











最新
数据湖-Iceberg-源码学习-云原生-Kubernetes
一、概述
https://www.cnblogs.com/tencent-cloud-native/p/13938298.html
二、设计

数据湖-Iceberg-源码学习-Kernel-Table Format-FileLayouts-优化-小文件
一、概述Iceberg 每次快照都产生了大量的文件。包括 Manifest 文件和数据文件 DataFile,以及快照文件和上述这些文件的校验文件。当存在删除更新操作,Manifest 文件和数据文件又拆分出来删除类型的对应文件 DeleteFile,当快照执行场率过高且每次操作数据量较小时,会产生大量的小文件,从而导致系统性能减弱,为解决这类问题,Iceberg 也提供了相应的文件合并、重写等操作来减轻这类问题。
二、设计
https://blog.csdn.net/naisongwen
http://www.360doc.com/content/22/0214/16/76878877_1017395542.shtml
2.1. 文件重写图中在两个事务(snap-1 和 snap-2 )中分别增加 1 条记录,生成 2 个 manifest 文件和 2 个 datafile 文件,希望这两条记录位于同一个文件,此时需要在 snap-3 中将数据文件 datafile-1 和 datafile-2 删除,为了能够保证之前的快照数据不被破坏,在 snap-3 中增加指向这两个文件的 ...

数据湖-Iceberg-源码学习-Query Engines-Flink
一、概述Iceberg 的架构和实现并未绑定于某一特定引擎,它实现了通用的数据组织格式,利用此格式可以方便地与不同引擎(如Flink、Hive、Spark)对接。Flink 和 Iceberg 的集成可以提供更好的数据管理和分析功能,可以更好地管理和分析大型数据集。
https://mp.weixin.qq.com/s/jIcQbpj1OtQ71m6YFCItng
https://blog.csdn.net/yiweiyi329/article/details/121842572
https://juejin.cn/post/6961912479215517703
二、读数据
引用本站文章
数据湖-Iceberg-源码学习-Query Engines-Flink-读数据
Joker
三、写数据IcebergTableSink 可以将数据写入 ...

数据湖-Iceberg-源码学习-Kernal-Table-FileIO
FileIO 是 Iceberg 库和底层存储之间的主要接口,与 Hive 等组件不同的是,Iceberg 不引用目录,它追踪了表在文件级别的完整状态,通过 FileIO 可以从最顶层的元数据直达底层存储。
二、设计2.1. 云原生 I/O 架构Iceberg 之所以可以利用像 FileIO 这样的简洁接口,是因为所有的位置信息在元数据结构中都是显式的、不可变的和绝对的。Iceberg 不引用目录,它从文件级别跟踪了表的完整状态。因此,从元数据层次结构的最顶层,可以直达任何存储位置,而无需进行 $File\ Listing$ 操作。同样,提交动作是向元数据树添加一个完全可访问且不需要重命名操作的新分支。
Iceberg 和 Hudi 最大区别:
Hudi 本身是要强化 Hadoop 的能力,而 Iceberg 是要绕开 Hadoop 拥抱云。
在文件级别跟踪数据还允许 Iceberg 完全抽象物理布局。分区信息以文件级别存储在元数据中,因此物理位置完全独立于逻辑结构。这种分离机制可以通过底层数据的转换支持隐藏分区。元数据操作在计划和提交阶段执行,其中读取和写入元数据文件(me ...

