











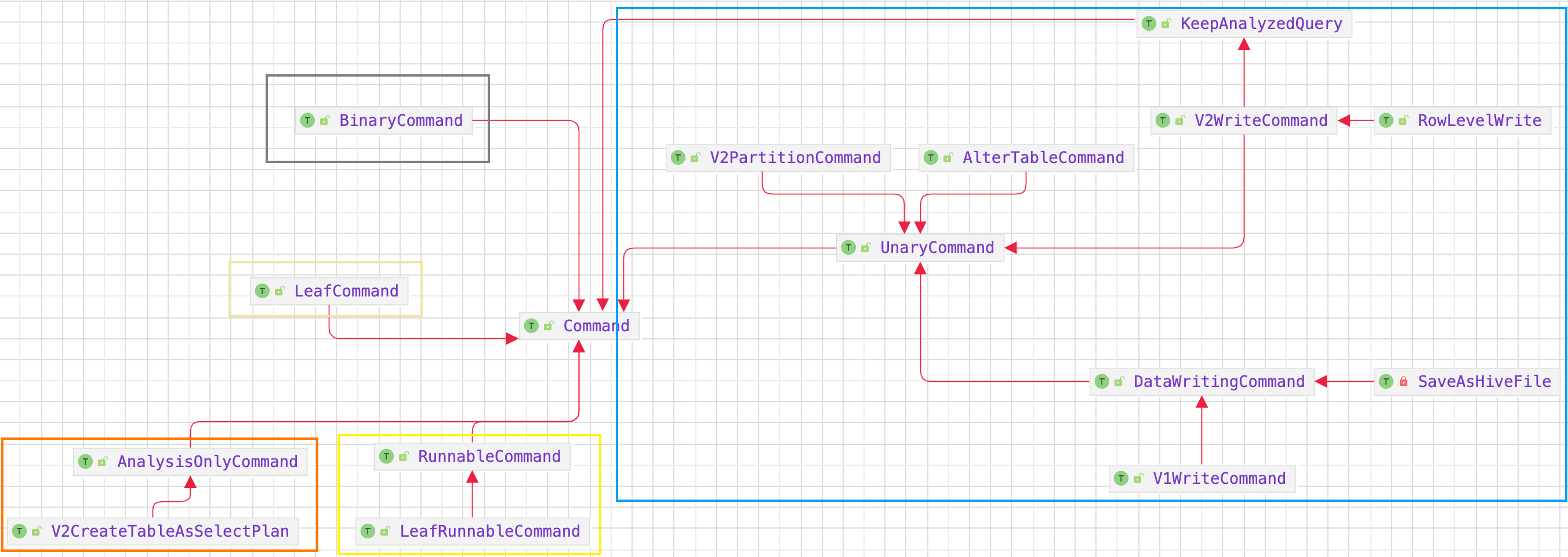
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-数据结构-TreeNode-QueryPlan-LogicalPlan-Command 体系
一、概述Spark SQL command 主要指的是一些 non-query 逻辑计划。
二、设计
2.1. AnalysisOnlyCommand仅解析(analyzed) 子节点,不优化 (optimized) 子节点的命令。
HandleSpecialCommand 处理完成 analysis 时需要通知的特殊命令的规则。
HandleSpecialCommand 规则应在所有其他分析规则运行后运行。
12345678object HandleSpecialCommand extends Rule[LogicalPlan] { override def apply(plan: LogicalPlan): LogicalPlan = plan.resolveOperatorsWithPruning(_.containsPattern(COMMAND)) { case c: AnalysisOnlyCommand if c.resolved => checkAnalysis(c) c.markAsAnalyzed(A ...

Spark-源码学习-SparkSQL-架构设计-SQL 引擎-数据结构-TreeNode-QueryPlan-SparkPlan
一、概述Spark SQL 最终将 SQL 语句经过逻辑算子树转换成物理算子树。在物理算子树中,叶子类型的 SparkPlan 节点负责 “从无到有” 地创建 RDD,每个非叶子类型的 SparkPlan 节点等价于在RDD 上进行一次 Transformation,即通过调用 execute() 函数转换成新的 RDD,最终执行 collect() 操作触发计算,返回结果给用户。SparkPlan 在对 RDD 做 Transformation 的过程中除对数据进行操作外,还可能对 RDD 的分区做调整。此外,SparkPlan 除实现 execute 方法外,还有一种情况是直接执行 executeBroadcast 方法,将数据广播到集群上。
二、模块具体来看,SparkPlan 的主要功能可以划分为 3 大块。首先,每个 SparkPlan 会记录其元数据(Metadata) 与指标(Metric)信息,这些信息以 Key-Value 的形式保存在 Map 数据结构中,统称为 SparkPlan 的 Metadata 与 Metric 体系。其次,在对 RDD 进行 Tran ...
