












Spark-源码学习-SparkCore-通信服务-架构设计-传输层-Handler-MessageEncoder
一、概述MessageEncoder 负责消息编码,在将消息放入管道前,先对消息内容进行编码,防止管道另一端读取时丢包和解析错误。
Spark-源码学习-SparkCore-通信服务-架构设计-传输层-Handler-TransportFrameDecoder
一、概述TransportFrameDecoder 对从管道中读取的 ByteBuf 按照数据帧进行解析;
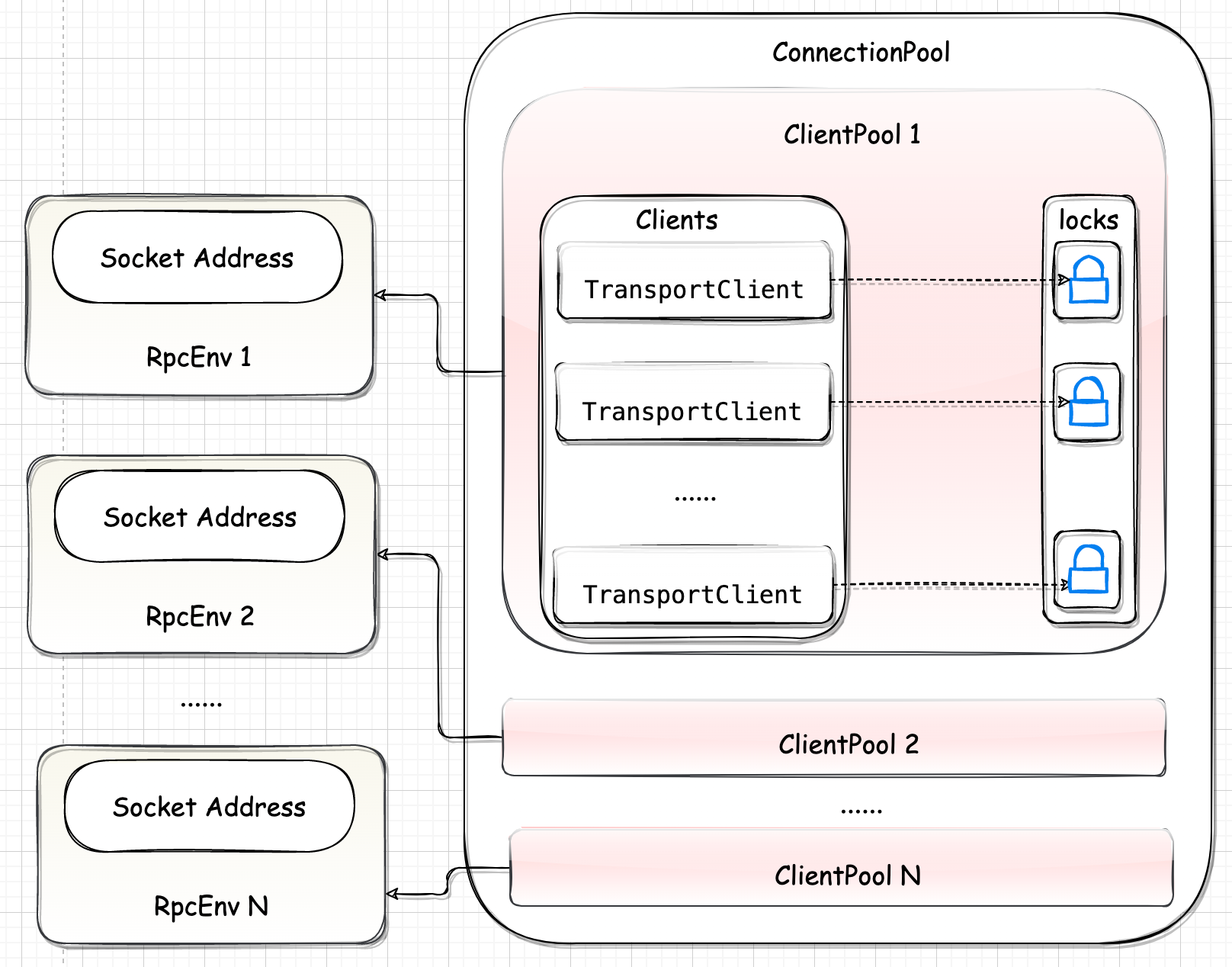
Spark-源码学习-通信服务-架构设计-传输层设计-客户端
一、概述创建传输客户端工厂 TransportClientFactory 是 NettyRpcEnv 向远端服务发起请求的基础, Spark 与远端 RpcEnv 进行通信都依赖于 TransportClientFactory 生产的 TransportClient。
有了 TransportClientFactory, Spark 的各个模块就可以使用它创建 RPC 客户端 TransportClient 了。每个 TransportClient 实例只能和一个远端的 RPC 服务通信,所以 Spark 中的组件如果想要和多个 RPC 服务通信,就需要持有多个 TransportClient 实例。
二、实现$TransportContext.createClientFactory()$ 方法可以创建 TransportClientFactory 的实例,在 TransportContext 中有两个重载的 $createClientFactory()$ 方法, 它们最终在构造 TransportClientFactory 时都会传递两个参数: TransportCont ...