数据湖-Iceberg-源码学习-Kernal-Table-数据操作-删除
一、概述Iceberg 中删除操作通常分为两个步骤: 删除表的数据和元数据。
删除表的数据
Iceberg 删除表的数据文件使用 DeleteFiles 类,它提供了一组方法用于删除表中的数据文件。
删除表的元数据
删除表的元数据通过 Catalog 类实现, Catalog 提供了一组方法用于删除 Iceberg 表和相关元数据
二、设计在 v0.10.0 之后,Iceberg 除了存储数据的文件 DataFile 以外,还引入了一种新的文件 DeleteFile。
DeleteFile 里面保存的是 “哪一条数据被删除” 的记录。当 Iceberg 提交一次写入(也就是创建一个新的 snapshot) 时,如果这次写入操作里删除了过去的某条记录,Iceberg 并不会直接删除 DataFile 里面的数据。
在 HDFS 和对象存储上,无法修改一个已经存在的文件
所以 Iceberg 把这条记录的 id 写入一个 DeleteFile 里面。这个 DeleteFile 也是创建出的 snapshot 的一部分,被记录在 snapshot 的文件列表里面。
Icebe ...
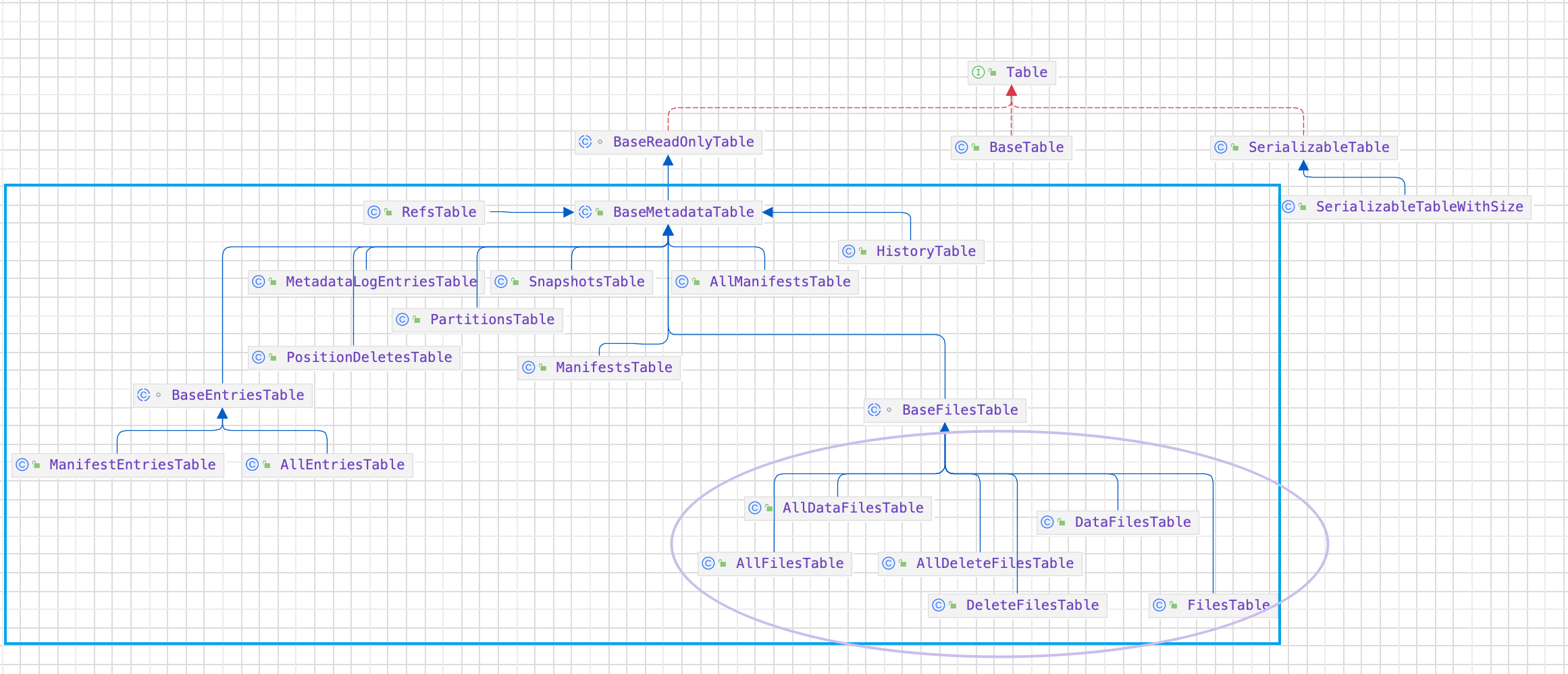
数据湖-Iceberg-源码学习-Kernal-Table-时间旅行
一、概述二、设计

Spark 系列
一、概述Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是 加州大学伯克利分校的 AMP 实验室开源的类 Hadoop MapReduce 的通用并行框架。
二、理论笔记
引用本站文章
Spark-理论笔记系列
Joker
三、源码学习
引用本站文章
Spark-源码学习系列
Joker
四、大厂分享
引用本站文章
Spark-发展-大厂分享系列
...
数据湖-Iceberg-源码学习-Kernel-Table-数据操作
一、概述
二、设计2.1. 查询Table 接口里提供了数据查询的相应的方法:
2.2. 插入Table 接口里提供了数据查询的相应的方法: $newFastAppend$ 方法 和 $newAppend$ 方法。
$newFastAppend$ 方法会避免一些额外工作,加速 commit 的过程,但如果过多使用,可能造成 split 规划过程缦慢。
那么什么是额外的工作呢?🤔️
在 Iceberg 对 AppendFiles 的两个实现类 FastAppend\MergeAppend 中可以分析出,这些过程主要是 manifest 文件合并等操作,它会减少元数据的文件数量,提升扫描查询规划的速度。
2.2.1. newAppend()2.2.2. newFastAppend()2.3. 更新Table 接口里提供了数据更新的相应的方法:
2.4. 删除Table 接口里提供了数据更新的相应的方法: $newDelete$ 方法。
1DeleteFiles newDelete();

