











Spark-源码学习-SparkSQL-架构设计-SQL 引擎-架构设计
一、概述SQL 引擎负责承接客户端输入的 SQL 请求,并根据负载场景将 SQL 语句经过其解析、优化、执行等模块的处理后,将结果返回至客户端。
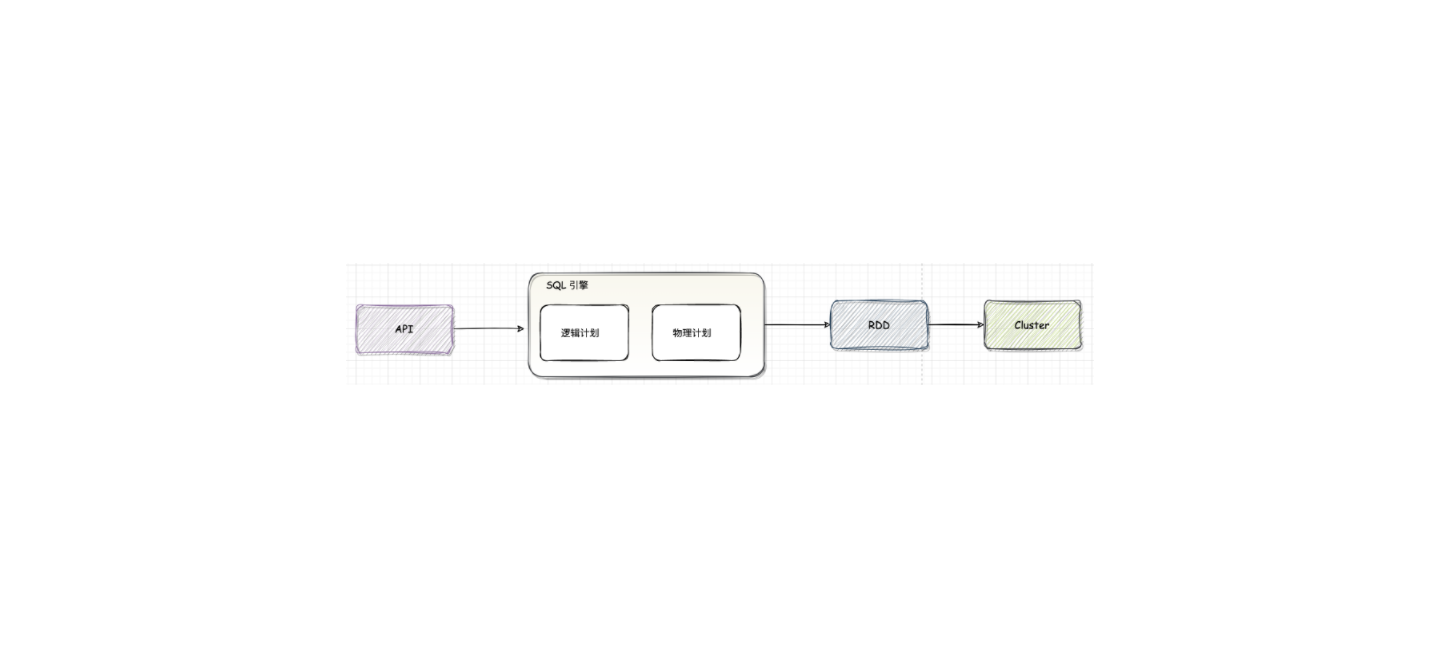
对于 Spark SQL 系统,从 SQL 到 Spark 中 RDD 的执行需要经过两个大的阶段,分别是逻辑计划(LogicalPlan)和物理计划( PhysicalPlan)
1.1. 逻辑计划逻辑计划阶段会将用户所写的 SQL 语句转换成树型数据结构(逻辑算子树),SQL 语句中蕴含的逻辑映射到逻辑算子树的不同节点,逻辑计划阶段生成的逻辑算子树并不会直接提交执行,仅作为中间阶段。
1.2. 物理计划物理计划阶段将上一步逻辑计划阶段生成的逻辑算子树进行进一步转换,生成物理算子树。物理算子树的节点会直接生成 RDD 或对RDD 进行 transformation 操作。
从 SQL 语句的解析一直到提交之前,上述整个转换过程都在 Spark 集群的 Driver 端进行,不涉及分布式环境。SparkSession 类的 sql 方法调用 Session State 中的各种对象,包括上述不同阶段对应的 SparkSqlParser ...
