











Flink-源码学习-API-Connector-Source 设计
一、Before Flink 1.10~在 Flink 1.10 之前,Source connector 对于批模式和流模式需要不同的处理逻辑。
https://blog.csdn.net/qq_21383435/article/details/126816224
https://zhuanlan.zhihu.com/p/454440159
https://blog.csdn.net/sinat_39809957/article/details/125527633
1.1. 设计1.1.1. Inputformat在 DataSet API 中 Source 对应的核心接口为 InputFormat。
InputSplitSource 负责划分 InputSplit
InputSplit 表示一个逻辑分区,InputFormat 会根据 Split ID 读取输入数据的对应分区。
RichInputFormat 拓展 InputFormat,增加 $openInputFormat$ 和 $closeInputFormat$ 方法来管理运行时的状态。相比 InputFo ...

Flink-源码学习-Blob 服务
一、概述Blob 服务用来管理二进制文件(例如上传 job 的 jar 以及依赖的一些 jar,或者 TaskManager 上传的 log 文件等…)
当向 Flink 提交一个 Job 的时候,blob 服务端将会把用户的代码分发到所有工作节点TaskManager
1.1. Flink 中支持的 BLOB 文件类型
jar 包
被 user classloader 使用的 jar 包
高负荷 RPC 消息
RPC 消息长度超出了 akka.framesize 的大小
在 HA 摸式中,利用底层分布式文件系统分发单个高负荷 RPC 消息,比如: TaskDeploymentDescriptor,给多个接受对象。
失败导致重新部署过程中复用RPC消息
TaskManager 的日志文件
为了在 web ui 上展示taskmanager的日志
二、实现2.1. 架构设计2.1.1. BlobStoreBLOB 底层存储支持多种实现 HDFS ,S3,FTP FTP 等,HA 中使用 BlobStore 进行文件的恢复。它有两个实现类,分别是 VoidBlobS ...
Flink-源码学习-FlinkCore-公共基础服务-Blob 服务
一、概述Blob 服务用来管理二进制文件(例如上传 job 的 jar 以及依赖的一些 jar,或者 TaskManager 上传的 log 文件等…)
当向 Flink 提交一个 Job 的时候,blob 服务端将会把用户的代码分发到所有工作节点TaskManager
1.1. Flink 中支持的 BLOB 文件类型
jar 包
被 user classloader 使用的 jar 包
高负荷 RPC 消息
RPC 消息长度超出了 akka.framesize 的大小
在 HA 摸式中,利用底层分布式文件系统分发单个高负荷 RPC 消息,比如: TaskDeploymentDescriptor,给多个接受对象。
失败导致重新部署过程中复用RPC消息
TaskManager 的日志文件
为了在 web ui 上展示taskmanager的日志
二、实现2.1. 架构设计2.1.1. BlobStoreBLOB 底层存储支持多种实现 HDFS ,S3,FTP FTP 等,HA 中使用 BlobStore 进行文件的恢复。它有两个实现类,分别是 VoidBlobS ...

Flink-源码学习-FlinkCore-公共基础服务-JobGraphStore
一、概述JobGraphStore 可以存储 JobGraph,当集群宕机后,可以从 JobGraphStore 中恢复之前提交运行的 JobGraph,保证提交到集群运行的作业能够恢复正常。
在 Session 集群模式下,当集群开启高可用后,会通过 HighAvallabilityServices 服务为 Session 集群创建 JobGraphStore。JobGraphStore 可以存储提交的 JobGraph 信息,当集群宕机后,可以 JobGraphStore 中恢复之前提交的 JobGraph,从而保证提交到集群上的作业恢复正常。
二、实现JobGraphStore 的主要实现有 SingleJobGraphStore、StandaloneJobGraphStore 和 ZookeeperJobGraphStore 三种类型,只有ZooKeeperJobGraphStore 可以提供 JobGraph 的持久化和恢复操作,另外两种都是非高可用类型。
JobGraphStore 实现了 JobGraphListener 接口,完成对 JobGraphStor ...
