












Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Analyzer 模块-Rule-Resolution-ResolveReferences
一、概述表达式一般指的是不需要触发执行引擎而能够直接进行计算的单元,例如加减乘除四则运算、逻辑操作、转换操作、过滤操作等。
二、实现Catalyst 实现了完善的表达式体系,与各种算子(QueryPlan)占据同样的地位。算子执行前通常都会进行”绑定”操作,将表达式与输入的属性对应起来,同时算子也能够调用各种表达式处理相应的逻辑。
在 Expression 类中,主要定义了5个方面的操作,包括基本属性、核心操作、输入输出、字符串表示和等价性判断
核心操作 eval 函数实现了表达式对应的处理逻辑,也是其他模块调用该表达式的主要接口,而 genCode 和 doGenCode 用于生成表达式对应的 Java 代码。字符串表示用于查看该 Expression 的具体内容,如表达式名和输入参数等。
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Analyzer 模块-Rule-Resolution-ResolveRelations
一、概述表达式一般指的是不需要触发执行引擎而能够直接进行计算的单元,例如加减乘除四则运算、逻辑操作、转换操作、过滤操作等。
二、实现Catalyst 实现了完善的表达式体系,与各种算子(QueryPlan)占据同样的地位。算子执行前通常都会进行”绑定”操作,将表达式与输入的属性对应起来,同时算子也能够调用各种表达式处理相应的逻辑。
在 Expression 类中,主要定义了5个方面的操作,包括基本属性、核心操作、输入输出、字符串表示和等价性判断
核心操作 eval 函数实现了表达式对应的处理逻辑,也是其他模块调用该表达式的主要接口,而 genCode 和 doGenCode 用于生成表达式对应的 Java 代码。字符串表示用于查看该 Expression 的具体内容,如表达式名和输入参数等。
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Analyzer 模块-Rule-Resolution-ResolveUpCast
一、概述表达式一般指的是不需要触发执行引擎而能够直接进行计算的单元,例如加减乘除四则运算、逻辑操作、转换操作、过滤操作等。
二、实现Catalyst 实现了完善的表达式体系,与各种算子(QueryPlan)占据同样的地位。算子执行前通常都会进行”绑定”操作,将表达式与输入的属性对应起来,同时算子也能够调用各种表达式处理相应的逻辑。
在 Expression 类中,主要定义了5个方面的操作,包括基本属性、核心操作、输入输出、字符串表示和等价性判断