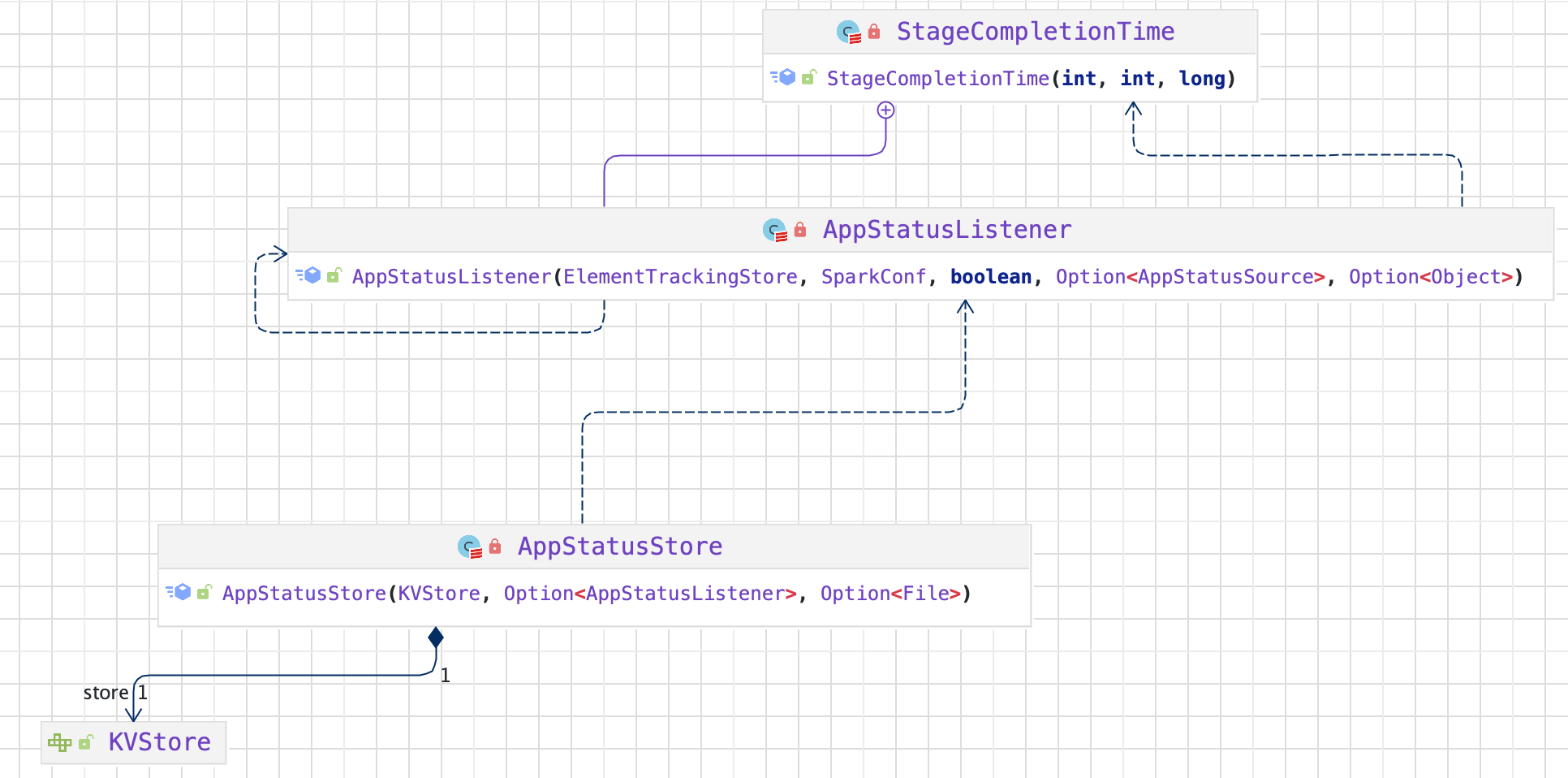
Spark-源码学习-SparkCore-AppStatusStore
一、概述AppStatusStore 用来存储 Application 的状态数据,Spark Web UI 及 REST API 需要的数据都取自它。
二、设计AppStatusStore 的构造依赖于两个要素: 一为键值对存储 KVStore,二为 App 状态监听器 AppStatusListener
2.1. KVStoreInMemoryStore 是在内存中维护的键值对存储;LevelDB 则是借助 Google 开源的 KV 数据库来实现,可以持久化到磁盘。ElementTrackingStore 额外加上了跟踪元素个数的功能,可以根据元素个数阈值触发特定的操作,但它更多地是个包装类,需要依赖于 InMemoryStore 或者 LevelDB。
2.1.1. ElementTrackingStoreElementTrackingStore 的初始化依赖于 InMemoryStore,它的多数方法都是直接代理了 InMemoryStore 的方法。为了实现跟踪元素数并触发操作的功能,其内部维护了一个类型与触发器(通过内部样例类 Trigger 定义)的映射关系, ...
