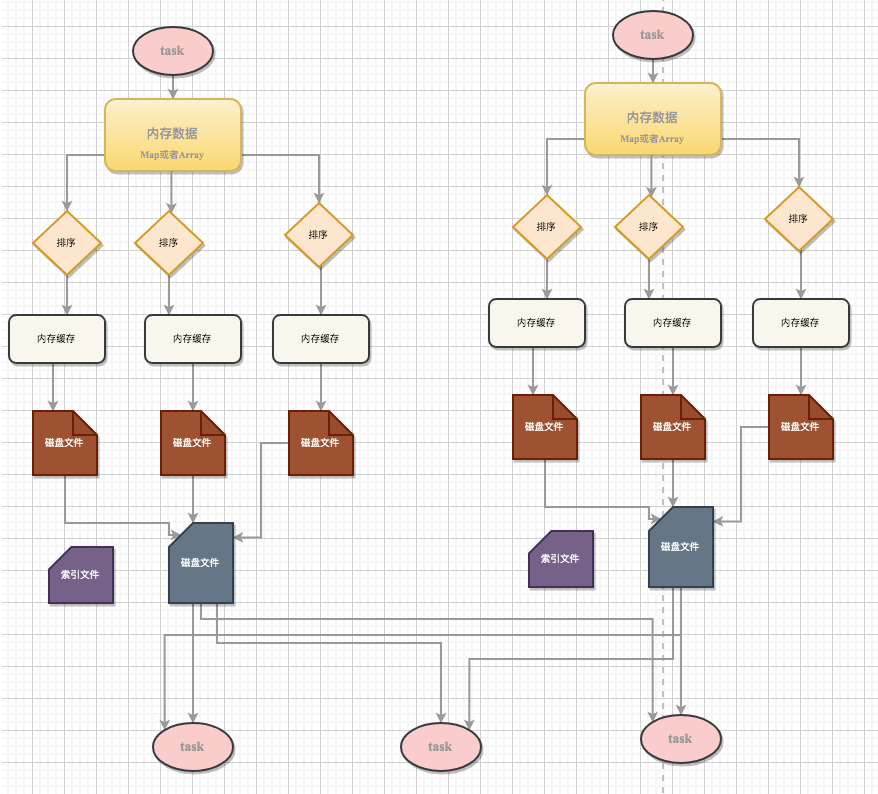
一、概述Spark 在 DAG 调度阶段会将一个 Job 划分为多个 Stage,上游 Stage 做 Map 工作,下游 Stage 做 Reduce 工作,其本质上还是MapReduce 计算框架。Shuffle 是连接 map 和 reduce 之间的桥梁,它将 map 的输出对应到 reduce 输入中,涉及到序列化反序列化、跨节点网络 I/O 以及磁盘读写 I/O 等,Shuffle 的性能高低直接影响了整个程序的性能和吞吐量。
引用本站文章
Spark-理论笔记-Shuffle 概述
Joker
https://mp.weixin.qq.com/s/cf4JUeB-JU0cLgn04ng3og
二、Shuffle 计算2.1. 触发 shuffle2.1.1. 可能导致 shuffle 算子在 Spark 作业中当父 RDD 与子 ...