核心操作 eval 函数实现了表达式对应的处理逻辑,也是其他模块调用该表达式的主要接口,而 genCode 和 doGenCode 用于生成表达式对应的 Java 代码。字符串表示用于查看该 Expression 的具体内容,如表达式名和输入参数等。
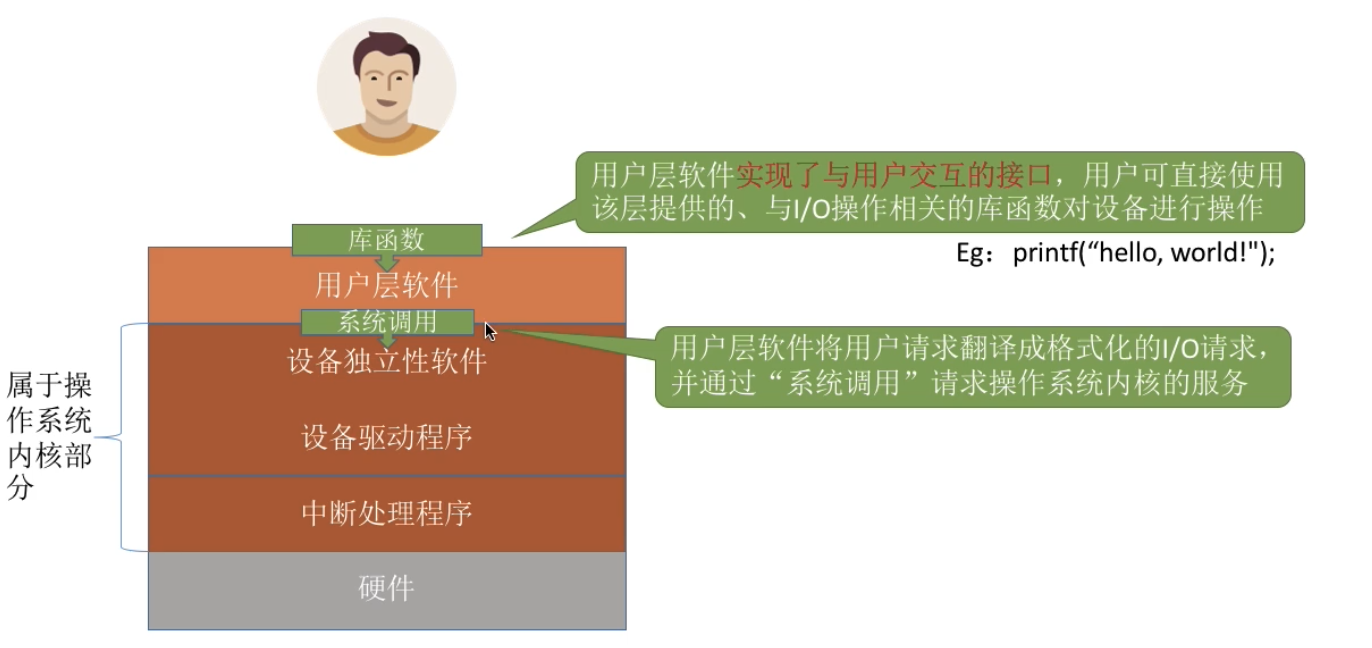
计算机基础-操作系统-IO-软件层次结构
1. 用户层软件用户层软件实现了与用户交互的接口,用户可直接使用该层提供的、与 I/O 操作相关的库函数对设备进行操作
用户层软件将用户请求翻译成格式化的 I/O 请求,并通过“系统调用”请求操作系统内核的服务
printf(“hello, world!”);会被翻译成等价的 write 系统调用,当然,用户层软件也会在系统调用时填入相应参数。
Windows 操作系统向外提供的一系列系统调用,但是由于系统调用的格式严格,使用麻顺,因此在用户层上封装了一系列更方便的库函数按口供用户使用(Windows Api)
2. 设备独立性软件设备独立性软件,又称设备无关性软件。与设备的硬件特性无关的功能几乎都在这一层实现
向上层提供统一的调用接口(如 read/write 系统调用)
设备的保护
原理类似与文件保护。设备被看做是一种特殊的文件,不同用户对各个文件的访问权限是不一样的,同理,对设备的访问权限也不一样。
差错处理
设备独立性软件需要对一些设备的错误进行处理
设备的分配与回收
数据缓冲区管理
可以通过缓冲技术屏蔽设备之间数据交换单位大小和传输速度的差 ...
Spark-源码系列-SparkCore-Shuffle 设计-内存管理-MemoryConsumer
一、概述在 Spark 中,使用抽象类 MemoryConsumer 来表示需要使用内存的消费者。在这个类中定义了分配,释放以及 Spill 内存数据到磁盘的一些方法或者接口。具体的消费者可以继承 MemoryConsumer 从而实现具体的行为。因此,在 Spark Task 执行过程中,会有各种类型不同,数量不一的具体消费者。如在 Spark Shuffle 中使用的 ExternalAppendOnlyMap, ExternalSorter 等。
Spark-源码系列-SparkCore-Shuffle 设计-内存管理-TaskMemoryManager
一、概述TaskiMemoryManger 负责管理单个任务的堆外执行内存和堆内执行内存,Spark 中 Task 的执行内存是通过 TaskMemoryManger 统一管理的,不论是 ShuffleMapTask 还是 ResultTask, Spark 都会生成一个专用的 TaskMemoryManger 对象,然后通过 TaskContext 将 TaskMeroryManger 对象共享给该 task attempt 的所有 MemoryConsumer。 TaskMemoryManger 自建了一套内存页管理机制,并统一对 ON_HEAP 和 OFF_HEAP 内存进行编址,分配和释放。