Flink 源码环境搭建
本篇主要是记一下如何调试 Flink 的源码,以 Standalone 模式为例
一、编译在GitHub 下载源码并编译:
12git clone git@github.com:apache/flink.gitgit checkout release-1.6.3
编译命令:
1mvn clean install -DskipTests -Dmaven.javadoc.skip=true -Dcheckstyle.skip=true -T 4
maven 的 settings.xml 文件的 mirror 添加:
12345678910111213 1<mirror> 2 <id>nexus-aliyun</id> 3 <mirrorOf>*,!jeecg,!jeecg-snapshots,!mapr-releases</mirrorOf> 4 <name>Nexus aliyun</name> 5 <url>http://maven.aliyun.com/nexus/c ...
Spark-源码学习-SparkSQL-架构设计-Catalog 体系-架构设计(2.x)
一、概述在 Spark SQL 系统中,Catalog 主要用于各种函数资源信息和元数据信息(数据库、数据表、数据视图、数据分区与函数等)的统一管理。Spark SQL 的 Catalog 体系涉及多个方面。
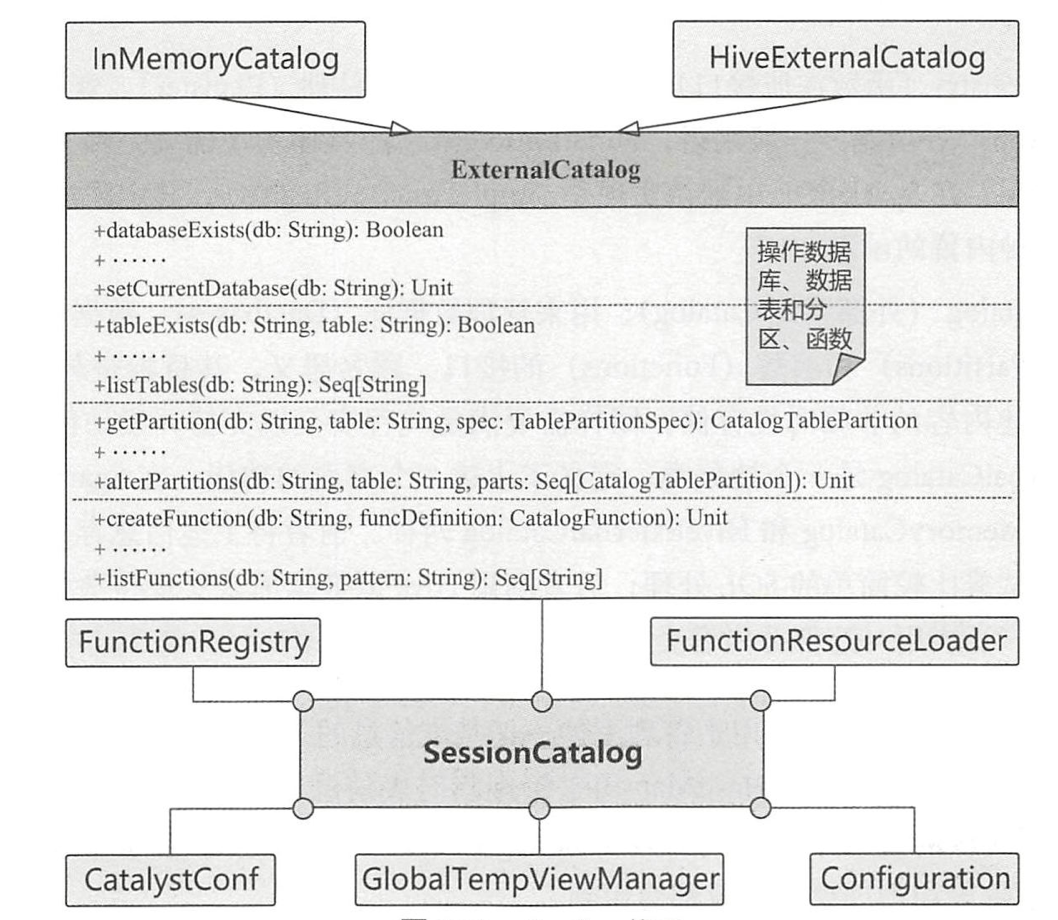
二、架构设计Spark SQL 中的 Catalog 体系实现以 SessionCatalog 为主体,通过 SparkSession (Spark 程序入口)提供给外部调用。一般一个 SparkSession 对应一个 SessionCatalog。本质上,SessionCatalog 起到了一个代理的作用,对底层的元数据信息、临时表信息、视图信息和函数信息进行了封装。
2.1. 构造参数SessionCatalog 的构造参数包括 6 部分,除传入 Spark SQL 和 Hadoop 配置信息的 CatalystConf 与 Configuration 外,还涉及以下4个方面的内容。