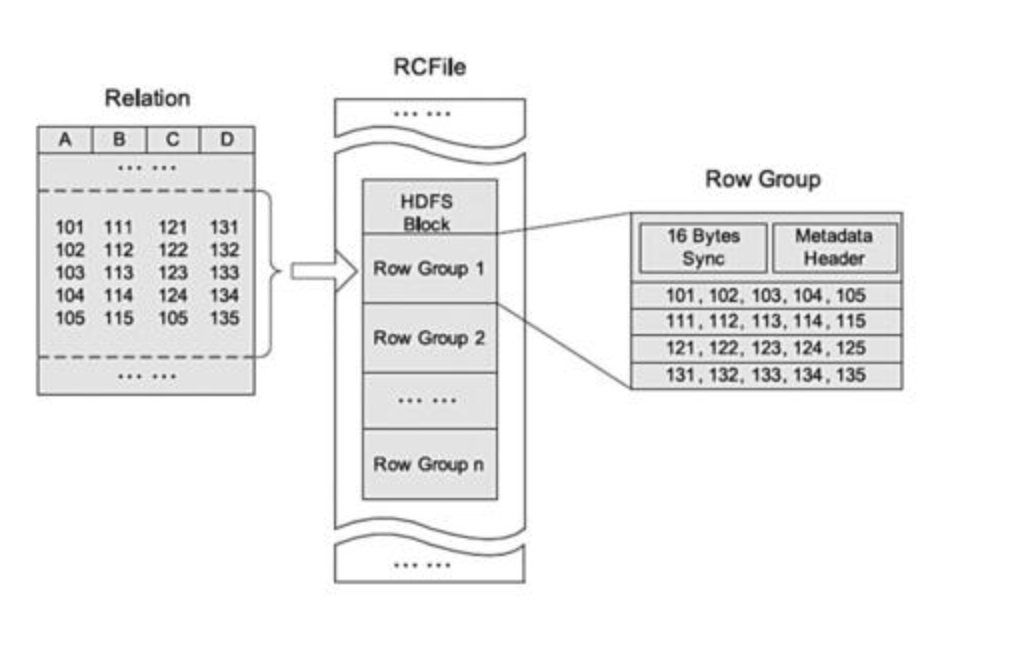
大数据-存储格式-OrcFile
一、概述二、RCFile(Record Columnar File)2.1. File FormatRCFile 基于 HDFS 架构,存储在一个 HDFS 块中的所有记录被划分为多个行组。
对于一张表,所有行组大小都相同。一个行组包括三个部分。第一部分是行组的头部标识,主要用于分隔 HDFS 块中的两个连续行组;第二部分是行组的元数据头部,用于存储行组单元的信息,包括行组中的记录数、每个列的字节数、列中每个域的字节数;第三部分是数据段,即实际的列存储数据。在该部分中,同一列的所有域顺序存储。
RCFile 由于相同的列都是在一个 HDFS 块上,所以相对列存储而言会节省很多资源。
一种行列存储相结合的存储方式。首先,其将表数据分为几个行组,对每个行组内的数据按列存储,先水平划分,再垂直划分的理念。它结合了行存储和列存储的优点,保证同一行的数据位于同一节点,并且像列存储一样,RCFile 能够利用列维度的数据压缩,跳过不必要的列读取。
RCFile 具备相当于行存储的数据加载速度和负载适应能力;其次,RCFile 的读优化可以在扫描表格时避免不必要的列读取
2.2. 存储空间 ...