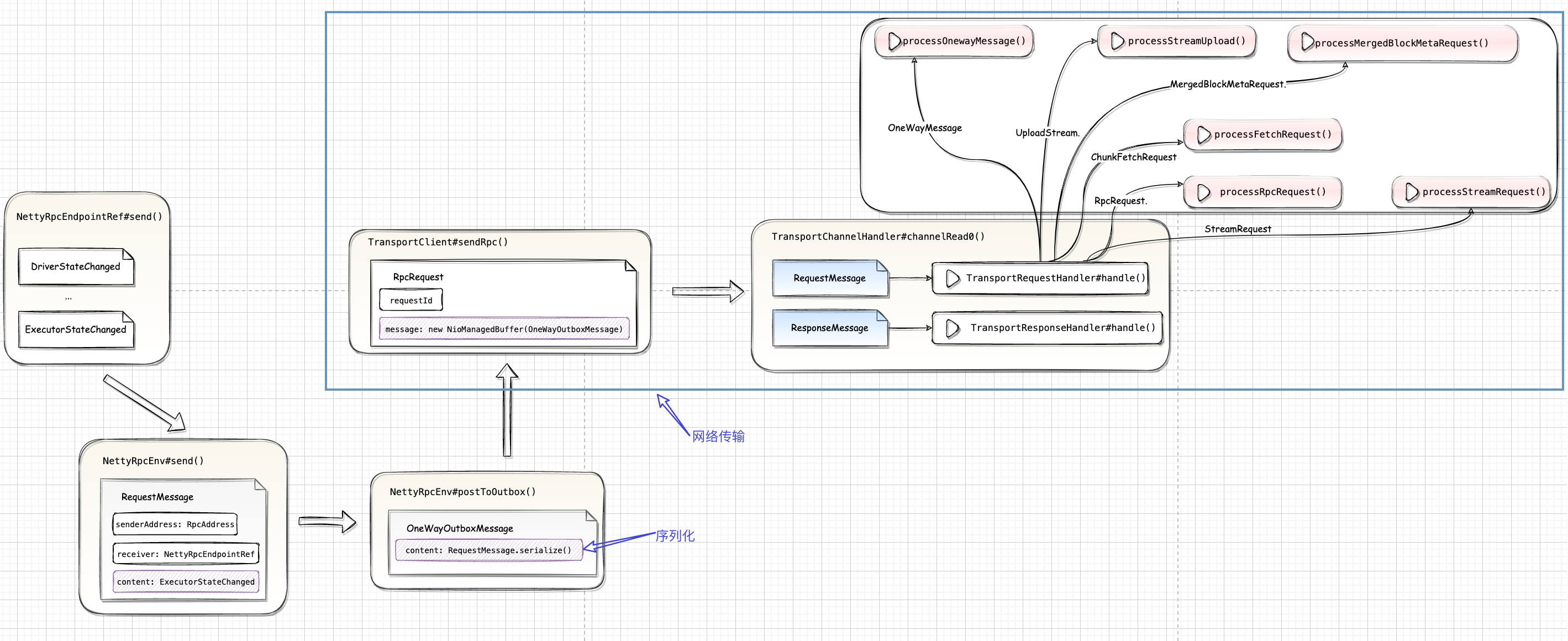
Spark-源码学习-SparkCore-通信服务-架构设计-协议层
一、概述和 Java 传统的 RPC 解决方案对比,Spark RPC 不是通过定义接口或者方法标示(比如通常的 id 或者 name),而是巧妙的使用 Scala 的模式匹配进行方法的路由,在进程之问通信不需要在额外定义通信协议,通过定义 case class 做为请求消息,只需要在服务端的接收入口西数中对请求进行模糊匹配,匹配到相应的请求处理分支就行~虽然点对点通信的契约交换受制于语言,但是 Spark RPC 定位于内部组件通信,所以无伤大雅~