Flink-源码学习-JobGraphStore
一、概述JobGraphStore 可以存储 JobGraph,当集群宕机后,可以从 JobGraphStore 中恢复之前提交运行的 JobGraph,保证提交到集群运行的作业能够恢复正常。
在 Session 集群模式下,当集群开启高可用后,会通过 HighAvallabilityServices 服务为 Session 集群创建 JobGraphStore。JobGraphStore 可以存储提交的 JobGraph 信息,当集群宕机后,可以 JobGraphStore 中恢复之前提交的 JobGraph,从而保证提交到集群上的作业恢复正常。
二、实现JobGraphStore 的主要实现有 SingleJobGraphStore、StandaloneJobGraphStore 和 ZookeeperJobGraphStore 三种类型,只有ZooKeeperJobGraphStore 可以提供 JobGraph 的持久化和恢复操作,另外两种都是非高可用类型。
JobGraphStore 实现了 JobGraphListener 接口,完成对 JobGraphStor ...
Flink-源码学习-插件机制
Flink 的插件机制会在启动时动态加载一次,使用 Java SPI 机制实现插件,方便扩展和管理,使 Flink 可以专注于计算。
Flink 插件代码在 Flink 的 plugins 文件夹中。
文件系统插件
文件系统的插件机制在 Flink version 1.9 中引入,从 1.10 开始,s3 插件必须通过插件机制加载
connector 插件
引用站外地址,不保证站点的可用性和安全性
Flink SQL 原理之 Connector 插件机制
墨天轮
资源插件
引用站外地址,不保证站点的可用性和安全性
扩展资源框架
Flink
Flink-源码学习-文件系统
Flink 在集群启动的一个操作就是初始化文件系统。Flink 中的文件系统主要有两个用途,
Flink实现容错,存储程序状态,恢复数据,主要通过 FsDataOutputStream 实例来实现。
保存链接状态,避免每次创建链接的资源消耗。
一、概述Apache Flink 使用文件系统来消费和持久化地存储数据,以处理应用结果以及容错与恢复。最常用的文件系统:本地存储,hadoop-hdfs, Amazon S3,阿里云 OSS 和 Azure Blob Storage。
文件使用的文件系统通过其 URI Scheme 指定。例如:
file:///home/user/text.txt 表示一个在本地文件系统中的文件
hdfs://namenode: 50010/data/user/text.txt 表示一个在指定 HDFS 集群中的文件。
文件系统在每个进程实例化一次,然后进行缓存池化,从而避免每次创建流时的配置开销,并强制执行特定的约束,如连接流的限制。
1.1. 本地文件系统Flink 原生支持本地机器上的文件系统,包括任何挂载到本地文件系统的 NFS 或 SAN ...
Flink-源码学习-集群启动-standalone-jobmanager-核心组件-Dispatcher
一、概述Dispatcher 负责对集群中的作业进行接收和分发处理操作,客户端可以通过与 Dispatcher建立 RPC 连接,将作业提交到集群
二、实现2.1. 架构设计2.1.1. Dispatcher负责对集群中的作业进行接收和分发处理操作,客户端可以通过与 Dispatcher 建立 RPC 连接,将作业过提交到集群 Dispatcher 服务中。
2.1.2. DispatcherRunner负责启动和管理 Dispatcher 组件,并支持对 Dispatcher 组件的 Leader 选举。当 Dispatcher 集群组件出现异常并停止时,会通过 DispatcherRunner 重新选择和启动新的 Dispatcher 服务,从而保证 Dispatcher 组件的高可用。
2.1.3. DispatcherLeaderProcess负责管理 Dispatcher 生命周期,同时提供了对 JobGraph 的任务恢复管理功能。如果基于 ZooKeeper 实现了集群高可用,DispatcherLeaderProcess 会将提交的 JobGraph 存储在 Z ...