数据湖-Iceberg-源码学习-Kernel-Table-元数据变更
一、概述TableMetadata 表示一张 Table 的元数据,Table 通过 TableOperations 和 Catalog 进行交互,查找和保存这些元数据。
二、设计Iceberg 是一种 Table Format, Table 是 Iceberg 的核心概念,由 Schema,分区信息,文件存储路径,文件存储格式,properties 属性,统计信息等。这些信息统称为 metadata, Iceberg 提供 metadata 的抽象,由类 org.apache.iceberg.TableMetadata 表示。
Table 为了查找元数据需要和 Catalog 进行交互,与 Catalog 的交互操作由 TableOperations 来完成。每个 Catalog 都有自己的 TableOperations 实现。
核心的方法主要有:
$current$ 方法通过 Catalog API 加载出当前表的 metadata 数据
$commit$ 方法数据写入完成后提交当前表,也就是生成一个 snapshot
$io$ 方法表示当前表的底层存储介质,比 ...
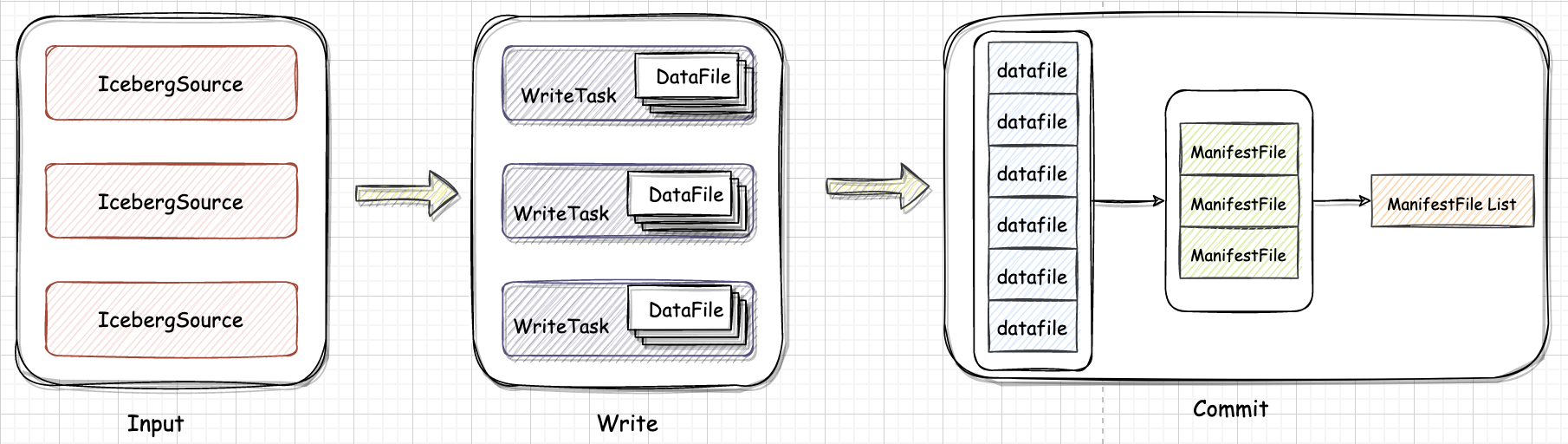
数据湖-Iceberg-源码学习-Query Engines-Spark-写数据
https://mp.weixin.qq.com/s/1BOcvD5m-7sFXtKPJnT7hg
一、概述Iceberg 定位是计算引擎之下,存储之上的开放表格式 Table Format,总体上 Spark 写入 Iceberg 可以分为两步: Spark 从 数据源读取 Source 数据,切分成多个 Task,每个 Task 会根据设置生成一个或者多个 DataFile;
Task 的返回结果就是一个或者多个 DataFile 结构。
Spark Driver 在收集到所有的 DataFile 后,首先将多个 DataFile 结构写入到一个 ManiestFile 里,然后生成一个由多个 ManifestFile 组成的 Snapshot 并 Commit 到 Catalog。
数据写入 Write
Spark 引擎层调用接口将数据往下发,Iceberg 接受数据,将数据按照指定的格式写入对应的存储中。
数据提交 Commit
Spark 数据写入完成时,Iceberg 按照自己的表规范生成对应的元数据文件。
二、Spark 引擎层和 Iceberg 对 ...
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.