二、消息转换
2.1. RpcEndpointRef#send()1worker.send(DriverStateChanged(driverId, finalState.get, finalException))
2.2. NettyRpcEnv#send()$NettyRpcEnv.send()$ 主要负责把 $RpcEndpointRef.send()$ 传递过来的各种 case class 格式消息进行转为 RequestMessage。
2.3. NettyRpcEnv#postToOutbox()$NettyRp ...
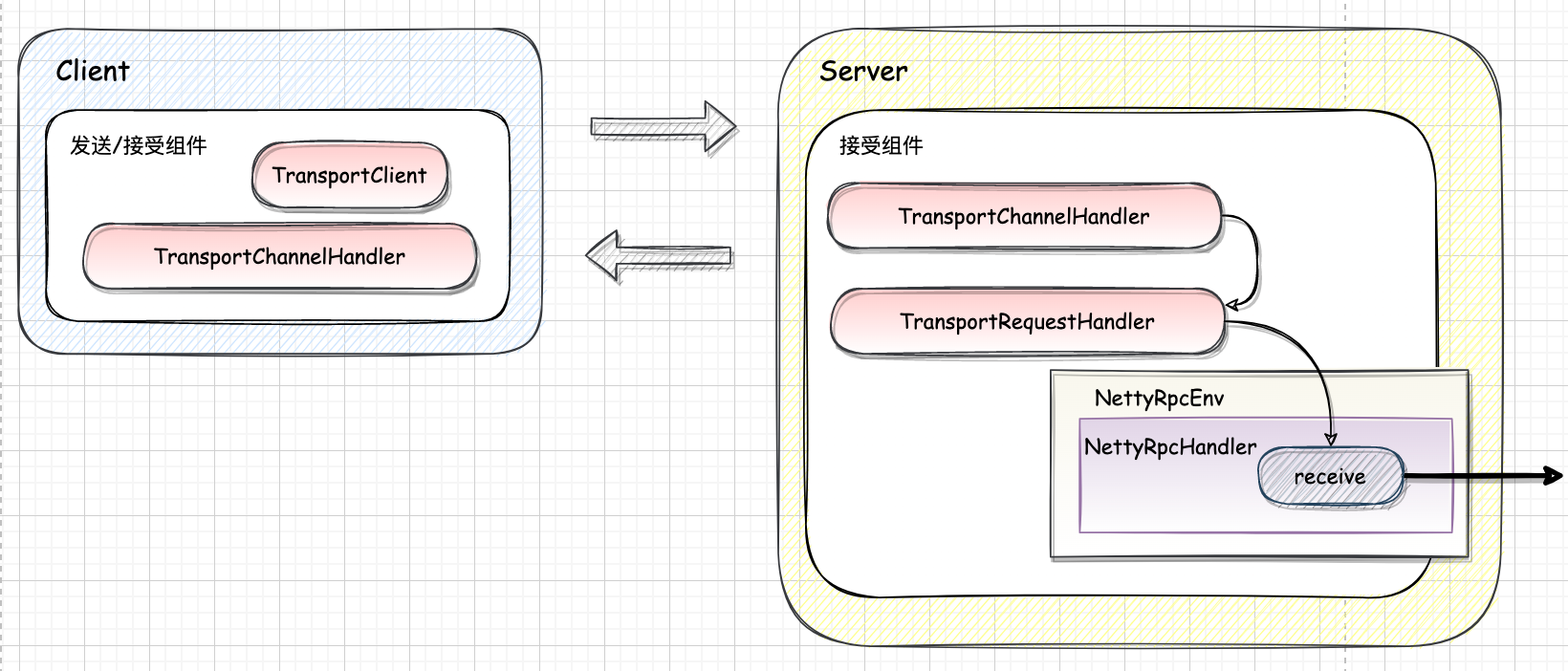
Spark-源码学习-通信服务-架构设计-传输层-TransportChannelHandler
一、概述TransportChannelHandler 实现了 Netty 的 ChannelInboundHandler,以便对 Netty 管道中的消息进行处理。当 TransportChannelHandler 读取到的 request 是 RequestMessage 类型时,则将此消息的处理进一步交给 TransportRequestHandler,当 request 是 ResponseMessage 时,则将此消息的处理进一步交给 TransporResponseHandler。
由协议层的实现知道,最终的消息实现类都直接或间接地实现了 RequestMessage 或 ResponseMessage 接口,在 RPC 传输层中创建的所有通道都是双向的。当客户端使用 RequestMessage 启动 Netty 通道(由服务端的 TransportRequestHandler 处理)时,服务端也会生成 ResponseMessage (由客户端的 TransportRequestHandler 处理)。
服务端也会在同一个 Channel 上获取句柄,向客户端发 ...