https://blog.csdn.net/lidongmeng0213/article/details/108865063
https://www.jianshu.com/p/1176b8c637d5
二、内存页管理模块TaskMemoryManger 实现了一套类似于操作系统内存页管理的机制。
2.1. MemoryLocation为了统一 ON_HEAP 和 OFF_HEAP ...
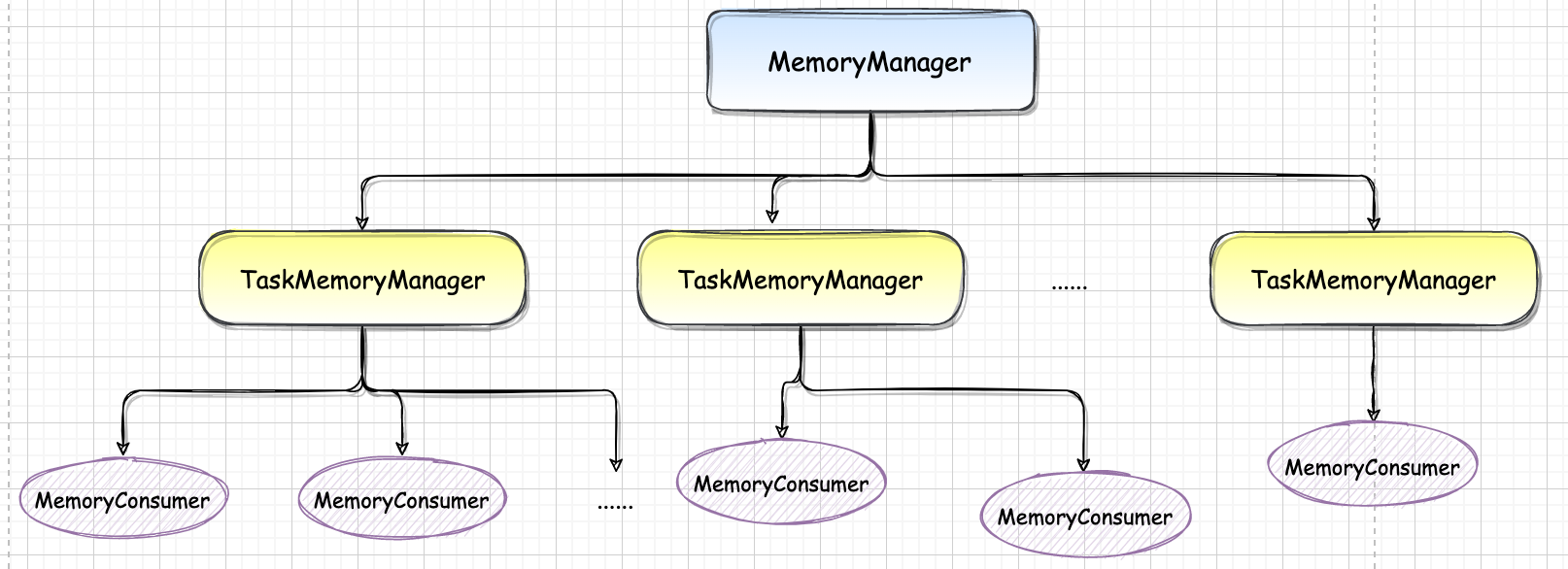
Spark-源码系列-SparkCore-Shuffle 设计-内存管理
一、概述Map 任务在执行结束后会将数据写入磁盘,等待 reduce 任务获取。但在写入磁盘之前,Spark 可能会对 map 任务的输出在内存中进行一些排序和聚合
二、内存空间管理Spark 内存管理组件包括 JVM 范围内的内存管理 MemoryManager 和单个任务的内存管理 TaskMemoryManager。MemoryManager, TaskMemoryManager 和 MemoryConsumer 之前的对应关系,如下图。总体上一个 MemoryManager 对应着至少一个 TagrMemoryManager (具体由 executor-core 参数指定),而一个 TaskMemoryManager 对应着多个 MemoryConsumer(具体由任务而定)。当有多个 Task 同时在 Executor 上执行时,将会有多个 TaskMemoryManager 共享 MemoryManager 管理的内存。
https://mp.weixin.qq.com/s/QGlZTUWdst5I_aA7NBJjoA
https://baijiahao.baidu.c ...
Spark-源码系列-SparkCore-Shuffle-内存管理-采样和估算
一、概述由于 AppendOnlyMap 存放的是 Key 和 Value 的引⽤,并不是它们的实际对象⼤⼩,⽽且 Value 会不断被更新,实际⼤⼩不断变化。因此,想准确得到AppendOnlyMap 的⼤⼩⽐较困难。⼀种简单的解决⽅法是在每次插⼊ record 或对现有 record 的 Value 进⾏更新后,都扫描⼀下 AppendOnlyMap 中存放的 record,计算每个 record 的实际对象⼤⼩并相加,但这样会⾮常耗时。⽽且⼀般 AppendOnlyMap 会插⼊⼏万甚⾄⼏百万个 record,如果每个 record 进⼊ AppendOnlyMap 都计算⼀遍,开销会很⼤。
Spark 设计了⼀个增量式的⾼效估算算法,在每个 record 插⼊或更新时根据历史统计值和当前变化量直接估算当前 AppendOnlyMap 的⼤⼩,算法复杂度是 O(1),开销很⼩: 在 record 插⼊和聚合过程中会定期对当前 AppendOnlyMap 中的 record 进⾏抽样,然后精确计算这些 record 的总⼤⼩、总个数、更新个数及平均值等,并作为历史统计值,每当有 ...