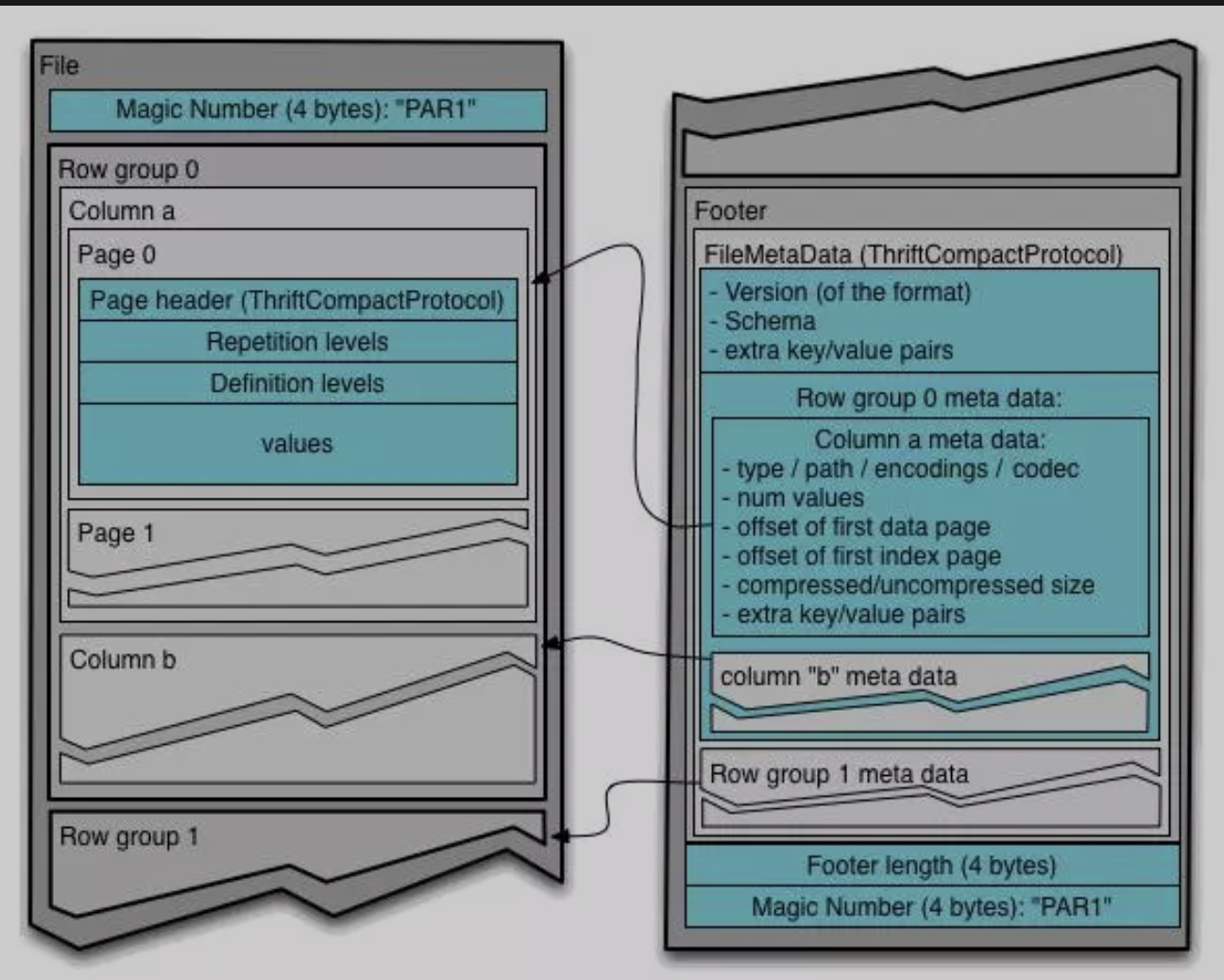
大数据-存储格式-Parquet
http://httao.cn/archives/shen-ru-pou-xi-parquet-wen-jian
https://mp.weixin.qq.com/s/NNsdqm2qGTuzagGFjFWgrA
https://blog.csdn.net/weixin_45626756/article/details/127030007
一、概述Apache Parquet 是由 Twitter 和 Cloudera 最先发起并合作开发的列存项目,也是 2010 年 Google 发表的 Dremel 论文中描述的内部列存格式的开源实现。和一些传统的列式存储系统相比,Dremel/Parquet 最大的贡献是支持嵌套格式数据的列式存储。嵌套格式可以很自然的描述互联网和科学计算等领域的数据,Dremel/Parquet 原生的支持嵌套格式数据减少了规则化、重新组合这些大规模数据的代价。
Parquet 的设计与计算框架、数据模型以及编程语言无关,可以与任意项目集成,因此应用广泛。目前已经是 Hadoop 大数据生态圈列式存储的事实标准。
1.1. 列式存储列式存储,按列进行存储数据 ...