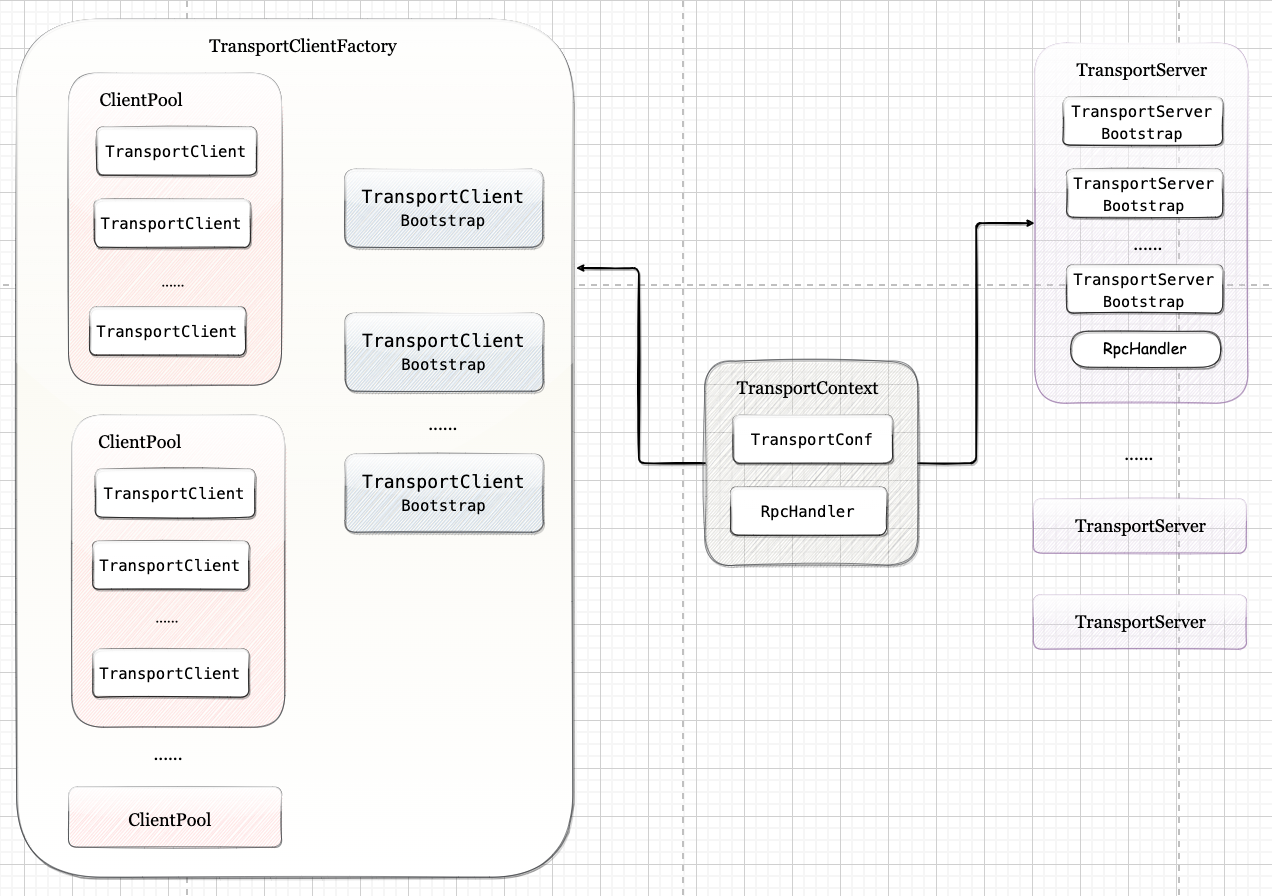
Spark-源码学习-SparkCore-通信服务-架构设计-传输层
一、概述RPC 传输层需要把序列化后的字节流数据传给服务端,然后再把序列化后的调用结果传回客户端。只要能完成这两者的,都可以作为传输层使用。因此,尽管大部分 RPC 框架都使用 TCP 协议,但其实 UDP 也可以,而 gRPC 千脆就用了 HTTP2, Spark RPC 基于 Netty 实现了 RPC 通信服务传输层,
二、架构设计Spark 底层通信全部使用 Netty 进行了替换, 传输上下文 TransportContext 是 NettyRpcEnv 提供服务端与客户端能力的前提,TransportContext 内部包含传输上下文的配置信息 TransportConf 和对客户端请求消息进行处理的 RpcHandler。TransportConf 在创建 TransportClientFactory 和 TransportServer 时都是必需的, 而 RpcHandler 只用于创建 TransportServer。
2.1. 客户端TransportClientFactory 是 RPC 客户端的工厂类。在构造 TransportClientFactory ...