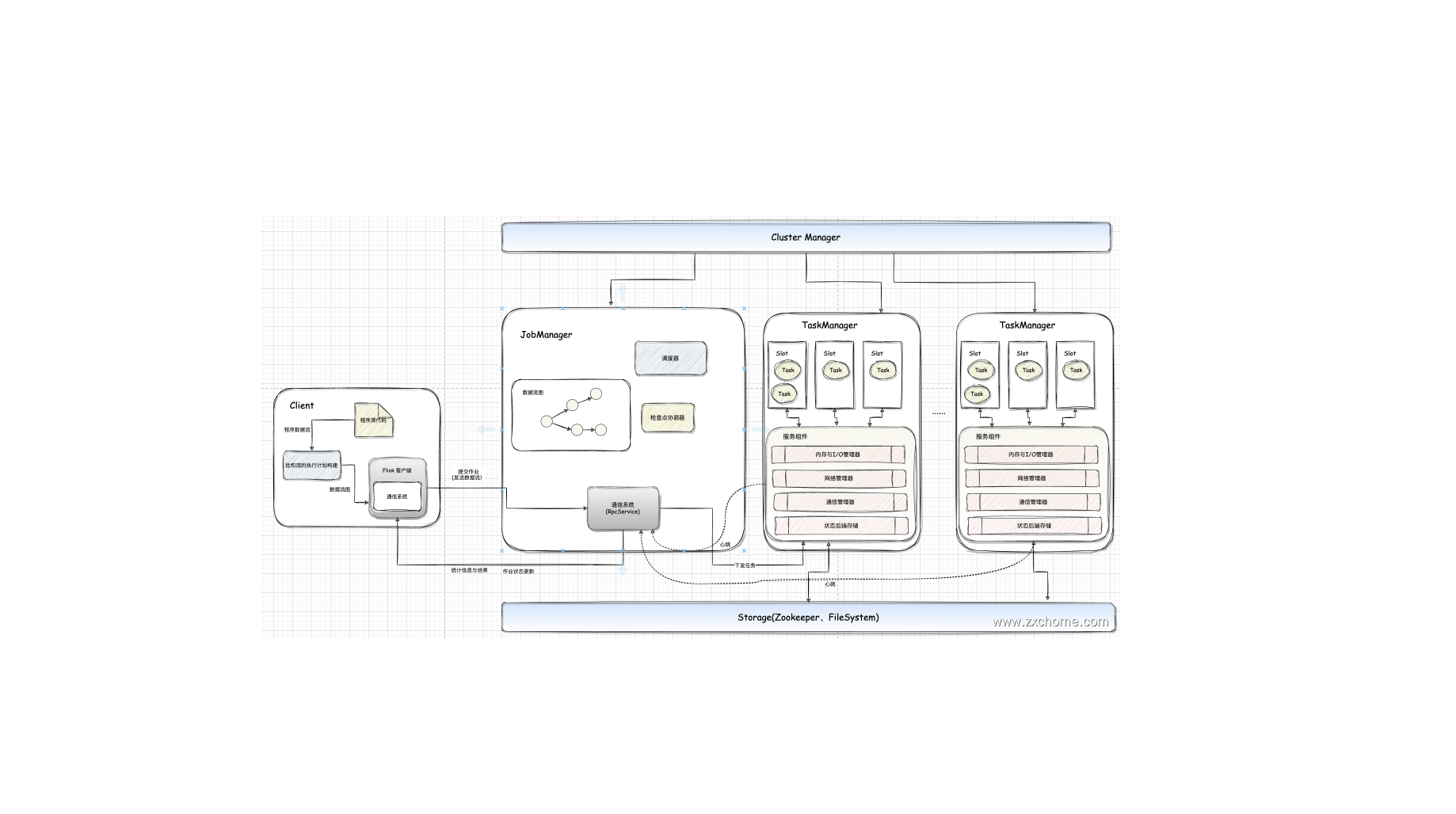
Flink-源码学习-架构设计
一、概述Flink 是一个批流一体的分布式计算引擎,作为一个分布式计算引擎,必须提供面向开发人员的 API,根据业务逻辑开发 Flink 作业,作业除了包含业务逻辑外,还需要跟外部的数据存储进行交互。作业开发、测试完华后,交给 Flink 集群进行执行,同时还要让运维人员能够管理与监控 Flink。
二、集群组件Flink 采用 Master-Slave 架构,其中 JobManager 作为集群 Master 节点,主要负责任务协调和资源分配,TaskManager 作为 slave 节点,用于执行任务。
2.1. JobManagerJobManager 相当于整个集群的 Master 节点,且整个集群有且只有一个活跃的 JobManager(在高可用场景下,可能会出现多个 JobManager;这时只有一个是正在活跃的领导 Leader 节点,其他都是 Standby 节点)。
负责整个集群的任务调度和资源管理。从客户端中获取提交的 Flink Job,然后根据集群中 TaskManager 上 TaskSlot 的使用情况,为提交的 Job 分配相应的 Tasksl ...