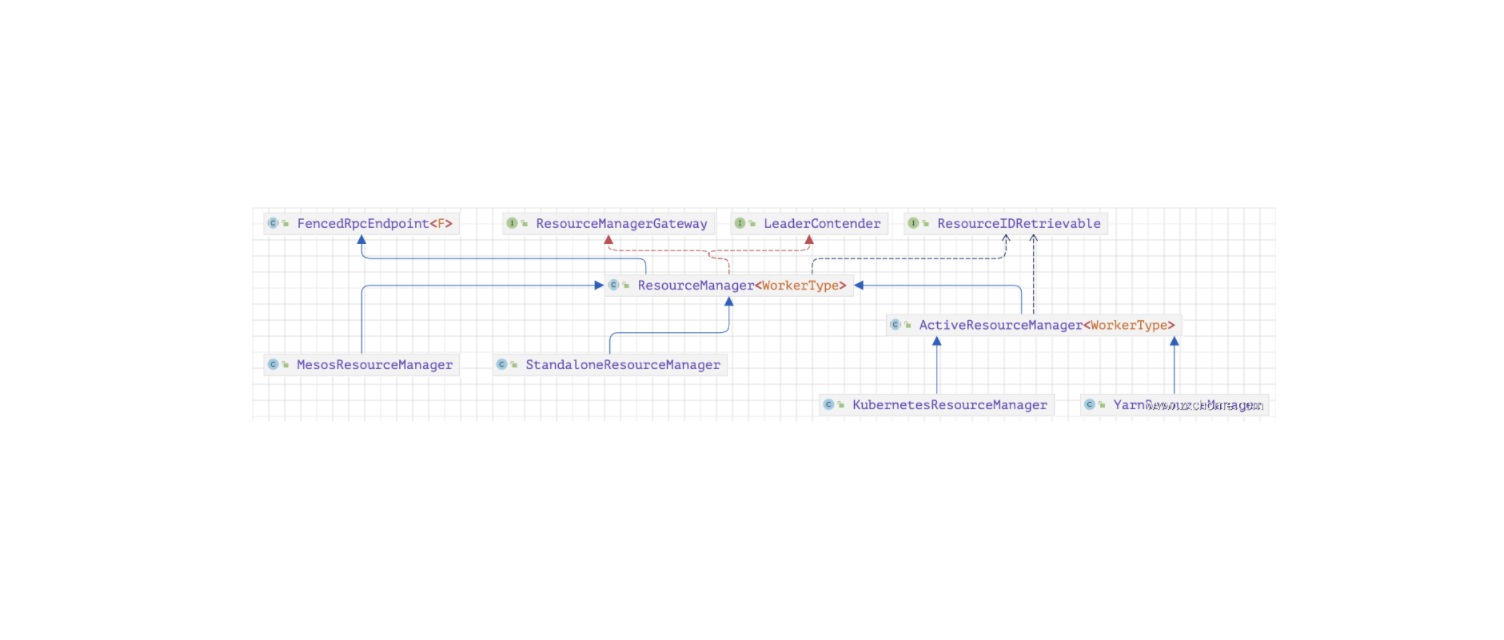
Flink-源码学习-集群启动-standalone-jobmanager-核心组件-Resourcemanager
一、概述ResourceManager 作为统一的集群资源管理器,用于管理整个集群的计算资源,包括CPU资源、内存资源等。同时,ResourceManager 负责向集群资源管理器中申请容器资源启动 TaskManager 实例,并对 TaskManager 进行集中管理。当新的作业提交到集群后,JobManager 会向 ResourceManager 申请作业执行需要的计算资源,进而完成整个作业的运 行。
二、实现ResourceManager 作为集群资源管理组件,不同的 Cluster 集群资源管理涉及的初始化过程也会有所不同。为了兼容 Hadoop Yarn、 Kubernetes、 Mesos 等集群资源管理器,在 ResourceManager 抽象实现类的基础上,分别实现了 ActiveResourceManager、StandaloneResourceManager 以及 MesosResourceManager 等子类。