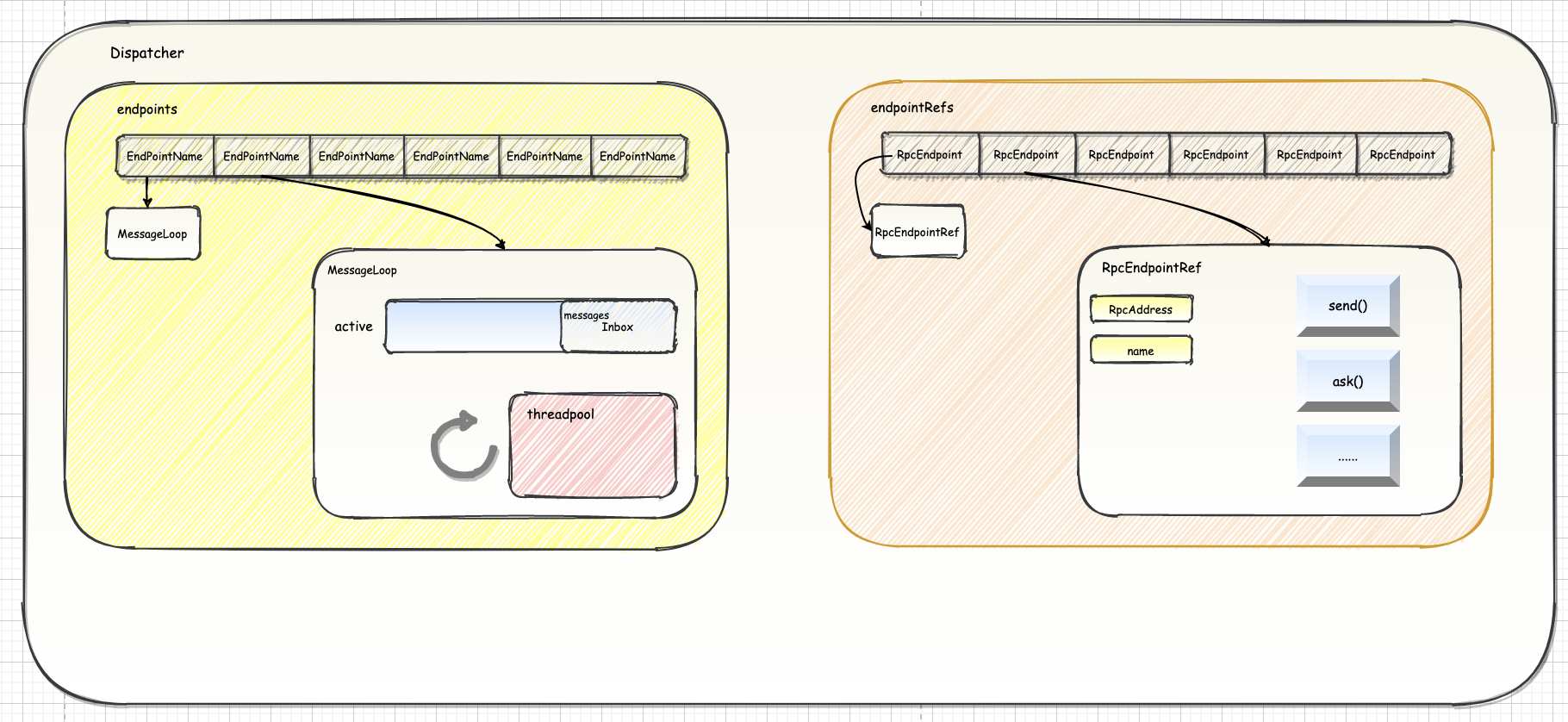
Spark-源码学习-通信服务-架构设计-路由层-Dispatcher
一、概述Dispatcher 负责将 rpc 消息路由到对此消息进行处理的 RpcEndpoint 上。
二、实现Dispatcher 实现在 Spark 2.x 和 Spark 3.x 有一些差别~
2.1. 结构
2.1.1. 属性
endpoints: ConcurrentMap[String, MessageLoop]
负责存储 endpoint name 和 MessageLoop 的映射关系
1private val endpoints: ConcurrentMap[String, MessageLoop] = new ConcurrentHashMap[String, MessageLoop]
endpointRefs: ConcurrentMap[RpcEndpoint, RpcEndpointRef]
负责存储 RpcEndpoint 和 RpcEndpointRef 的映射关系。
12private val endpointRefs: ConcurrentMap[RpcEndpoint, RpcEndpointRef] = new ConcurrentHash ...