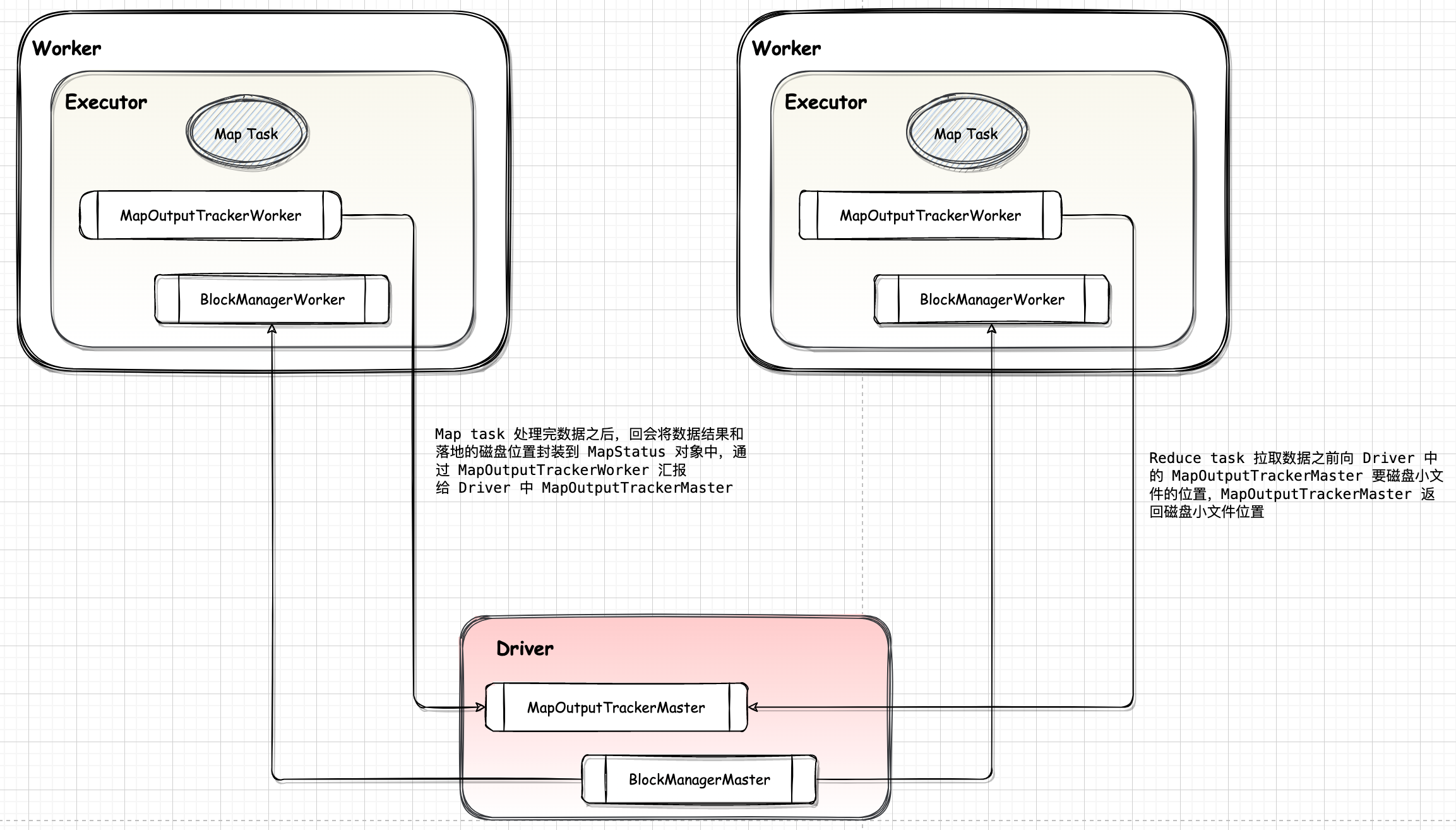
Spark-源码系列-SparkCore-Shuffle-MapOutputTracker
一、概述MapOutputTracker 用于跟踪 Map 任务的输出状态,此状态便于 Reduce 任务定位 Map 任务输出结果所在的节点地址,进而获取中间输出结果。每个Map 任务或者 Reduce 任务都会有其唯一标识,分别为 mapId 和 reduceId。每个 Reduce 任务的输入可能是多个 Map 任务的输出,Reduce 会到各个 Map 任务所在的节点上拉取 Block(Shuffle)。每次 Shuffle 都有唯一的标识 shuffleId。
https://blog.csdn.net/LINBE_blazers/article/details/88919759
二、实现https://segmentfault.com/a/1190000040586936
https://masterwangzx.com/2020/09/22/schedule-mapTrack/#mapoutputtrackermaster
其功能有三方面:
DAGScheduler 使用 MapOutputTrackerMaster 来管理各个 ShuffleMapTask 的输出 ...
