数据湖-Hudi-源码学习-Kernel-Metadata Table 设计
一、概述
Hudi 最开始基于 HDFS 构建和设计,没有太多考虑云上存储场景,导致在云上 FileList 非常慢。因此在 0.8 版本,社区引入了 Metadata Table ,Metadata Table 本身也是一张 Hudi表,可以复用 Hudi Table Service。
Metadata Table 表文件里会存分区下有的所有文件名以及文件大小,每一列的统计信息做查询优化,以及现在社区正在做的,每条记录对应每个文件 ID 都记录在 Meta table,减少处理 Upsert 时查询待更新文件的开销。
二、设计
目前使用 hoodie.metadata.enable 后,会在 .hoodie 目录下生成一张名为 metadata 的 mor 表,利用该表可以显著提升源表的读写性能。
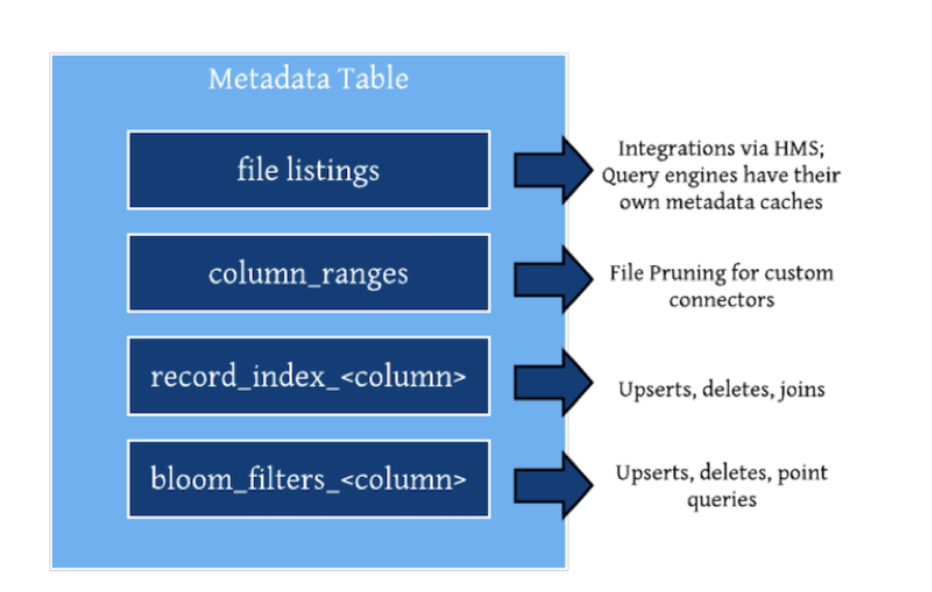
该表目前包含三个分区: files, column_stats, bloom_filters,分区下文件的格式为 hfile,采用该格式的目的主要是为了提高 metadata 表的点查能力。
2.1. files
files 分区纪录了源表各个分区内的所有文件列表,这样hudi在生成源表的文件系统视图时就不必再依赖文件系统的list files操作(在云存储场景list files操作更有可能是性能瓶颈);TimeLine Server和上述设计类似,也是通过时间线服务器来避免对提交元数据进行list以生成hudi active timeline。
2.2. column_stats
column_stats 分区纪录了源表中各个分区内所有文件的统计信息,主要是每个文件中各个列的最大值,最小值,纪录数据,空值数量等。只有在开启了”hoodie.metadata.index.column.stats.enable”参数后才会使能column_stats分区,默认源表中所有列的统计信息都会纪录,也可以通过”hoodie.metadata.index.column.stats.column.list”参数单独设置。Hudi表每次提交时都会更新column_stats分区内各文件统计信息(这部分统计信息在提交前的文件写入阶段便已经统计好)
2.3. bloom_filters
bloom_filters 分区纪录了源表中各个分区内所有文件的 bloom_filter 信息,只有在开启了 hoodie.metadata.index.bloom.filter.enable 参数后才会使用 bloom_filters 分区。
默认纪录源表中 record key 的 bloomfilter, 也可以通过 hoodie.metadata.index.bloom.filter.column.list 参数单独设置。
需要注意 bloom_filter 信息不仅仅存储在 metadata 表中(存在该表中是为了读取加速,减少从各个 base 文件中提取 bloomfilter 的 IO 开销)。
Hudi 表在开启了 hoodie.populate.meta.fields 参数后(默认开启),在完成一个 parquet 文件写入时,会在 parquet 文件的footerMetadata 中填充 bloomfilter 相关参数, 其中:
- hoodie_bloom_filter_type_code 参数为过滤器类型,设置为默认的
DYNAMIC_V0(可根据record key数量动态扩容) - org.apache.hudi.bloomfilter 参数为过滤器 bitmap 序列化结果
- hoodie_min_record_key 参数为当前文件 record_key 最小值
- hoodie_max_record_key 参数为当前文件 record_key 最大值。
Hudi 表提交时其 Metadata 表 bloom_filters 分区内的 bloom_filter 信息便提取自 parquet 文件 footerMetadata 的 “org.apache.hudi.bloomfilter”.
二、架构设计
Hudi最开始是基于HDFS构建和设计,没有太多考虑云上存储场景,导致在云上FileList非常慢。因此在0.8版本,社区引入了Metadata Table,Metadata Table本身也是一张Hudi表,它构建成一张Hudi,可以复用Hudi表等各种表服务。Metadata Table表文件里会存分区下有的所有文件名以及文件大小,每一列的统计信息做查询优化,以及现在社区正在做的,基于Meta Table表构建全局索引,每条记录对应每个文件ID都记录在Meta table,减少处理Upsert时查询待更新文件的开销,也是上云必备。
http://www.manongjc.com/detail/62-rbejybdjrebreac.html
Metadata Table (MDT): Hudi 的元数据信息表,是一个自管理的 Hudi MoR 表,位于 Hudi 表的 .hoodie 目录,开启后用户无感知。同样的 Hudi 很早就支持 MDT,经过不断迭代 0.12版本 MDT 已经成熟。
文件 listings 和 partitions 信息直接通过 metadata table 查询获取,减少 HDFS 的访问,提升读写性能
当完成一次成功的数据写入之后,coordinator会先同步抽取文件listings、partiitons等信息写入metadata table,然后再写event log到timeline
Metadata Table默认是开启的,可以通过hoodie.metadata.enable进行设置
https://mp.weixin.qq.com/s/_490DRB3blmPO_3oaGeFdg
元数据表保证 ACID 事务更新。对数据表的所有更改都将转换为提交到元数据表的元数据记录,这样每次对 Hudi 表的写入只有在数据表和元数据表都提交时才能成功。多表事务确保原子性并且对故障具有弹性,因此对数据或元数据表的部分写入永远不会暴露给其他读取或写入事务。
 微信
微信 支付宝
支付宝