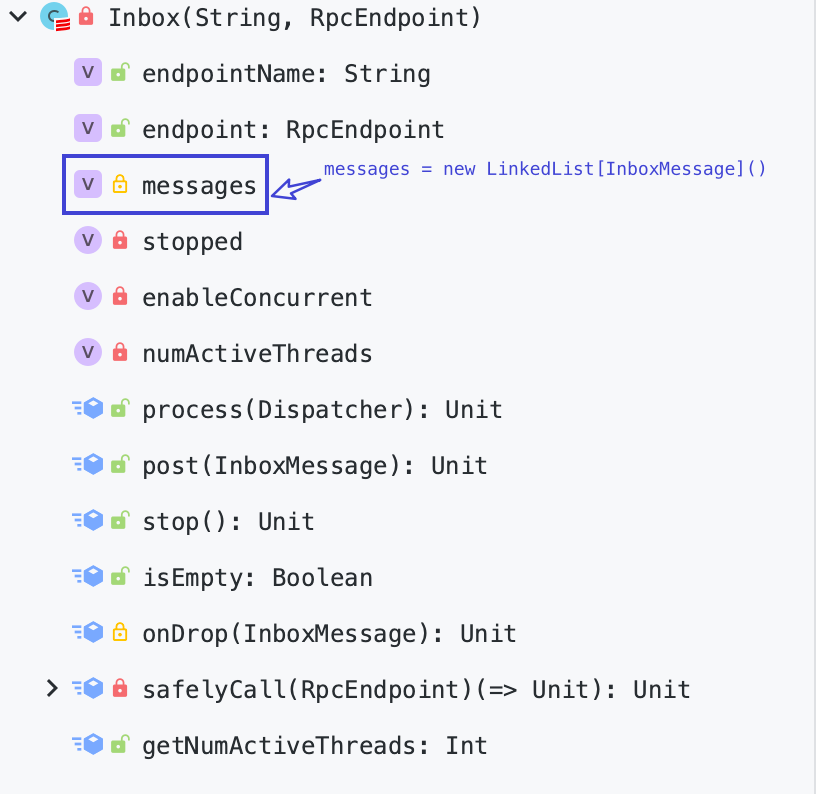
Spark-源码学习-SparkCore-通信服务-架构设计-路由层-Inbox
一、概述Spark RPC 的 Socket I/O 一个典型的 Reactor 模型, 但是结合了 Actor 模型中的 mailbox(Inbox/OutBox), 是一种混合的实现方式。Inbox 是一个存储消息的队列,它负责将消息存储在一个队列中,然后以线程安全的方式将消息发送到 RpcEndpoint。
二、实现2.1. 结构
2.1.1. 属性
messages: 向其他远端 NettyRpcEnv 上的所有 RpcEndpoint 发送的消息列表
消息列表 messages 中的消息类型为 OutboxMessage, 所有将要向远端发送的消息都会被封装成 OutboxMessage 类型。
OutboxMessage 在客户端使用, 是对外发送消息的封装。InboxMessage 在服务端使用, 是对所接收消息的封装。
TransportClient 的 $sendRpc()$ 方法的第二个参数是 RpcResponseCallback 类型, RpcOutboxMessage 本身也实现了 RpcResponseCallback, 所以调用的时候传递 ...