Spark-源码系列-SparkCore-Shuffle-Shuffle 管理器-ShuffleReader-ShuffleBlockFetcherIterator
一、概述数据块的迭代器 ShuffleBlockFetcherIterator 可以从本地或远端获取数据块,本地数据块通过 BlockManager 对象进行获取;远端数据块通过数据块传输服务:BlockTransferService 服务来获取。
二、设计2.1. 结构2.1.1. 属性三、初始化ShuffleBlockFetcherIterator 是读取中间结果的关键。初始化 ShuffleBlockFetcherIterator 的时候会调用到 $initialize()$ 方法~
3.1. 划分本地与远程 Block$partitionBlocksByFetchMode()$ 方法用于划分哪些 Block 从本地获取,哪些需要远程拉取。
12val remoteRequests = partitionBlocksByFetchMode( blocksByAddress, localBlocks, hostLocalBlocksByExecutor, pushMergedLocalBlocks)
3.2. 将 FetchRequest 随机排序存入1fetchR ...
Spark-源码系列-SparkCore-Shuffle-ShuffleRead-ShuffleBlockFetcherIterator
一、概述数据块的迭代器 ShuffleBlockFetcherIterator 可以从本地或远端获取数据块,本地数据块通过 BlockManager 对象进行获取;远端数据块通过数据块传输服务:BlockTransferService 服务来获取。
二、设计2.1. 结构2.1.1. 属性三、初始化ShuffleBlockFetcherIterator 是读取中间结果的关键。初始化 ShuffleBlockFetcherIterator 的时候会调用到 $initialize()$ 方法~
3.1. 划分本地与远程 Block$partitionBlocksByFetchMode()$ 方法用于划分哪些 Block 从本地获取,哪些需要远程拉取。
12val remoteRequests = partitionBlocksByFetchMode( blocksByAddress, localBlocks, hostLocalBlocksByExecutor, pushMergedLocalBlocks)
3.2. 将 FetchRequest 随机排序存入1fetchR ...
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Analyzer 模块-Rule-Resolution-ResolveAggregateFunctions
一、概述表达式一般指的是不需要触发执行引擎而能够直接进行计算的单元,例如加减乘除四则运算、逻辑操作、转换操作、过滤操作等。
二、实现Catalyst 实现了完善的表达式体系,与各种算子(QueryPlan)占据同样的地位。算子执行前通常都会进行”绑定”操作,将表达式与输入的属性对应起来,同时算子也能够调用各种表达式处理相应的逻辑。
在 Expression 类中,主要定义了5个方面的操作,包括基本属性、核心操作、输入输出、字符串表示和等价性判断
核心操作 eval 函数实现了表达式对应的处理逻辑,也是其他模块调用该表达式的主要接口,而 genCode 和 doGenCode 用于生成表达式对应的 Java 代码。字符串表示用于查看该 Expression 的具体内容,如表达式名和输入参数等。
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Analyzer 模块-Rule-Resolution-ResolveAliases
一、概述表达式一般指的是不需要触发执行引擎而能够直接进行计算的单元,例如加减乘除四则运算、逻辑操作、转换操作、过滤操作等。
二、实现Catalyst 实现了完善的表达式体系,与各种算子(QueryPlan)占据同样的地位。算子执行前通常都会进行”绑定”操作,将表达式与输入的属性对应起来,同时算子也能够调用各种表达式处理相应的逻辑。
在 Expression 类中,主要定义了5个方面的操作,包括基本属性、核心操作、输入输出、字符串表示和等价性判断
核心操作 eval 函数实现了表达式对应的处理逻辑,也是其他模块调用该表达式的主要接口,而 genCode 和 doGenCode 用于生成表达式对应的 Java 代码。字符串表示用于查看该 Expression 的具体内容,如表达式名和输入参数等。
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Analyzer 模块-Rule-Resolution-ResolveFunctions
一、概述表达式一般指的是不需要触发执行引擎而能够直接进行计算的单元,例如加减乘除四则运算、逻辑操作、转换操作、过滤操作等。
二、实现Catalyst 实现了完善的表达式体系,与各种算子(QueryPlan)占据同样的地位。算子执行前通常都会进行”绑定”操作,将表达式与输入的属性对应起来,同时算子也能够调用各种表达式处理相应的逻辑。
在 Expression 类中,主要定义了5个方面的操作,包括基本属性、核心操作、输入输出、字符串表示和等价性判断
核心操作 eval 函数实现了表达式对应的处理逻辑,也是其他模块调用该表达式的主要接口,而 genCode 和 doGenCode 用于生成表达式对应的 Java 代码。字符串表示用于查看该 Expression 的具体内容,如表达式名和输入参数等。
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.