Spark-源码系列-SparkCore-Shuffle-MapStatus
一、概述MapStatus 用于表示 ShuffleMapTask 返回给 TaskScheduler 的执行结果
二、设计MapStatus 的伴生对象中定义了 $apply$ 函数,可以直接使用 MapStatus(BlockManagerId, partitionLengths) 创建 MapStatus 实例。
1234567def apply(loc: BlockManagerId, uncompressedSizes: Array[Long], mapTaskId: Long): MapStatus = { if (uncompressedSizes.length > minPartitionsToUseHighlyCompressMapStatus) { HighlyCompressedMapStatus(loc, uncompressedSizes, mapTaskId) } else { new CompressedMapStatus(loc, uncompressedSizes, mapTaskId) ...
Spark-源码系列-SparkCore-Shuffle-Shuffle 管理器-ShuffleReader-BlockStoreShuffleReader
一、概述https://blog.csdn.net/u011239443/article/details/56843264
ShuffleReader 实现了下游 Task 如何读取上游 ShuffleMapTask的Shuffle 输出的逻辑,通过 MapOutputTracker 获得数据的位置信息,如果数据在本地则调用BlockManager 的 $getBlockData()$ 读取本地数据。
Shuffle Read 的整体架构如图所示:
$ShuffledRDD.compute()$ 开始~
1234567override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = { val dep = dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]] val metrics = context.taskMetrics().createTempShuffleReadMetrics() SparkEnv. ...
Spark-源码系列-SparkCore-Shuffle-Shuffle 管理器-ShuffleWriter
一、概述ShuffleWriter 负责将 Map 任务的输出,写出到 Shuffle 系统的文件中。在基于排序的 Shuffle 框架中,ShuffleWriter 会合并文件,它为每个 Map Task生成一个数据文件和一个索引文件。
https://blog.51cto.com/u_15067227/2573455
https://blog.csdn.net/Christopher_L1n/article/details/122903200
二、实现抽象类 ShuffleWriter 定义了将 map 任务的中间结果输出到磁盘上的功能规范,包括将数据写入磁盘和关闭 ShuffleWriter。
ShuffleWriter 定义的 $write()$ 方法用于将 map 任务的结果写到磁盘,而 $stop()$ 方法可以关闭 ShuffleWriter。ShuffleWriter一共有三个子类,分别为SortShuffleWriter、UnsafeShuffleWriter 及 BypassMergeSortShuffleWriter。
https://weread ...
Spark-源码系列-SparkCore-Shuffle-Shuffle 管理器-SortShuffleManager
一、概述SortShuffleManager 管理基于排序的 Shuffle,输入的记录按照目标分区 ID 排序,然后输出到一个单独的 map 输出文件中。reduce 为了读出 map 输出,需要获取 map 输出文件的连续内容。当 map 的输出数据太大已经不适合放在内存中时,排序后的输出子集将被溢出到文件中,这些磁盘上的文件将被合并生成最终的输出文件。
二、注册 ShuffleDriver 和每个 Executor 都会持有一个 ShuffleManager,这个 ShuffleManager 可以通过配置项 spark.shuffle.manager 指定,并且由 SparkEnv 创建。Driver 中的 ShuffleManager 负责注册 Shuffle 的元数据,比如 shuffleId、MapTask 的数量等。Executor 中的 ShuffleManager 则负责读和写 Shuffle 的数据。
三、获取 ShuffleWriterShuffleWriter 负责将 Map 任务的输出,写出到 Shuffle 系统的文件中。在基于排序的 Shuffle ...
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.