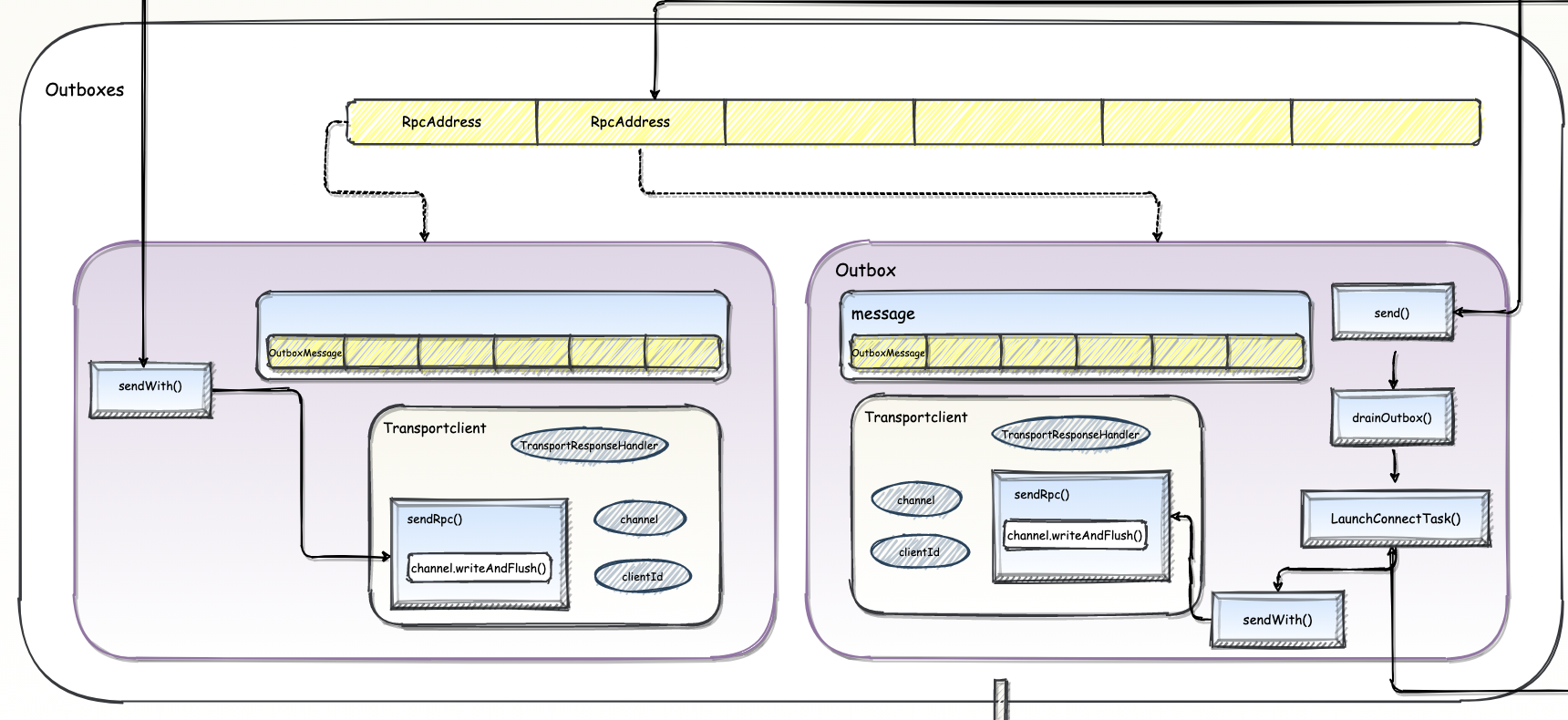
Spark-源码学习-SparkCore-通信服务-架构设计-路由层-Outbox
一、概述Outbox 是一个用于发送消息的组件,它负责将消息发送到远程进程的 Dispatcher。
二、实现
2.1. 结构2.1.1. 属性
nettyEnv: 当前 Outbox 所在节点的 NettyRpcEnv
address: Outbox 所对应的远端 NettyRpcEnv 的地址
messages: 向其他远端 NettyRpcEnv 上的所有 RpcEndpoint 发送的消息列表
消息列表 messages 中的消息类型为 OutboxMessage, 所有将要向远端发送的消息都会被封装成 OutboxMessage 类型。
OutboxMessage 在客户端使用, 是对外发送消息的封装。InboxMessage 在服务端使用, 是对所接收消息的封装。
TransportClient 的 $sendRpc()$ 方法的第二个参数是 RpcResponseCallback 类型, RpcOutboxMessage 本身也实现了 RpcResponseCallback, 所以调用的时候传递了 RpcOutboxMessage 的 this 引用。 ...