2.1.1. GlobalTempViewManager对应 DataFrame 中常用的 $createGlobalTempView()$ 方法,进行跨 Session 的视图管理 ...

数据湖系列
一、概述二、实现PaimonIcebergHudi
引用本站文章
数据湖-Paimon 系列
Joker
引用本站文章
link 数据湖-三架马车-Iceberg 系列
Joker
引用本站文章
数据湖-三架马车-Hudi 系列
Joker
Spark-源码学习-SparkCore-提交作业
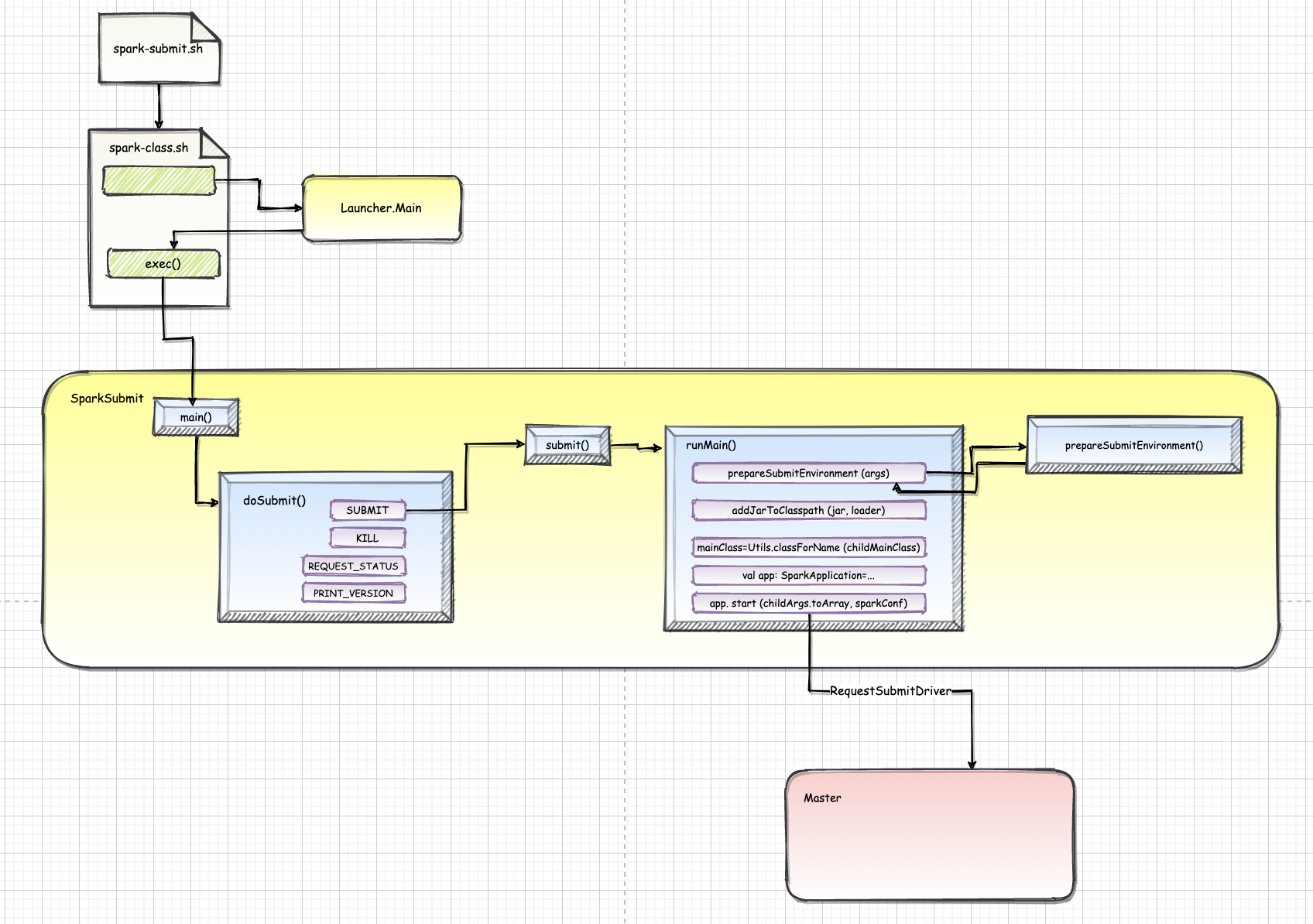
一、概述为了简化应用程序提交的复杂性,Spark提供了各种应用程序提交的统一入口,即 spark-submit 脚本,应用程序的提交都间接或直接地调用了该脚本。
二、源码~Spark 任务的第一步: 如何提交用户编写的程序🤔️~
2.1. /bin/spark-submitSpark 提供了各种应用程序 application 提交的统一入口, 即 spark-submit 脚本, 应用程序的提交都间接或直接地调用了该脚本
https://blog.csdn.net/qq_26838315/article/details/115175653
用户应用程序可以使用 bin/spark-submit 脚本来启动。spark-submit 脚本负责使用 Spark 及其依赖关系设置类路径,并可支持 Spark 支持的不同群集管理器和部署模式。
1exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"
所有其他脚本最终都调 ...
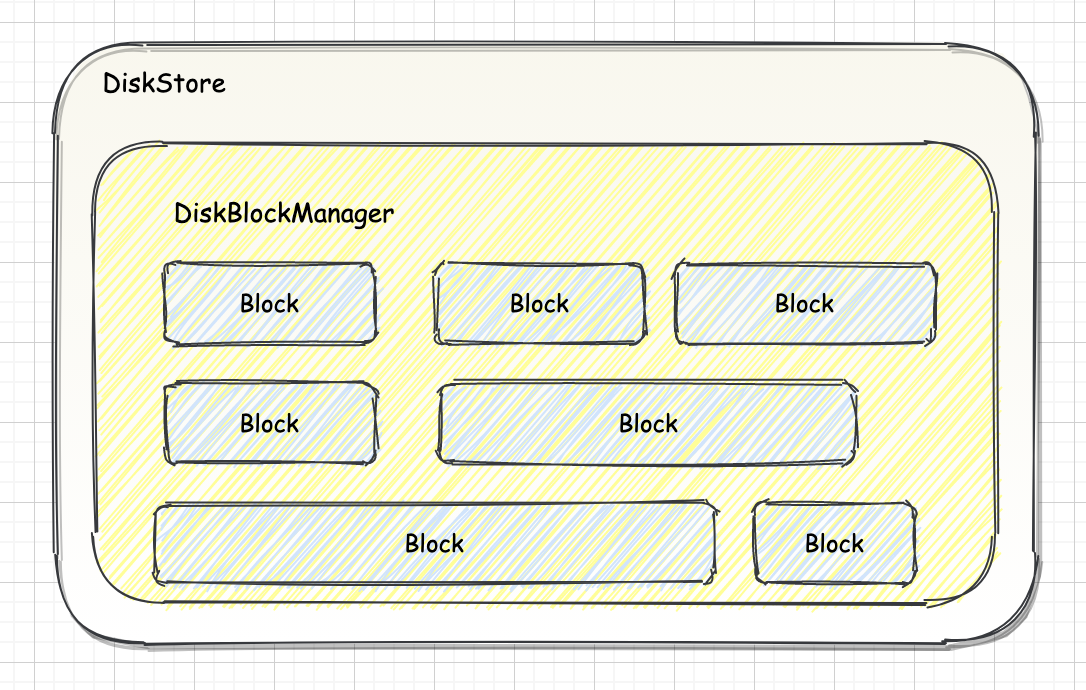
Spark-源码学习-SparkCore-存储服务-磁盘组件-DiskStore
一、概述
二、实现https://mp.weixin.qq.com/s/Z-VOIkb-ubGlyxZxOMcYDA
2.1. 属性
minMemoryMapBytes: 使用内存映射(memory map)读取文件的最小阈值
由配置项 spark.storage.memoryMapThreshold 指定,默认值2M。当磁盘中的文件大小超过该值时,就不会直接读取,而用内存映射文件来读取,提高效率。
maxMemoryMapBytes: 使用内存映射读取文件的最大阈值
由配置项 spark.storage.memoryMapLimitForTests 指定。它是个测试参数,默认值为不限制。
blockSizes: 维护块ID与其对应大小之间的映射关系的ConcurrentHashMap。
三、BlockData3.1. DiskBlockData3.1.1. 方法
$toChunkedByteBuffer()$
在数据量比较大的时候,因为每次申请的内存块大小有限制 maxMemoryMapBytes,因此须要切分红多个块
$toChunkedByteBuffer()$ 方 ...