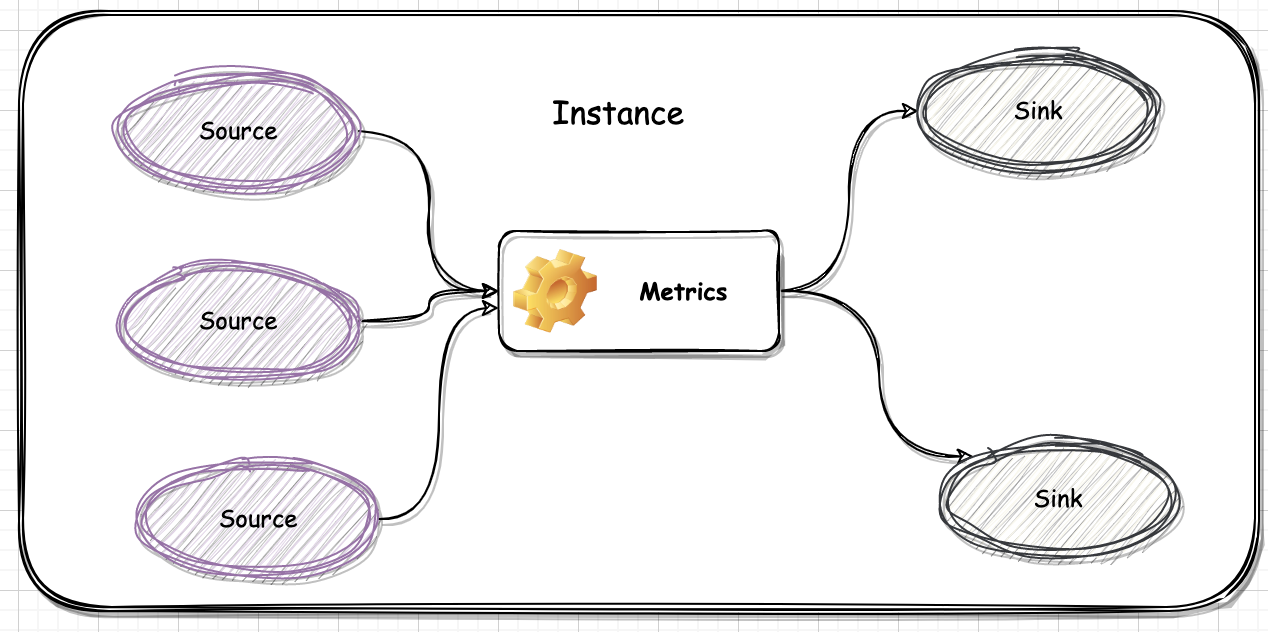
Spark-源码系列-SparkCore-度量系统
一、概述Spark 的度量系统是由 Instance、Source(度量来源)、Metrics、Sink(度量目的地,每个 instance 可以设置一个或多个 Sink) 四个部分组成
二、实现2.1. MetricsSystemMetricsSystem 是 Spark 度量系统的中枢大脑,底层使用的是第三方的库 Metrics,MetricsSystem 里面维护了一个 MetricRegistry 的实例,Source 和 Sink 的都是通过这个 MetricRegistry 注册的。整体上 Spark 中的 MetricsSystem 就是基于 Metrics 做了一层封装~
2.1.1. 初始化MeticsSystem 的初始化是在 SparkEnv 创建的过程中创建的~
12345678val metricsSystem = if (isDriver) { MetricsSystem.createMetricsSystem(MetricsSystemInstances.DRIVER, conf)} else { conf.set ...
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.