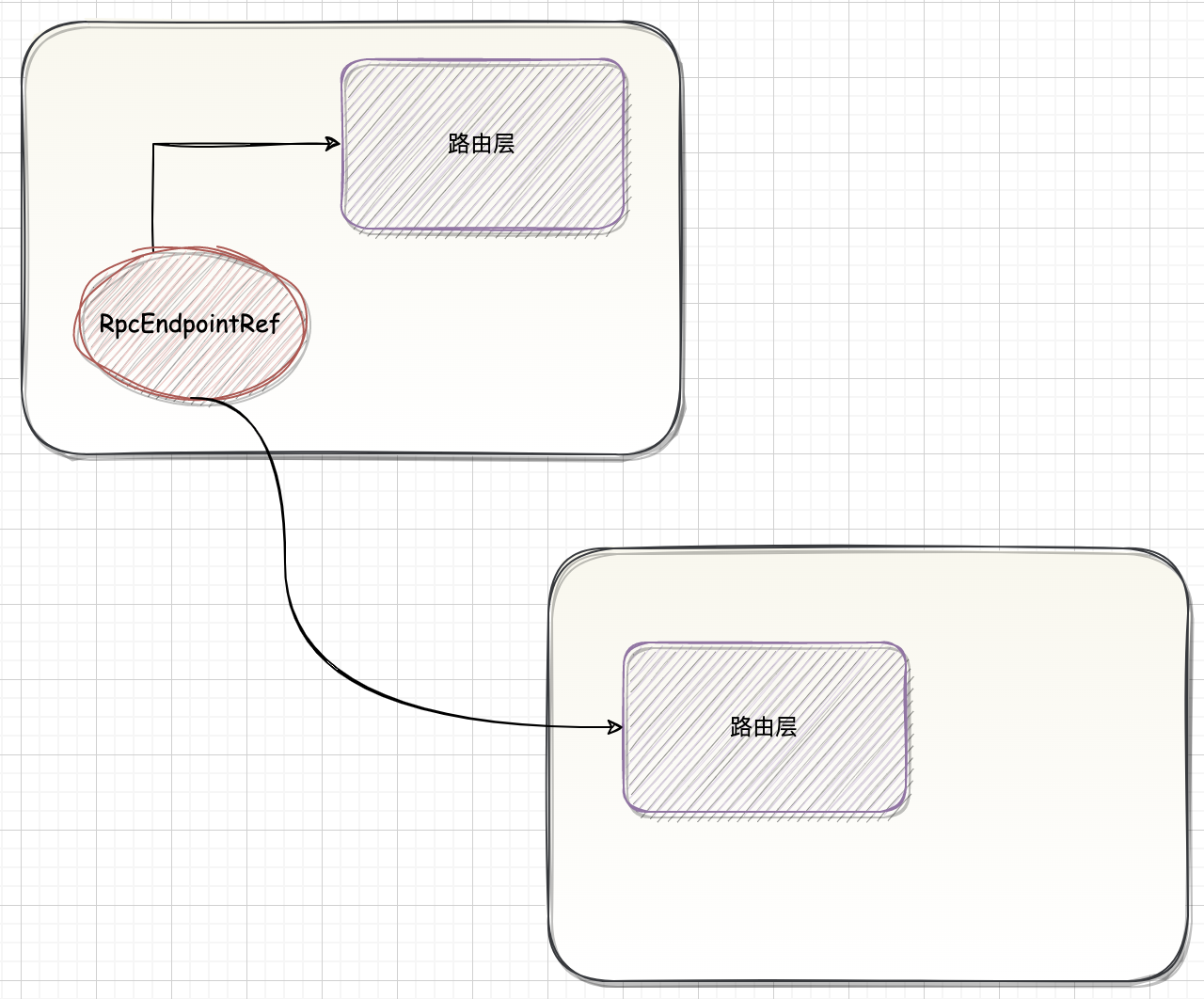
Spark-源码学习-SparkCore-通信服务-架构设计-客户端-代理层
一、概述在 NettyRpcEnv 中,要向远端 RpcEndpoint 发送请求,首先要持有 RpcEndpoint 的引用用对象 RpcEndpointRef(类似于 Akka 中 Actor 的 ActorRef)。
二、实现一般而言,消息投递有下面 3 种情况:
at-most-once
应用了这种机制的消息会被投递 0 次或 1 次, 这条消息可能会丢失。
at-least-once
应用了这种机制的消息潜在地存在多次投递尝试并保证至少会成功一次, 这条消息可能会重复消费, 但不会丢失。
exactly-once
应用了这种机制的消息只会向接收者准确地发送一次, 这种消息既不会丢失, 也不会重复。
2.1. 结构2.1.1. 属性
maxRetries: RPC 最大重新连接次数。
可以使用 spark.rpc.numRetries 属性进行配置,默认为 3 次
retryWaitMs:RPC 每次重新连接需要等待的毫秒数。
可以使用 spark.rpc.retrywait 属性进行配置, 默认值为 3 秒
defaultAskTimeout: ...
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.