Spark-源码学习-SparkCore-存储服务-磁盘组件
一、理论Spark 本身是基于内存计算的架构,数据的存储也主要分为内存和磁盘两个路径。在 Spark 当中,磁盘都用在哪些地方呢🤔️~
溢出临时文件
存储 Shuffle 中间文件
缓存分布式数据集
磁盘的第三个作用就是缓存分布式数据集。也就是说,凡是带DISK字样的存储模式,都会把内存中放不下的数据缓存到磁盘
Spark 将经常被重要的数据缓存到内存中以提升数据读取速度,当内存容量有限时,则将数据存入磁盘中或根据最近最少使用页面置换算法将内存中使用频率较低的文件空间收回,从而让新的数据进来。Spark 则根据存储位置、是否可序列化和副本数目这凡个要素将数据存储分为多种存储级别。
二、实现2.1.架构设计2.1.1. DiskBlockManagerDiskStore 负责 Spark 磁盘存储。依赖于 DiskBlockManager, DiskBlockManager 负责为逻辑的 Block 与数据写入磁盘的位置之间建立逻辑的映射关系
引用本站文章
...

Spark-源码学习-SparkSQL-架构设计-Catalog 体系-3.X
一、概述DataSourceV2 是 Spark 2.x 新推出的 API,用来和外部数据存储进行集成。原来的 SessionCatalog 也暴露出弊端和不足,缺少对表的元数据进行操作,比如创建、修改、删除表等,为了适应新的数据源特性,Spark 推出了新的接口: CatalogPlugin。
引用站外地址,不保证站点的可用性和安全性
Spark Catalog深入理解与实战
Joker
引用站外地址,不保证站点的可用性和安全性
Spark 笔记之 Catalog
Joker
二、设计2.1. 元数据模型Spark 的元数据模型定义了任务的元数据结构,如数据库、表、视图、函数等,Spark 定义了 4 类接口分别对应于 4 种元数据类型,元数据类型之间的层次 ...
Spark-源码学习-SparkSQL-架构设计-Catalog 体系
一、概述Spark 中的 DataSet 和 Dateframe API 支持结构化分析。结构化分析的一个重要的方面是管理元数据。这些元数据可能是一些临时元数据(比如临时表)SQLContext 上注册的 UDF 以及持久化的元数据。
Spark 的早期版本并没有标准的 API 來访问这些元数据的。用户通常使用查询语句(比如 show tables) 来查询这些元数据。这些查询通常需要操作原始的字符串,而且不同元数据类型的操作也是不一样的。Spark 2.0 中添加了标准的 API(称为 Catalog) 来访问 Spark SQL 中的元数据。
引用站外地址,不保证站点的可用性和安全性
一篇文章了解 Spark 3.x 的 Catalog 体系
Joker
二、设计2.1. Spark 2.x 的 Catalog 体系2.1.1. 设计
在 Spark 2.× 中,Spark SQL 中的 Catalog 体系实现以 ...
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.