2.1. ActiveResourceManagerActiveResourceManager 实现了动态资源管理,可以根据提交的作业动态选 ...
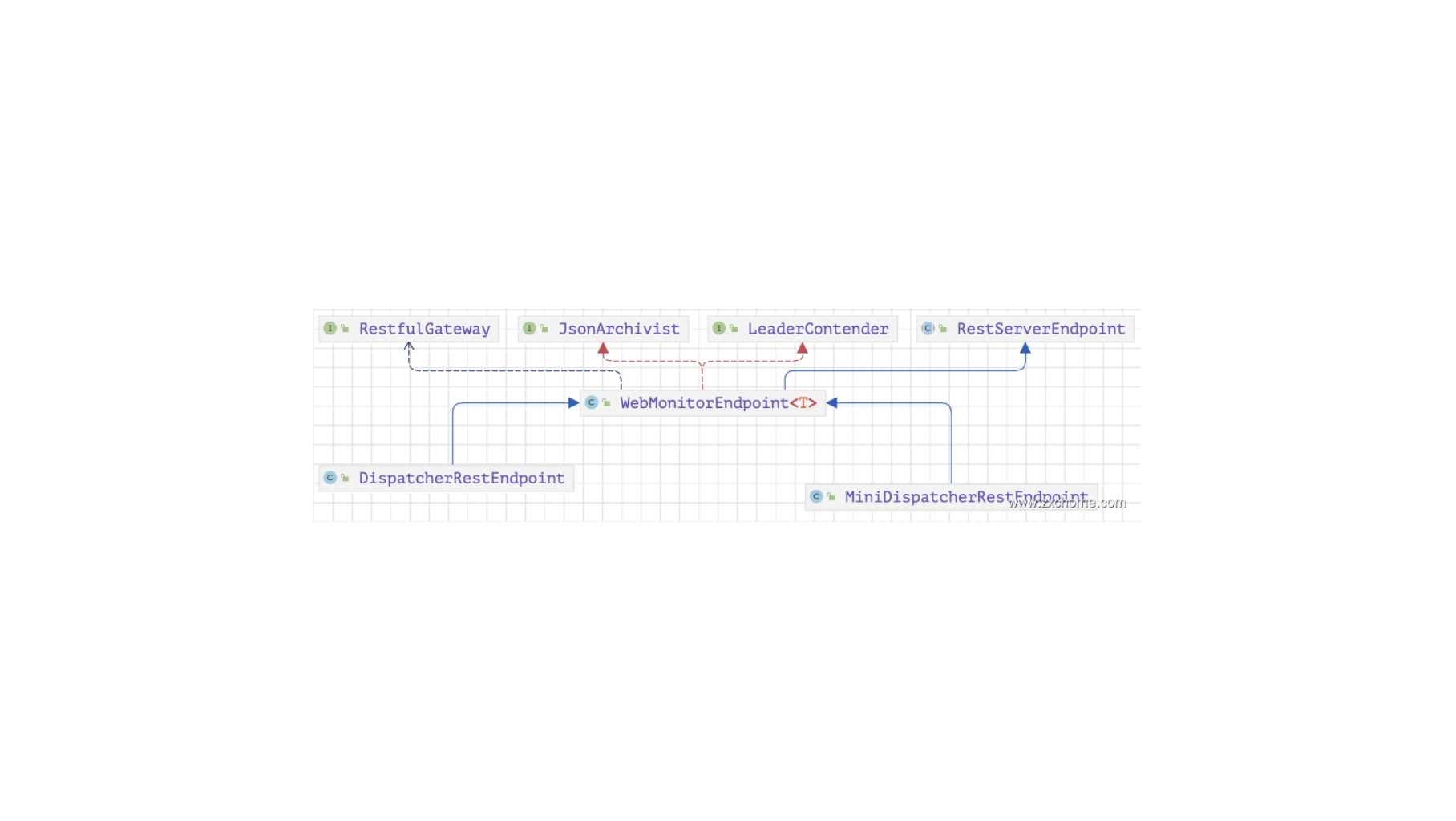
Flink-源码学习-集群启动-standalone-jobmanager-核心组件-WebMonitorEndpoint
一、概述WebMonitorEndpoint 基于 Netty 通信框架实现了 Restful 的服务后端,提供 Restful 接口支持 Flink Web 页面在内的所有 Rest 请求,例如获取集群监控指标。
二、实现2.1. 架构设计WebMonitorEndpoint 继承了 RestServerEndpoint 基本实现类, 其中 RestServerEndpoint 基于 Netty 框架实现了 Rest 服务后端,并提供了自定义 Handler 的初始化和实现抽象方法。
DispatcherRestEndpoint 通过 Restful API 提交 JobGraph
MiniDispatcherRestEndpoint
主要是针对本地执行实现的 mini 版 DispatcherRestEndpoint,区别在于因为 MiniDispatcherRestEndpoint 不支持通过 Restful API 提交 JobGraph,不用加载 JobGraph 提交使用的 Handlers。
在 IDEA 中执行作业时创建的实际上是 MiniClust ...
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.















